jax: почему это круто и почему он вам (скорее всего) не нужен
jax: почему это круто и почему он вам (скорее всего) не нужен
Миша
Как читать этот пост?
- Если вы уже знаете что такое jax и haiku /flax /optax - можно сразу прыгать до секции “почему плохо для продакшена”.
- Если интересно про опыт использования библиотек, то в секцию “про опыт использования”.
- Если хочется TL;DR, то **
jax** быстрый, на нём приятно писать, у него круто хэндлится рандом, но в нём легко набаговать, если вы не сталкивались с jit-компиляцией и функциональными языками. Если дать jax джуну, то он сможет найти миллион неожиданных способов выстрелить себе в ногу. Документация на чистый jax шикарная, но для библиотек, с которыми вам придётся работать, периодически надо будет смотреть в код (хотя, как правило, он легко читается). Местами сыровато.
Что это за зверь такой?
JAX - это библиотека для быстрых научных вычислений, по сути это numpy + autodiff + jit + vmap /pmap. Она использует более низкоуровневой пакет LAX, который, в свою очередь, небольшая обёртка над XLA. Поверх jax написали уже кучу библиотек для всего чего только можно: от моделирования взаимодействий частиц до монте-карло поиска по деревьям (на котором, кстати, основывается всё семейство Alpha-Zero). Нас, конечно же, больше всего интересуют библиотеки для DL.
Идея, экосистемы jax в том, чтобы сделать много узкоспециализированных библиотек, так optax поставляет оптимайзеры, для нейронок есть objax /haiku /flax /…, для юнит-тестов есть chex и так далее.
Разбираем jax на кусочки
jax.numpy
Практически inplace замена для numpy, которая может работать на графическом ускорителе. Но есть некоторые особенности. Массивы подразумеваются неизменяемыми. Как говорит официальная документация:

Смысл такого поведения в том, что jax под капотом компилирует код для запуска на GPU, а инплейс-операции затрудняют анализ кода. Это неудобно, но только первое время.
Что бесит ощутимо сильнее, так это то, что не все операции работающие на CPU, работают на GPU (хотя нам и обещают, что один и тот же код должен работать и там, и там). Может быть я один такой невезучий, но наткнулся на сразу две штуки: разложение Шура и спектральное разложение несимметричной матрицы. У большинства использующих как будто бы всё действительно хорошо и никто не жалуется. Ну и ладно, некоторые разложения матриц действительно плохо дружат с GPU (хотя мне бы всё равно хотелось получать варнинг и медленную скорость работы, а не падение с ошибкой).
При это всё же надо быть честным: благодаря дактайпингу большинство библиотек не замечают подмену нампая на джакс-версию и продолжают работать как надо.
random
Он тут другой. В обычном нампае ты делаешь random.seed(24) и он сам хэндлит стейт генератора псевдорандома, а в jax стейтом нужно оперировать явно. Сначала стейт создаётся через state = jax.random.PRNGKey(24), а потом каждый раз когда хочется сгенерировать псевдослучайное число надо сказать state, key = jax.random.split(state) и использовать key для генерации: jax.random.normal(key=key).
Сначала не понял зачем by design заставлять людей писать лишние строчки кода, но в итоге влюбился в эту идею. Почему? Всё очень просто: программы всегда выполняются единообразно. Не бывает такого, что какой-то левый код сгенерил себе кусок рандома через нампай (и неявно обновил стейт генератора), а у тебя пропала воспроизводимость. В итоге это сильно экономит время и нервы. Лайк.
autodiff
Тут он совсем уж интересный и необычный: во-первых, ничего не происходит под капотом: ты берёшь обычную пайтон-функцию f, явно говоришь jax.grad(f) и оно выплёвывает тебе пайтон-функцию в ответ, которая принимает такие же аргументы как и оригинальная f, но выдаёт градиенты.
