Google Docs
Все DETRы мира
Жека Никитин (Цельс)
Для ТГ-канала “Варим ML”
Я - большой фанат задачи детекции, она мне нравится по всем критериям. Она самая интересная концептуально - одновременно нужно и искать объекты, и определять их тип. Классификация целых изображений скучновата и не так часто применима на практике (по крайней мере в медицине), а сегментация мне кажется нудноватой - ну их, эти конкретные пиксели. Ещё статьи про детекцию - самые интересные для меня в техническом плане. Мне нравится разбираться в разных видах архитектур - anchor-based и anchor-free, one-stage и multi-stage, а ещё я очень люблю разные крутые идеи, которые улучшают тот или иной компонент детекционного пайплайна - например, PISA для умного взвешивания разных сэмплов в лоссе, Precise RoIPooling и Deformable RoIPooling для более точного и хитрого пулинга фичей, D2Det для декаплинга задач локализации и классификации, SoftNMS для замены традиционного NMS.
В 2020 году вышла крутая статья про новую архитектуру для детекции - DETR. Она меня очень вдохновила, и я тут же бросился впиливать её в проект Маммография (ММГ), тем более что код был с виду очень простой. После недели мучений я не смог выжать ничего адекватного - обучалось ужасно, долго и предиктило в основном фигню. Возможно, я где-то набаговал, но возиться дольше не хотелось.
Тем не менее, все три года идея всё-таки впилить DETR преследовала меня по пятам, тем более что за это время вышло несколько десятков статей, тем или иным образом улучшающим оригинальную архитектуру. И вот, в один прекрасный день я зачем-то решил прочитать вообще все статьи про DETRы, а заодно попробовать несколько вариаций в ММГ. Задача оказалась слегка сложнее, чем я ожидал…
Но я решил сдержать пацанское слово - и прочитал все статьи по DETR, которые смог найти, и большую часть из них даже смог понять.
Важное примечание - в этот гайд включены только статьи, которые решают задачу классической 2D-детекции. Никаких semi-supervised, 3D и так далее. Если захотите сделаю по ним отдельный пост… А во второй части (выйдет позже, если к этой статье будет хоть какой-то интерес) расскажу про свои эксперименты, покажу иллюстрации и порассуждаю про разные компоненты архитектуры.
Я постарался сделать описания в гайде более интуитивными и менее опирающимися на формулы, а также оставить побольше ссылок на конкретные места в коде разных архитектур. Если вам захочется копнуть в какую-то модификацию глубже, верхнеуровневое интуитивное понимание идеи поможет сделать это быстрее и легче.
Содержание гайда:
Все DETRы мира 1
Начало 3
DETR Original (2020) 3
Back to anchors 9
Deformable DETR (2020) 10
Dynamic DETR (2021) 12
Anchor DETR (2021) 15
Conditional DETR (2021) и Conditional DETRv2 (2022) 16
DAB DETR (2022) 19
DETR SMCA (2021) 20
Efficient DETR (2021) 22
Team DETR (2023) 24
AdaMixer (2022) 26
Denoising queries 28
DN-DETR (2022) 28
DINO (2022) 30
DEYO (2022) 32
Exploiting positive anchors 33
H-Deformable-DETR (2022) 33
Group DETR (2022) и Group DETR v2 (2022) 34
Co-DETR (2022) 35
NMS Strikes Back (DETA) (2022) 36
Другие формулировки задачи 38
Pair DETR (2022) 38
SAM-DETR (2022) и SAM-DETR++ (2022) 39
SAP-DETR (2022) 41
Pretraining 44
UP-DETR (2020) 44
DETReg (2021) 45
Дистилляция 46
Teach-DETR (2022) 46
DETRDistill (2022) 47
D3ETR (2022) 49
KS DETR (2023) 50
С облегчением 51
Sparse DETR (2021) 51
PNP-DETR (2021) 52
L-DETR (2022) 53
Lite DETR (2023) 54
Архитектурные трюки 54
Miti-DETR (2021) 56
CF-DETR (2021) 58
DETR++ (2022) 59
Backpropagating through Hungarian (2022) 59
DESTR (2022) 60
Honorable mentions 61
What makes for end-to-end object detection? (2022) 61
AO2-DETR (2022) 61
Omni-DETR (2022) 62
Points as Queries (2021) 63
HOI Transformer (2021) 63
Если не хотите читать всё - рекомендую пробежаться по этим архитектурам - DETR, Deformable DETR, Conditional DETR, DAB DETR, DN-DETR, DINO, H-Deformable-DETR, Sparse DETR.
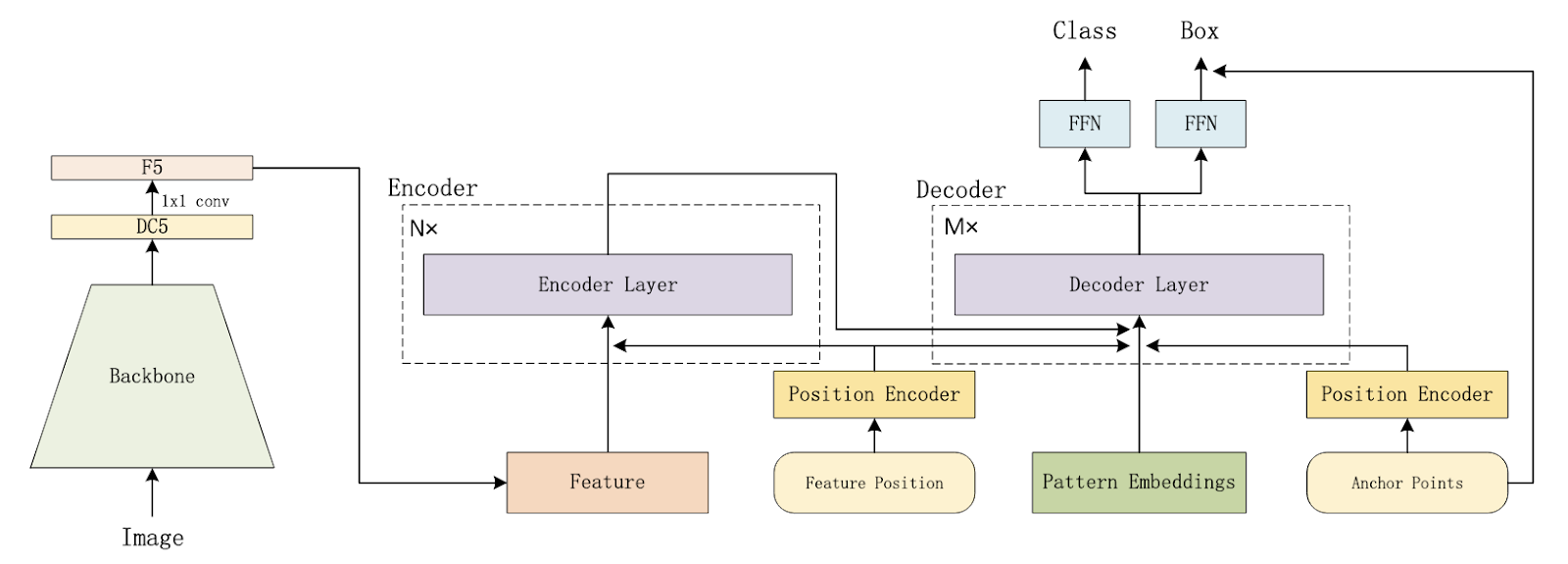
Начало
DETR Original (2020)
5682 цитирования, 10.8к звёздочек
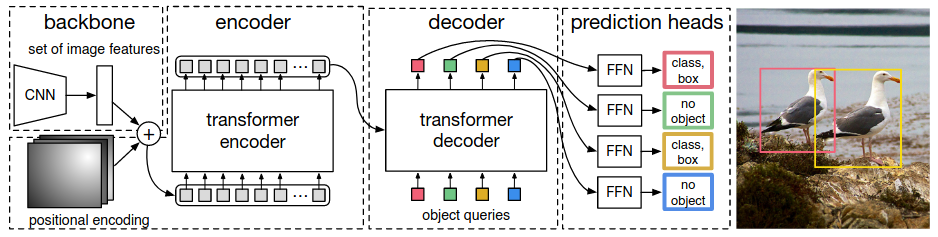
Давайте для начала разберёмся, какие преимущества имеет DETR перед классическими детекторами, а главное откуда они берутся? Начнём с краткого ревью самой архитектуры. Для совсем детального погружения можно также посмотреть вот такой видос от авторов статьи или пробежаться по Annotated DETR.
