Выбираем структуру DS-отдела
Выбираем структуру DS-отдела
Прочитал white paper Practical Guide to Managing Data Science at Scale. Не скажу, что узнал много нового из самой статьи, да и материал больше нацелен на DS-проекты внутри больших компаний, а у нас основным продуктом являются именно DL-системы. Тем не менее, чтиво оказалось не бесполезное, например, у меня глаз зацепился за раздел Organizational Design, где обсуждается уже традиционный холивар “централизованный DS-отдел” vs “децентрализованные дэйта-саентисты в продуктовых командах или бизнес-юнитах”.
У нас в компании как раз недавно начался новый виток обсуждений о том, не стоит ли нам уйти в какую-то децентрализованную матричную структуру. Сейчас у нас 5 DL-продуктов, при этом DS-команды по каждому направлению сидят вместе в одном в офисе (не-DS разбросаны по городам и работают удалённо), находятся под моим руководством и вообще сильно связаны общим тулингом, культурой, эвентами. Я сначала сильно набычился (видимо, угрозу почувствовал 😄) и стал убеждать сам себя и окружающих, что в нашей ситуации (сильная ML/DL рисёч-составляющая во всех продуктах, медицинский домен с его особенностями, небыстрый цикл поставки, редко появляются новые проекты, сложилась особая культура в ML-отделе и прочее) уход от центализованной модели не нужен и даже вреден.
Какие вообщие плюсы у децентрализованного и централизованного подходов? В этой статье как раз приводятся некоторых из них. Главные плюсы централизации - создание сообщества DS-спецов и шаринг знаний, а минус - больше рисков, что модельки в итоге не будут использоваться из-за разрыва между ML и бизнесом. В децентрализованной модели MLщики глубже понимают бизнес-процессы и приоритеты, но становится тяжелее внедрять бест-практисы в ML-разработке и шарить тех знания по всей организации.
Главная мысль, которая меня и заставила написать этот пост - зачем холиварить, если можно брать лучшее из обоих миров (с уклоном в ту или иную сторону в зависимости от этапа развития компании и её специфики)? Централизованный ML-центр по мере развития может эволюционирать в гибридную структуру, которая называется Hub&Spoke (что-то типа “центр-спицы”), которую я решил изучить подробнее. В такой модели есть центральный “хаб”, который отвечает за внедрение бест-практисов и шаблонов для ускорения DS-разработки (документация, проджект-темплейты, процессы, общий тулинг), монторинг DS-разработки, распределение специалистов по продуктовым командам, организацию общих мероприятий, процесс найма. А от этого хаба отходят “спицы”, которые сильно связаны с общим центром, но при этом внедрены в конкретные бизнес-юниты или продуктовые команды.
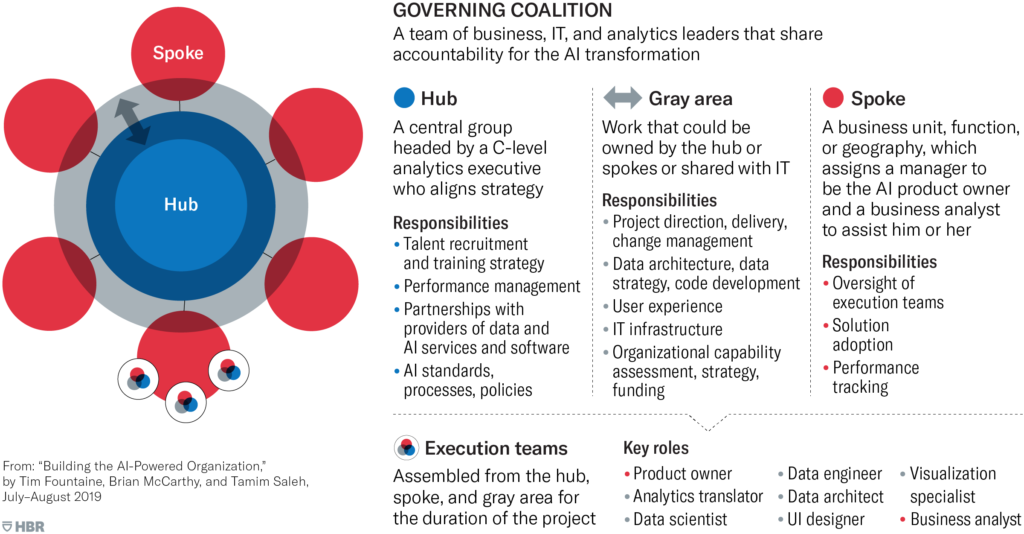
Hub&Spoke-модель
Чутка пораскинув мозгами, я понял, что мы по факту уже находимся в такой гибридной модели. С одной стороны у нас есть общее пространство MLщиков (виртуальное в Mattermost, офлайновое в офисе), разные мероприятия по шарингу знаний, зарождающийся “хаб” (в нём как раз и находятся оба автора этого канала - я отвечаю за бест-практисы, процессы и общий тулинг, а #Миша - за распространение ML-знаний). С другой стороны у каждой команды есть свои процессы и свобода в выборе инструментов, отдельные планёрки с бизнесом и продактами, своя коммуникация с дата-командой и бэком.
Кому-то такая модель напомнит модель Spotify с гильдиями, кому-то дата-продуктовые команды из доклада Асхата). Лично мне модель со спицами понравилась из-за её гибкости. Каждая компания в зависимости от ситуации может выбирать:
- какая “длина” должна быть у этих спиц - то есть, насколько та или иная команда ближе к ML-хабу или к бизнесу
- у спиц могут в какой-то момент появляться свои спички (поддомены или подпродукты)
- размер “серой зоны” и состав execution teams (см. картинку) - какая ответственность ложится на хаб, какая на спицы, а какая шарится между ними
Совет как всегда примерно один и тот же - проанализируйте текущую DS-структуру, как и почему она появилась, соответствует ли она текущей ситуации или нужны какие-то перемены. Короче, осознанный подход и своевременная реакция на изменения =)