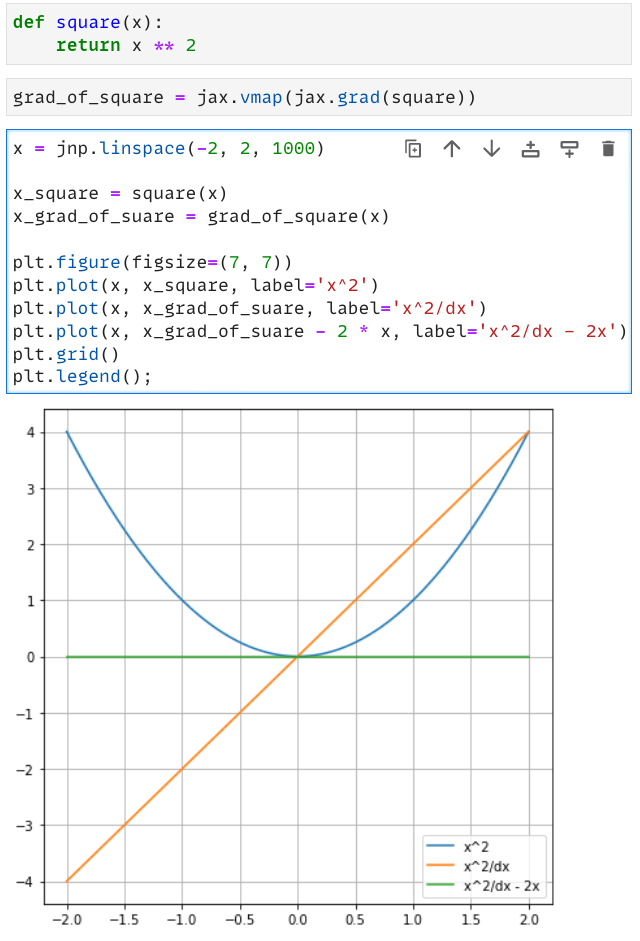
И это действительно полноценная пайтон-функция:
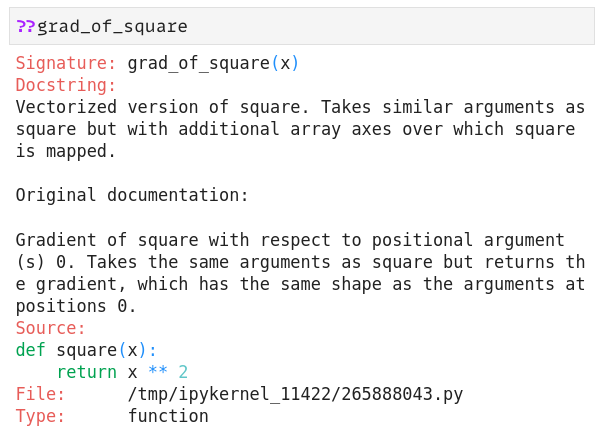
Тут уже стоит быть аккуратным и знать какие функции можно дифференцировать, потому что выстрелить в ногу вам вполне себе дадут:

Кроме того, можно указать по каким параметрам этот градиент будет браться.
jit
Да, это просто just-in-time компиляция. Да, это прекрасная возможность сделать баг. Или два. Или сто. Ускоряет ли это питон-функции? Да, вполне:

переписывать документацию не буду, подробности можно прочитать тут и здесь.
vmap и pmap
Как вы уже могли заметить, я использовал vmap : дело в том, что jax.grad на самом деле работает только со скалярами. vmap - это такая прекрасная штука, которая добавляет дополнительное измерение, по которому и происходит параллелизация. Опять же: кушает пайтон-функцию и выплёвывает пайтон-функцию. pmap - это такая же магия, но для параллелизации по девайсам.
То есть если у вас есть кластер, в котором вы хотите считать градиент функции f по батчам, то вам нужно только написать pmap(vmap(grad(f)) и оно будет работать о__о Можно ещё и в jit всё это обернуть и будет совсем красота.
Клёвый блогпост про то как считать линейную регрессию на кластере прилагается.