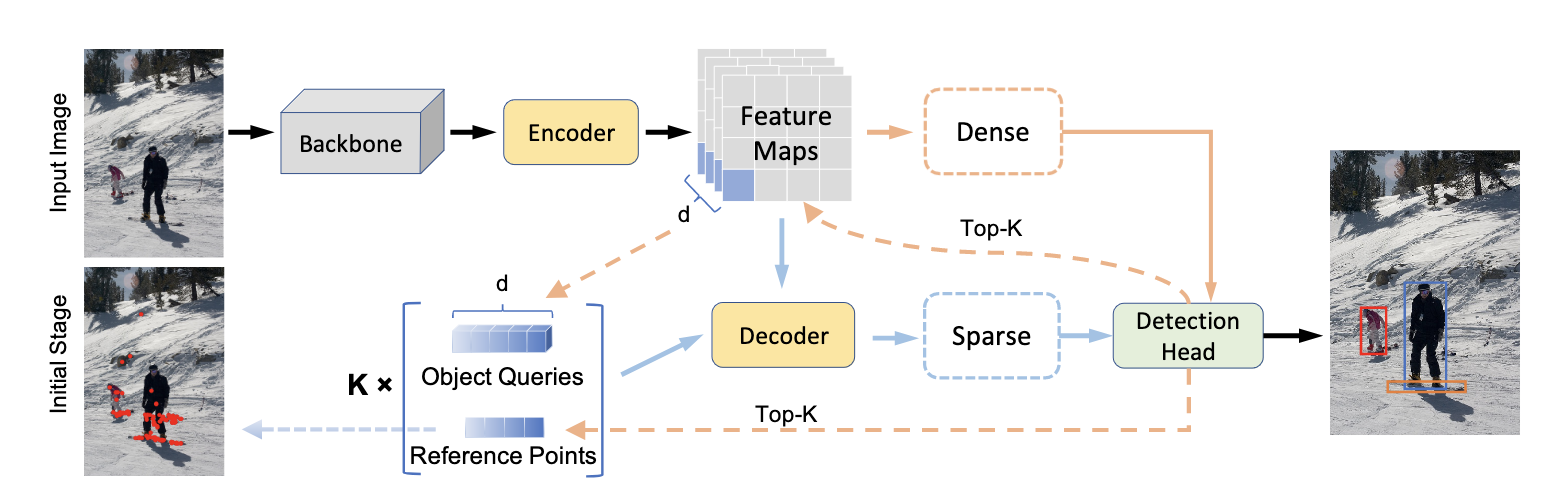
Как и в обычных детекторах, всё начинается с бэкбоуна, он может быть абсолютно любой - например, старый добрый ResNet-50. FPN и его аналоги в Детре не используются (хотя конечно же, есть и такие модификации).
CNN-фичи затем дополнительно обогащаются с помощью трансфомер-энкодера, который добавляет глобальный self-attention фичей друг на друга. Интуиция каждого слоя энкодера довольно простая - репрезентацию каждого “пикселя” (в дальнейшем “пиксель” в кавычках будет обозначать именно элемент фича-мапы, а не пиксель исходного изображения) мы обновляем с помощью информации с других релевантных “пикселей” изображения. Например, он может получить информацию от других частей того же самого объекта или от близлежащих областей, и эта информация впоследствии помогает более точной детекции.
Вообще говоря, это опциональная часть, ведь у нас уже есть CNN-фичи, но отсутствие энкодера согласно статье прилично ухудшает метрики. По логике авторов, self-attention позволяет лучше разделять объекты, особенно если они находятся близко друг к другу. Но есть варианты и без энкодера - например, в AdaMixer его убрали без потери качества.
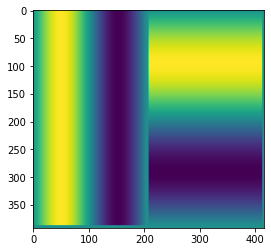
Трансформеры инвариативны к пермутациям входных 1D-токенов, а мы не хотим терять “географическую” информацию о фичах. Значит, нужно добавить к фичам энкодинг локации - чаще всего используется синусоидальный. На картинке в левой части изображён пример одного из каналов энкодинга прямоугольного ММГ-изображения по x, а в правой - по y. Таких каналов присоединяется много - с различными температурами. Во второй части статьи детальнее покажу, как они выглядят.
Ключевые отличия от обычных детекторов начинаются в декодере. DETR не использует классические геометрические энкоры, вместо них используются некие “object queries”, которые состоят из двух частей:
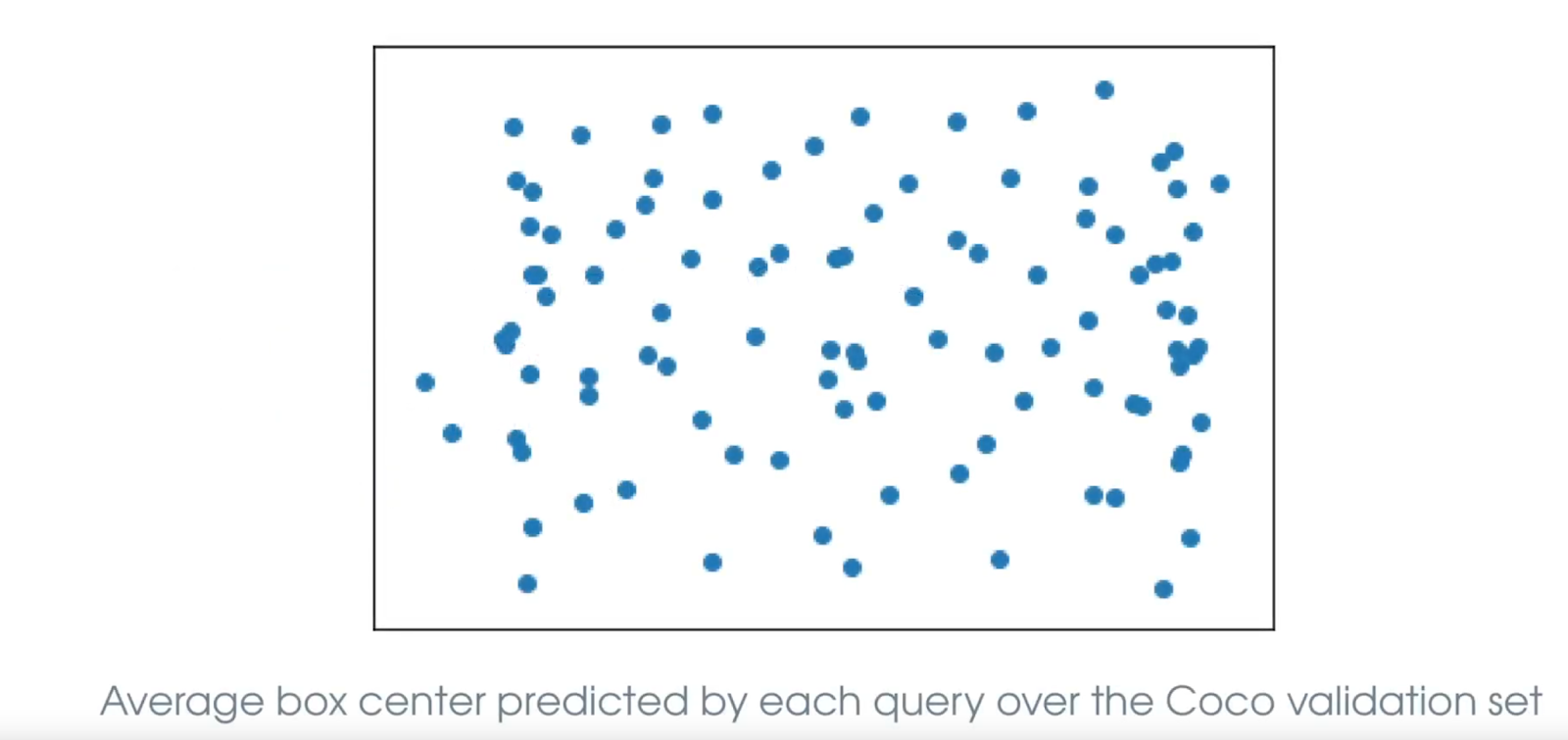
- Выучиваемые positional queries, которые отвечают за поиск объектов на разных частях изображения. В некотором смысле это гибкие выучиваемые энкоры, но прямой геометрической интерпретации DETR им не присваивает. На картинке (взята из доклада авторов DETR) каждая точка соответствует одному query. Видно, что средние предсказания каждого query довольно равномерно распределяются по изображению, так что они действительно по своей сути похожи на классические энкоры.
- Content queries, которые постепенно формируются в ходе декодинга и отвечают за сбор визуальной информации о текущем объекте интереса. Перед первым слоем инициализируются как нулевые векторы.
Две эти части суммируются для того, чтобы получить полную текущую репрезентацию object query - по сути текущего состояния разных объектов. Обычно их используют от 100 до 900 в зависимости от конкретной модификации архитектуры.
Давайте сразу определимся с терминологией, которая будет работать на протяжении всего этого поста. В разных статьях под одними и теми же терминами часто понимаются разные вещи, так что это важно.
- Когда я буду говорить об object query, речь будет идти о полной репрезентации каждого объекта - то есть, о сумме или конкатенации positional и content частей.
- Positional query или spatial query или box query - часть object query, которая отвечает за энкодинг пространственной информации. В ванильном DETR и в некоторых других статьях она выучивается отдельно для каждого query и подаётся в декодер один раз в неизменном виде. Во многих модификациях эта часть обретает прямую геометрическую интерпретацию и уточняется по ходу работы декодера - например, с помощью предсказания оффсета (об этом подробнее в следующем разделе).
- Если я буду упоминать content query, то это часть object query, которая обогащается визуальной информацией по ходу работы декодера. В оригинальном DETR инициализируется как нулевой вектор для каждого query перед первым слоём декодера. Именно по этим векторам предсказываются вероятности и координаты объектов, так что в коде их промежуточные и финальные состояния ещё называют decoder output или просто output.
- Когда мне нужно будет говорить о queries, keys и values в модулях этеншна, они будут по традиции называться Q, K и V.
Итак, вернёмся к архитектуре. Внутри каждого слоя декодера есть два вида внимания:
- Self-attention, который служит для обмена информации между этими самыми object queries. Раз это self-attention, то Q и K здесь одинаковые - это сумма content queries и positional queries. Для V positional-часть не добавляется - поскольку мы хотим обогатить инфой от других объектов только content-часть. Интересно, что self-attention на самом первом слое декодера бесполезен, ведь обмениваться ещё нечем (content-части нулевые), но его не убрали - то ли из лени, то ли чтоб не портить код.
- Cross-attention. В этой части object queries смотрят на результат работы бэкбоуна и трансформер-энкодера и поглощают визуальную информацию. В качестве Q в данном случае также выступает сумма positional queries и content queries, а вот K и V другие - аутпут энкодера с positional embedding и без него соответственно. Таким образом, каждый object query производит некий софт-пулинг релевантных визуальных фичей из тех или иных частей изображения. Можно сказать, что этот модуль заменяет традиционный RoIPooling, только объекты могут считывать информацию со всего изображения, а не только из ограниченной области.