Про опыт использования
Я использовал чистый jax , haiku , flax , optax. Каждую из них я использовал по несколько недель, хоть и не каждый день, но для того, чтобы освоиться и составить мнение времени хватило. Давайте по порядку.
чистый jax
Может быть я люблю странные штуки, но мне больше всего понравился именно этот вариант.
Первое, что я написал - поиск стационарного распределения в марковской цепи двумя способами: возведением в степень транзишн-матрицы и вычислением собственных значений.
Сразу бросилось в глаза следующее: jit работает как надо, jnp.linalg.eig падает. Meh. Действительно, не все современные алгоритмы для разложения матриц хорошо работают на видеокартах, но как будто бы существуют специальные альтернативы. jax самостоятельно выбирает бэкенд, поэтому для подсчёта пришлось использовать jax.device_put(matrix, jax.devices("cpu")[0]). С перемножением матриц проблем не возникло.
Поигрался с разными репозиториями из awesome-jax, мне понравилось, всё работает прекрасно. Написал двухслойную свёрточную сетку с инициализацией через фильтры Габора. jax.scipy.signal.convolve2d выдаёт странную ошибку, гуглится и фиксится установкой переменной XLA_PYTHON_CLIENT_MEM_FRACTION= 0.87. Но такая 101-сетка работает очень быстро, это приятно.

ну и ладно, главное, что работает
Программирование на jax -е достаточно похоже на функциональные языки, поэтому для нужно писать чистые функции, то есть без I/O и детерминированные.
Первое время стоит поглядывать на sharp bits - шикарная часть документации про то, что может пойти не так.
Ну и пусть тут ещё будет ссылочка на полезную серию видосов.
haiku
Посмторев несколько видосов и блогов, я решил, что haiku для написания сеток самая приятная библиотечка, даже несмотря на то, что комьюнити меньше. Она очень похожа на пайторч, но со своими jax-штуками. Для того чтобы сетки были стейтфул, нужно использовать всякие hk.get_params и hk.get_state. Это некрасиво, но это делает код пайторчёвым.
Попробовал написать свой ResNeSt. Так как я обожаю einops, использовал и её.
Пришлось один раз залезть в сорцы, потому что мне не совсем очевидно было что делает haiku с GroupNorm. Оказывается, что в отличие от батчнорма EMA статистики по параметрам надо делать ручками. Неприятно, но по сути +1 строка кода.
Кстати про EMA, можно безболезненно обернуть все параметры модельки с помощью этого, красиво.
В целом, писать на haiku нормально. Но после того как ты увидел, что всё может быть функционально, тебе не хочется пайторч-лайк стиля кода. Пропадает изюминка jax -а.