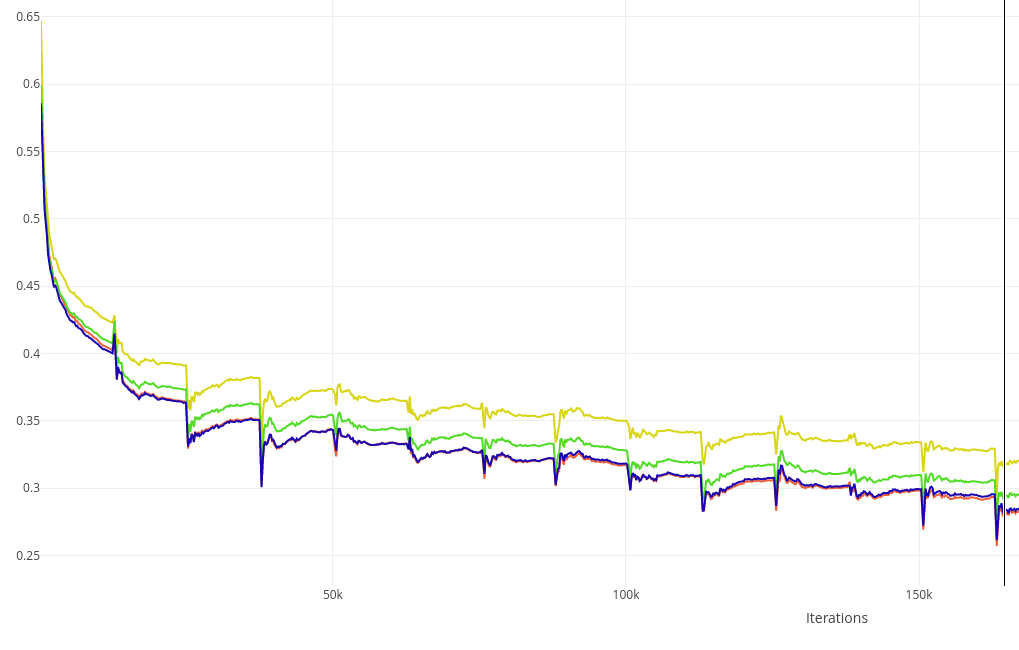
Основным аутпутом декодера являются преобразованные object queries, которые поступают в простенькую маленькую feed-forward network, которая генерит лоджиты классов и предсказанные координаты. Обычно такие предикты генерят после каждого слоя декодера и накладывают на них дополнительный лосс - это помогает стабилизировать и ускорить обучение. На графике ниже жёлтый, зелёный, синий и красный - это классификационный трейн-лосс по предсказаниям первого, второго, третьего и четвёртого слоёв декодера. Получается, что каждый следующий слой предсказывает объекты чуть точнее предыдущего, при этом выгода от каждого следующего слоя всё меньше и меньше.
Последняя магия кроется в расчёте лосса, а точнее в матчинге GT-объектов и предсказаний. Вместо использования эвристик для матчинга (например, на основе IoU или IoR) мы с помощью комбинаторной оптимизации находим лучший one-to-one матчинг, который даёт минимальный возможный суммарный лосс. Этот лосс, как и в обычных детекторах, складывается из суммы лоссов классификации и локализации. Конкретно используются кросс-энтропия, L1 и Generalized IoU. Количество предсказаний (равное количеству object queries) почти всегда будет больше, чем количество реальных GT-объектов на картинке, поэтому “лишние” предсказания отправляются в класс “no object” или по старинке “background”. Лучший матчинг ищется с помощью функции linear_sum_assignment из scipy, которой на вход подаются лоссы всех возможных сматченных пар. Внутри этой функции и реализован тот самый венгерский алгоритм, который упоминается во всех статьях про DETR. Хотя, если быть совсем точным, то в последних версиях scipy используется не сам венгерский алгоритм, а его более быстрая модификация.
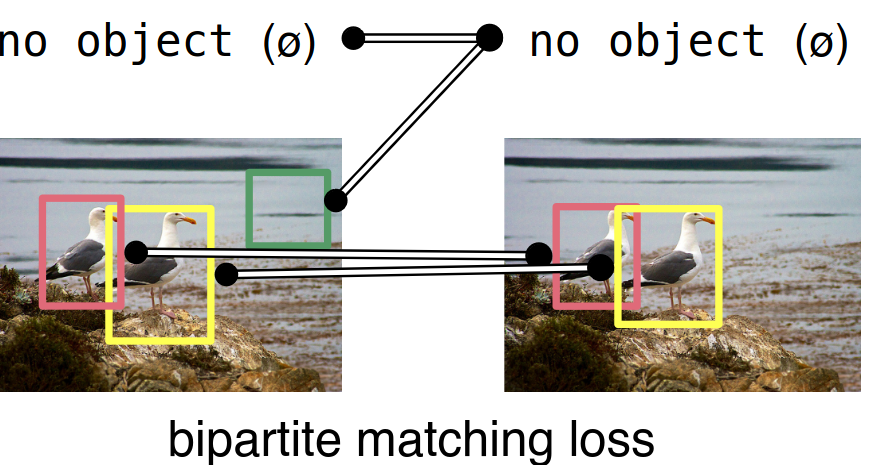
Итак, какие же преимущества даёт эта архитектура?
- Взаимодействие object queries через self-attention декодера вкупе с использованием matching loss теоретически приводят к отсутствию дубликатов предсказаний, а значит отпадает нужда в затратной и не всегда хорошо работающей процедуре Non-Maximum Suppression. Забегая вперёд - на нашей задаче дубликаты предсказаний у меня встречались, поэтому попробовать накинуть какой-нибудь NMS всё-таки стоит.
- Хотя self-attention изначально был задуман именно для дедубликации предиктов, он в теории также может моделировать отношения между объектами - например, если объекты двух классов почти всегда встречаются вместе, или присутствие одного объекта влияет на класс другого. К примеру, на маммограмах встречается признак “втяжение соска”, который сигнализирует о возможным наличии злокачественного процесса.
- Энкодер и cross-attention позволяют собирать визуальную информацию со всей картинки и прилично улучшают качество детекции больших объектов.
- Cross-attention использует слой MultiHeadAttention, что помогает разделять задачи локализации и классификации. Для предсказания координат нужны границы объекта, а для классификации - фокусировка на семантически важных частях. В классических детекторах decoupling этих задач часто докидывает (например, в упомянутой в начале архитектуре D2Det).
- Архитектура очень гибкая - например, кроме self-attention и cross-attention, мы можем добавить attention между разными картинками. Это может быть важно, если картинки связаны, что очень часто бывает в медицине. Например, часто мы имеем дело с разными проекциями одного и того же органа, снятыми под разными углами.
Раз поговорили о преимуществах, давайте сразу затронем и недостатки, ведь в дальнейшем речь пойдёт в основном о модификациях, которые их пытаются исправить.
- Плохое качество на маленьких объектах. DETR использует только один скейл из бэкбоуна, который может имеет слишком маленькое разрешение для точной детекции маленьких объектов. Почему бы не прикрутить FPN и использовать разрешение повыше или вообще всю пирамиду фичей? Ответ простой и грустный - операции self-attention в энкодере и cross-attention в декодере очень чувствительны к размерности фичей. Например, в энкодере каждый “пиксель” фиче-мапы может этендится к каждому другому пикселю, что создаёт квадратичную зависимость от размера фичей. В маммографии мы подаём в сетку исходное изображение размером примерно 2000 на 1000 пикселей, а некоторые важные объекты при этом имеют размер не больше 20-30 пикселей, так что по фича-мапам 80x40 маленькие объекты точно локализовать сложно.
- Очень долгие трейн-раны. Для достижения адекватных метрик DETRу нужно на порядок больше эпох, чем аналогичным классическим детекторам. В Цельсе мы и так обучаем сетки по несколько дней и даже недель, так что это критический недостаток.
Back to anchors
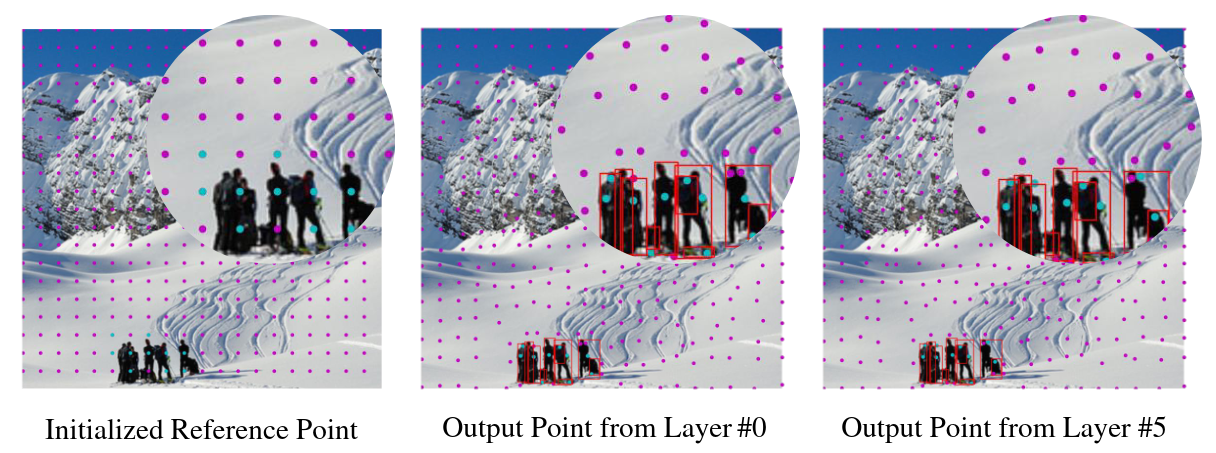
Одним из важных отличий Детра стал отказ от прямого использования геометрических priors - модель выучивала spatial queries прямо из данных. Увы, отсутствие прямой ассоциации между ними и конкретными локациями на изображении в итоге стало одной из причин медленного обучения сетки. Визуализация этеншн-мап разных object queries из cross-attention декодера (на картинке слева) показывает, что каждый query “смотрит” на обширную область, которая легко может содержать несколько объектов.

Целый ряд статей исследует разные формулировки positional-части object queries, которые позволяют им фокусироваться на конкретных частях изображения и ускорять обучение.
Deformable DETR (2020)
1932 цитирования, 2.2к звёздочек
Очень важная статья в мире DETRов, основная идея которой используется во многих последующих модификациях. Эта идея направлена на решение сразу обеих упомянутых выше проблем с помощью Deformable Attention.
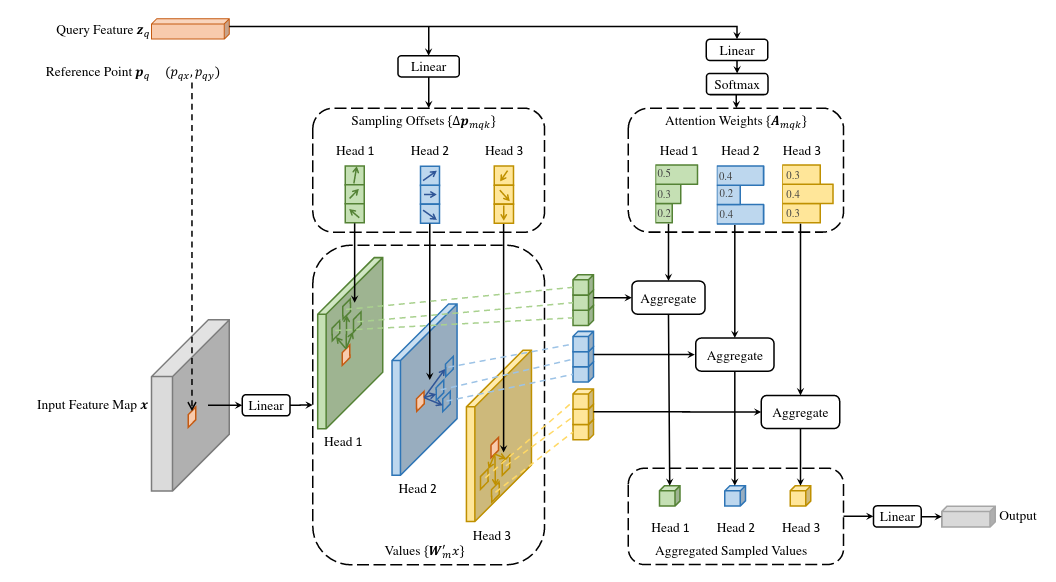
Ключевой вопрос - зачем нам собирать с помощью этеншна информацию со всех точек картинки? Скорее всего, каждому “пикселю” достаточно информации из своей окрестности и каких-то особенно важных точек из других мест картинки. Окей, давайте тогда разрешим этеншн только на фиксированное число точек - например, на четыре. Это сразу решает проблему квадратичной зависимости числа операций от размера картинки, превращая её в линейную. Как в энкодере и декодере выбирать эти точки?
- В энкодере по репрезентации каждого “пикселя” будем предсказывать sampling offsets - то есть, из каких локаций сэмплить фичи, на которые он будет обращать внимание. Причём для каждой attention-головы локации сделаем свои. Одна голова может обращать внимание на ближайшие локации, а другая - на области вокруг объекта. Эта идея может быть вам знакома по Deformable Convoluton. Более того, если для каждой attention-головы сэмплить ровно одну точку, то Deformable Attention по сути и сводится к Deformable Convolution.
- В декодере по каждому positional query (в коде разных DETRов эта часть в разных местах называется то query_embed, то query_pos) предсказывается reference point (по сути - центр энкора, соответствующего данному query), а по текущему состоянию object query - sampling offsets относительно этой точки референса. Из этих локаций (референс + оффсет) мы и будем сэмплить аутпут энкодера, релевантный для данного object query. Оффсет, естественно, предсказывается нецелочисленный, так что при сэмплинге используется функция grid_sample с билинейной интерполяцией.
Такая формулировка позволяет значительно снизить количество точек, для которых надо считать attention-веса. Это значит, что мы теперь можем собирать информацию сразу с нескольких уровней фиче-мап и не умирать от количества операций и требований к видеопамяти. Делается это несложно: мы просто суммируем информацию, полученную с разных уровней фиче-мап (и не забываем добавлять эмбеддинг уровня, ведь все фичи со всех уровней конкатятся в единый ряд токенов перед подачей в трансформер).