flax
Вот тут у меня пригорело. Это просто неудобно. Я попробовал писать с помощью flax и ощущения, как будто сделали слишком уж высокоуровневые абстракции. Да, код MLP-Mixer выглядит красиво:
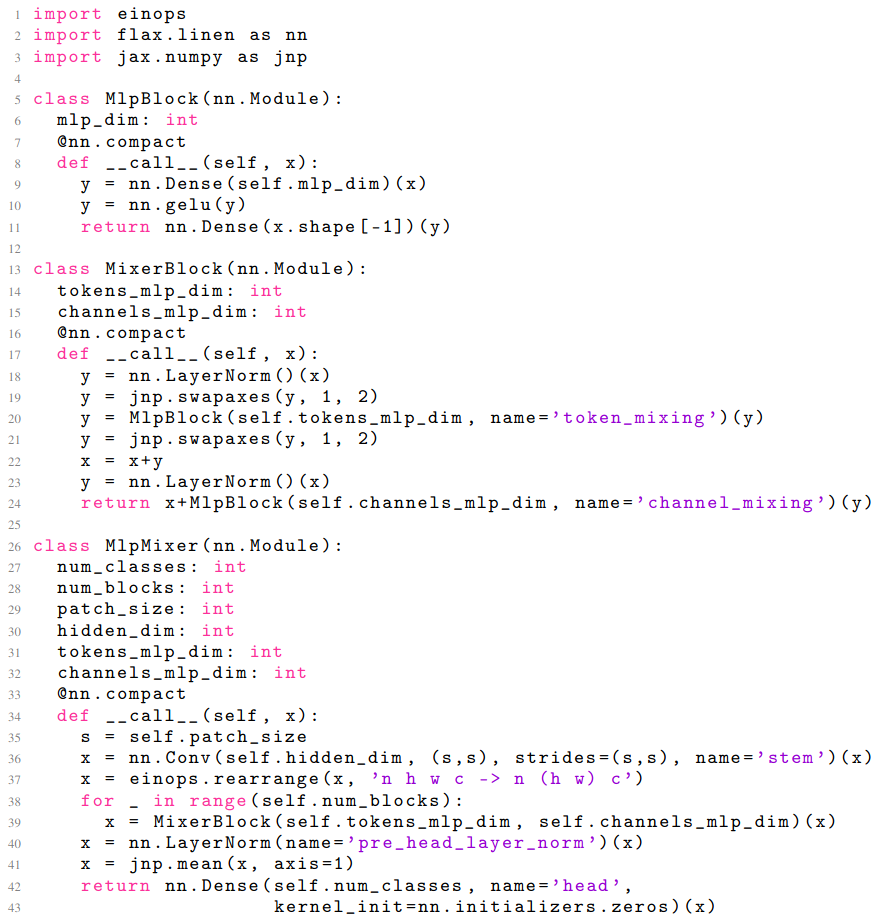
но до того как он заработает, вам придётся страдать. Коммент с реддита, с которым я согласен.
optax
Очень приятная библиотека. Работает с другими из экосистемы, делает то что и должна. Использовал и с читсым jax , и с haiku , и с flax. Каждый раз работало без нареканий.
Почему плохо для продакшена
Как же так? Почему плохо? Модельки ведь быстрые, гугл библиотеку поддерживает и активно развивает. Опять же в гугле вроде активно используют.
Но мне всё-таки кажется, что в продакшн тащить не стоит по двум основным причинам:
- Классические проблемы для молодой библиотеки: маленькое комьюнити и местами сыроватый код.
- Не для новичков.
Немножко про каждый пункт.
Маленькое комьюнити и сырой код
Ну ладно, про маленькое комьюнити я может быть и приукрасил, но если сравнить с пайторчем или, прости хоспаде, тензорфлоу, то маленькое.
Иногда ответов на ваши вопросы не будет ни в гугле, ни в ишью гитхаба. Да, можно создать ишью самому и его даже закроют достаточно быстро, но как правило просто придётся много думать. Это не плохо, но это не для продакшена.
Про сырой код: наверное, пока вы читали статью, вы заметили, что тут и там всплывают странные багулины. В библиотеках, которые вы будете использовать поверх jax -а эти баги могут быть никем не описаны и исправлять их будет больно.
Эти проблемы даже не столько jax -а, сколько вообще любой молодой библиотеки, но они есть и с этим приходится жить.
Не для новичков
Sharp bits в документации существует далеко не просто так.
Дебаг удобнее, чем в tf 1.x, особенно благодаря make_jaxpr, но всё-таки в отличие от пайторча всё компилируется для работы с XLA и это не нативный питон.
Приходится держать в голове где у тебя DeviceArray, где у тебя измерение по которому параллелизуется функция, что там за jacfwd и jacrev, где jit развернёт цикл, а тебе этого не нужно, где нужная библиотека для того, чтобы сделать X.
Почему всё-таки круто
Хотя бы потому что сетки в функциональном виде - это прекрасно. Но вообще jax быстрый, лёгкий (это очень приятно, если вы обёртываете модель в докер), с помощью него удобно делать металёрнинг, он шикарно работает на TPU (кто бы сомневался), а это значит, что коллаб теперь куда более мощный, с помощью него легче экспериментировать над низкоуровневыми вещами, чем в пайторче.