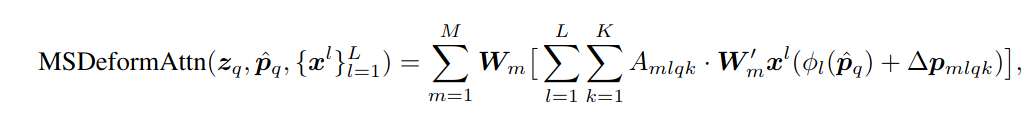
В статье предлагается ещё два важных механизма, которые тоже впоследствии будут использованы во многих модификациях:
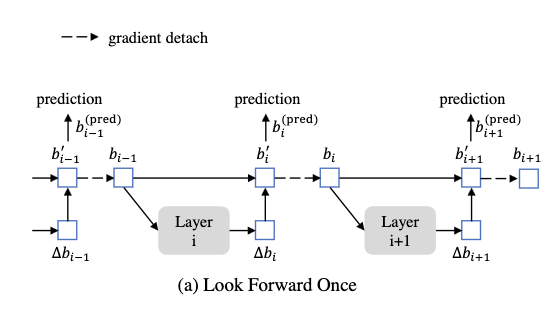
- Iterative Bounding Box Refinement. В ванильном Deformable DETR мы один раз перед декодером предсказываем референс-пойнты (две координаты) для каждого positional query. Есть идея получше - давайте перед первым слоем декодера предсказывать полноценный энкор (две координаты, ширина и высота коробки), а после каждого слоя его обновлять с помощью предсказанного оффсета. Таким образом, каждый следующий слой будет получать на вход всё более точный энкор. Предсказанные ширину и высоту также можно использовать, чтобы в cross-attention сэмплить точки, расположенные внутри бокса. Важная деталь - градиенту запрещается протекать от слоя i+1 к предыдущему через предсказанные коробки. Вместо этого градиент течёт только через промежуточные предсказания на каждом слое. Если непонятно - можно посмотреть на эту картинку, хотя, если честно, скорее всего, придётся копаться в коде, если хочется реально понять суть.
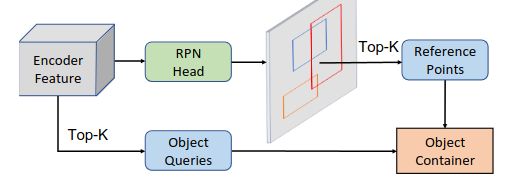
- Two-Stage. Ещё одна идея, отсылающая к классическим детекторам. Обучаемые positional queries никак не зависят от текущего изображения. Вместо них мы можем использовать фичи энкодера для предсказания хороших локаций, где, скорее всего, находятся объекты. В общем, эдакий Region Proposal Network, предсказывающий proposals. Каждый “пиксель” фичи-мап пытается предсказать какую-то коробку и класс - если ещё точнее, то оффсеты относительно базового энкора вот с фиксированным для уровня размером стороны. Чем больше по размеру фича-мапа, тем меньше размер базового энкора. На получившиеся предикты для дополнительной супервизии накладывается такой же матчинг-лосс, как и для всей сетки. А top-k предсказанных энкодером коробок берётся в качестве исходных референсов для декодера.
Важно отметить, что уже в этой статье мы по факту возвращаемся к геометрической интерпретации object queries как энкоров. При использовании Iterative Refinement мы на каждом слое декодера предсказываем оффсет нового предсказания относительно предыдущего (энкора). Очень похоже на какой-нибудь Cascade-RCNN, но без фиксированных энкоров.
Есть ещё пара технических изменений, которые наследуются всеми последователями. Первое - отказ от явного “background”-класса. Вместо этого background-таргеты теперь кодируются как вектор нулей в one-hot энкодинге, а на лоджиты накладывается сигмоида и бинарная кросс-энтропия. Второе - изначальные content queries теперь не инициализируются нулями, а тоже выучиваются.
Статья очень важная - замена классического DETR на Deformable отлично сочетается вместе с другими модификациями и стабильно поднимает метрики.
Dynamic DETR (2021)
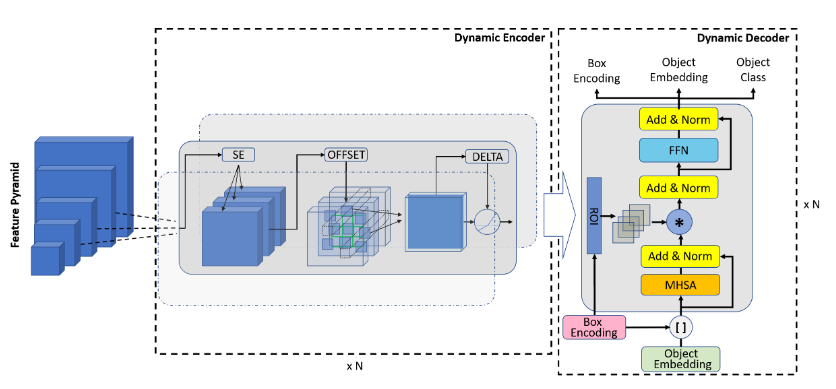
95 цитирований
Не самая популярная и интересная модификация, но раз уж взялся рассказать обо всех детрах…
Перед нами ещё одна попытка решить те же проблемы - плохую детекцию маленьких объектов и долгое неэффективное обучение. Как и в Deformable DETR, авторы задаются вопросом - как нам агрегировать фичи с разных скейлов и при этом не офигеть от вычислительных расходов? Предлагается две основных идеи. Первая - замена дорогого self-attention на ряд других операций, которые аппроксимируют этеншн на уровне пространства, скейлов и репрезентаций. Вторая - использование Box Encoding и RoI Pooling для ускорения обучения.
Начнём с трансформер-энкодера. Первая идея - давайте аппроксимировать дорогостояющую операцию attention с помощью конволюции. Для агрегации фичей с нескольких уровней апсэмплим результаты конволюции с предыдущего (меньшего по размеру) уровня и даунсэмплим результаты конволюции со следующего (большего) уровня:
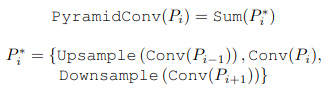
К сожалению, замена полноценного на self-attention на локальную конволюцию с маленьким kernel size в общем-то убивает всю суть трансформер-энкодера. Не проще ли при таких раскладах навесить на фичи какой-нибудь FPN? Но ребята не сдаются - и предлагают заменить обычную конволюцию на deformable, что позволит собирать информацию из разных регионов всех уровней фиче-мап. Важное замечание: оффсеты для deformable convolution предсказываются только один раз, для текущего центрального уровня, и переиспользуются для соседних. Это сделано, чтобы избежать ситуации, когда мы суммируем фичи разных уровней с абсолютно разных и несвязанных друг с другом локаций.

Окей, deformable convolution позволил нам получить некий пространственный этеншн, который ещё и собирает инфу с соседних уровней пирамиды фичей. Следующий этап - получить этеншн-веса для разных уровней новой пирамиды. Для этого используем нечто вроде Squeeze-and-Excitation. К сожалению, к этой статье нет ни приложений, ни кода, что затрудняет подробный анализ деталей имплементации. Наконец, последний “этеншн” выполняется с помощью Dynamic ReLU, интересной функции активации, которая может принимать различные формы в зависимости от входных данных:
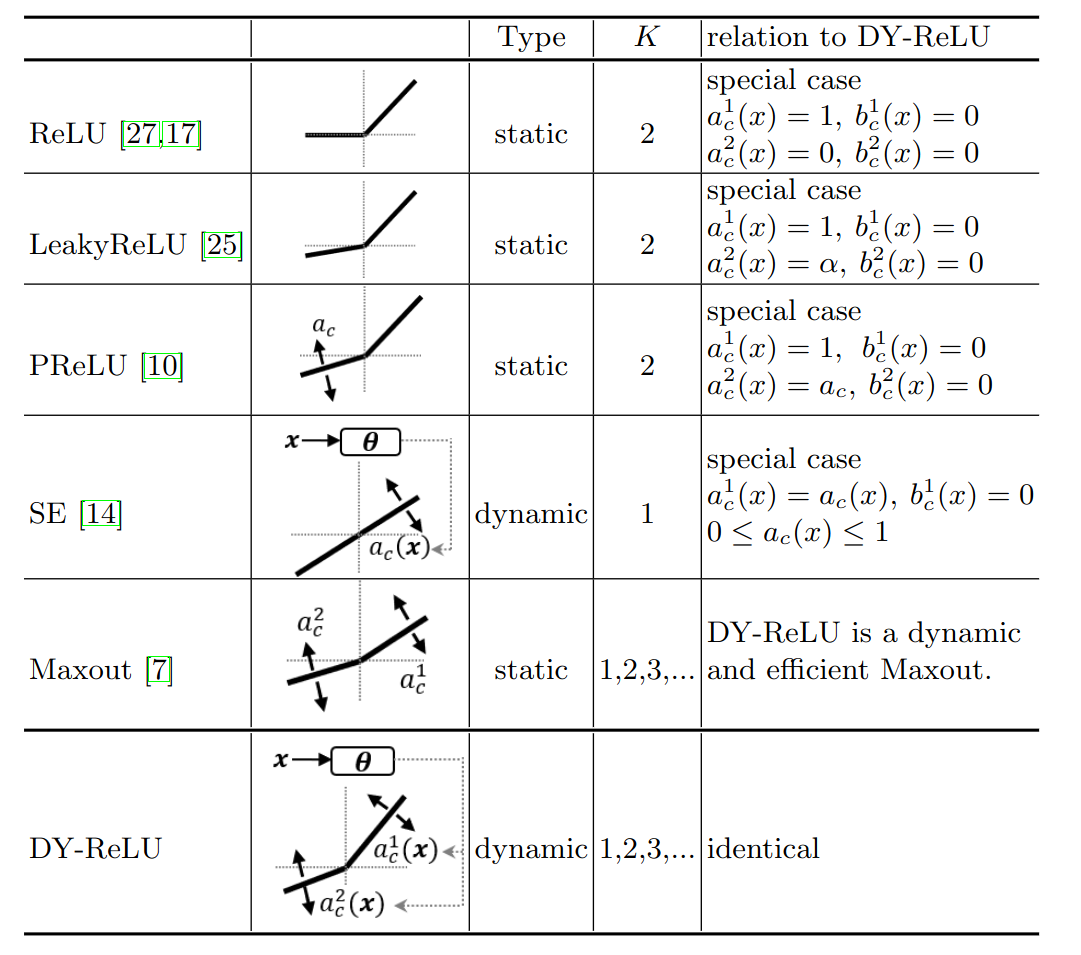
Причём параметры этих зависимостей могут шариться между каналами и локациями, а могут выучиваться независимо:
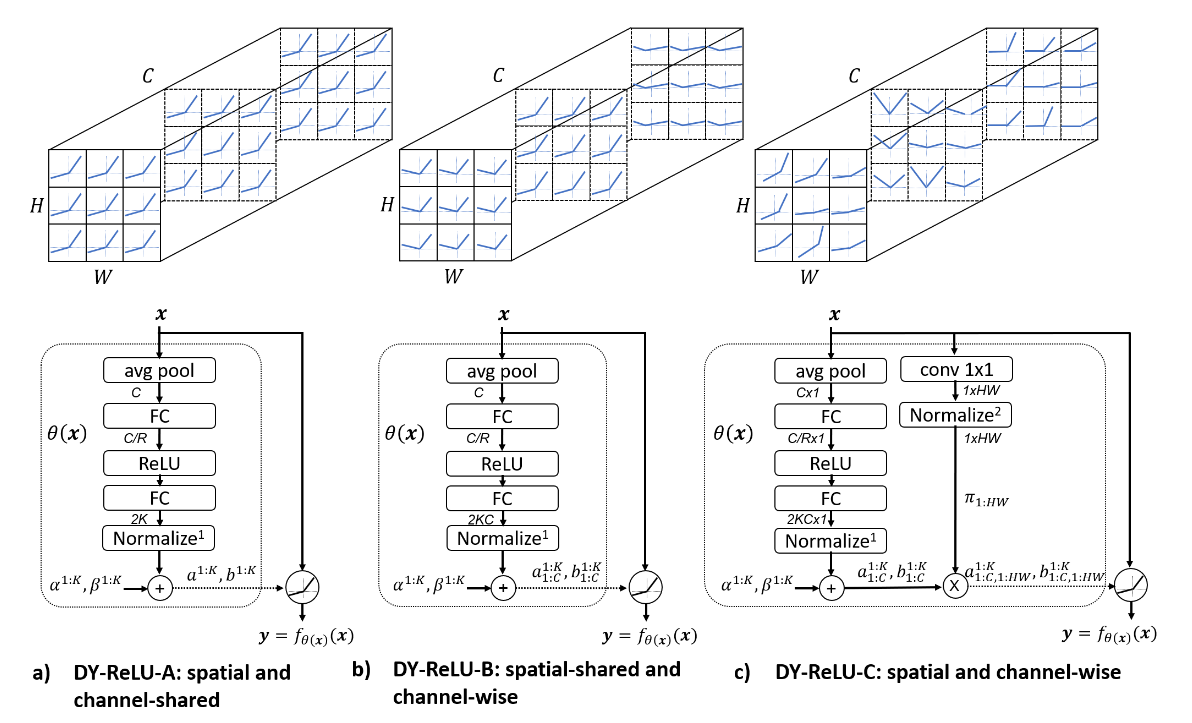
В декодере тоже творится много интересного. Self-attention остался без изменений, а вот cross-attention полностью изменён:
- Инициализируем так называемый Box Encoding для каждого positional query - в начале обучения делаем его равным всей картинке: [0, 0, 1, 1]. По сути, это обучаемый анкор для каждого query, который будет изменяться по ходу обучения.
- Делаем классический RoiPooling из фичей энкодера из региона Box Encoding.
- Генерируем динамические конволюционные фильтры с помощью простого линейного слоя, наложенного на object queries.
- Генерируем cross-attention между спуленными фичами и object queries с помощью 1x1-конволюции.
- Полученные обновлённые content queries можно по традиции пропустить через feed-forward networks, чтобы получить обновлённый box encoding. Таким образом, от слоя к слою декодера мы будем получать всё более точный box encoding для объектов на изображении.
В принципе это всё. Кода я не нашёл, особого ажиотажа в плане развития предложенных идей статья не вызвала, но из неё я, например, узнал про Dynamic ReLU. А включил статью я в эту секцию из-за RoI-attention, который по сути использует прямые энкоры.
Anchor DETR (2021)
290 звёздочек
Ещё одна работа, которая напрямую возвращает DETR-модели к идеологии энкоров. Каждый positional query здесь отвечает за определённую точку на изображении, и предсказывает объекты вблизи неё. Поскольку примерно в одном месте может находиться несколько объектов, авторы вносят такое изменение - один query теперь имеет несколько так называемых паттернов, а каждый паттерн может предсказать один объект. Для снижения расходов по памяти предлагается особая схема этеншна Row-Column Decouple Attention (RCDA).
Координаты энкоров (они могут быть фиксированными заранее или выучиваемыми) и координаты точек на фиче-мапах прогоняются через один и тот же Position Encoder - в данном случае это маленький MLP. Дополнительно мы инициализируем эмбеддинги трёх “паттернов”, которые шарятся между всеми object queries. Итого positional-часть каждого object query формируется как сумма positional-энкодинга энкора и эмбеддинга паттерна. Если у нас есть 100 энкор-точек и 3 паттерна, то итого мы получим 300 уникальных object queries.
Теперь поговорим о RCDA. Вспомним, что в качестве ключей в self-attention энкодера и cross-attention декодера у нас выступают фичи картинки из энкодера. Основная идея RCDA, как можно понять из названия - делать отдельный этеншн по строкам и по столбцам этих фиче-мап. Для желающих - тут можно поразбираться в деталях имплементации. Если кратко - мы делаем усреднение по двум измерениям, чтоб получить ключи строчек и ключи столбцов, а в качестве queries берём энкодинг соответствующей координаты энкора.
Дальнейшего развития идея не получила, в комбинации с другими трюками встречается редко.
Conditional DETR (2021) и Conditional DETRv2 (2022)
201 цитирование, 295 звёздочек
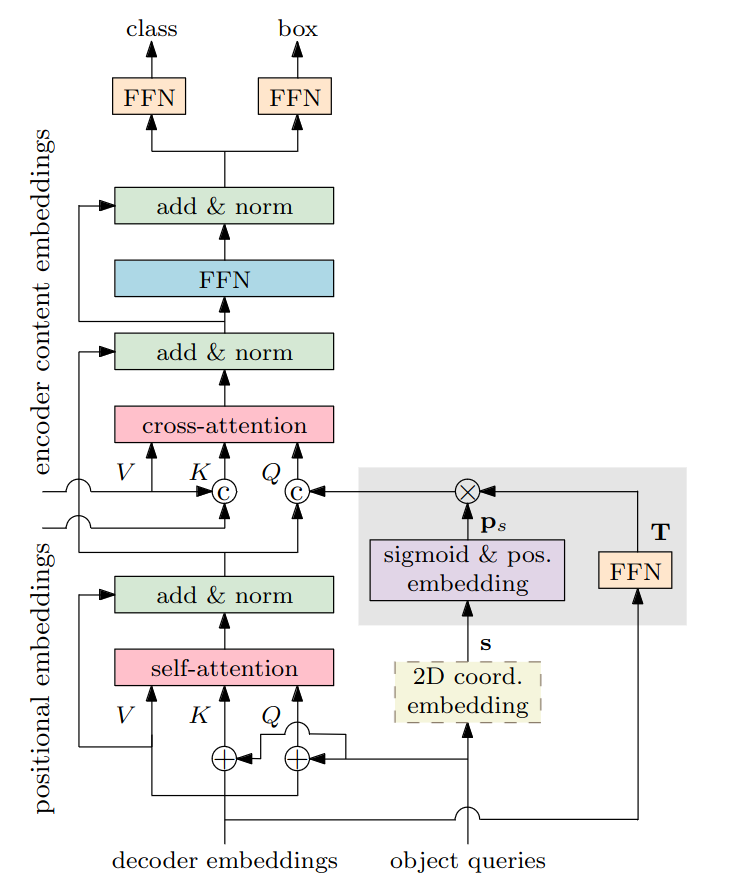
Вы не поверите - мы снова пытаемся пофиксить долгое обучение классического DETRа. В оригинальной статье про DETR были проведены разные ablation studies - в том числе, про positional queries. Оказывается, что если прибавлять их к Q и K только на входе декодера, а не в каждом слое, то AP падает всего на 1.4 единицы. А positional-веса этеншна, если обучать DETR 50 эпох, не очень хорошо соответствуют границам объекта.

Короче говоря, positional queries халявят и оставляют большую часть работу на content queries, которые учатся довольно долго. Для решения этих проблем предлагается сделать positional query адаптивными к изображению, то есть зависящими (тот самый conditional из названия) от текущего состояния content queries. Давайте разбираться, как это устроено.
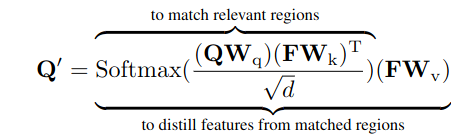
Как и в предыдущих работах, здесь используются референсные точки - центры объектов, которые предсказываются по выучиваемому вектору каждого positional query. Эти точки затем пропускаются через синусоидальный энкодинг для получения spatial-части query. После этого и начинается та самая conditional часть - мы скейлим этот энкодинг, умножая его на вектор, предсказанный из текущего состояния content query (кроме первого слоя, потому что там ещё нет никакой информации о картинке). То есть, позиционный энкодинг на каждом этапе начинает зависеть и от content-части query. Зачем это нужно?
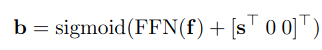
Если мы посмотрим на формулу (сверху) финального предсказания координат боксов, то увидим, что помимо референс-точки (s) в ней используется аутпут декодера (f), а это значит, что он явно содержит в себе информацию о расположении экстремальных точек объекта. Получается, что для получения корректной positional-репрезентации query (в v2 их называют box query) нам нужно сделать её зависимой от content-части.
После этого мы не суммируем, а конкатенируем content и positional-части, и делаем то же самое для фичей из энкодера. Итого - мы явным образом разделили cross-attention на две составляющие, при этом добавили зависимость positional от content. На картинке ниже в первом ряду показаны карты весов этешн positional-части, на второй - content-части, а на третьей - суммарные.

Во второй версии архитектуры авторы решают вовсе отказаться от выучиваемых positional queries, по которым предсказывались референс-точки. Вместо этого они предлагают что-то очень похожее на two-stage из Deformable DETR, хотя и отмечают, что делают это с другой целью. Берётся аутпут энкодера, и по каждому “пикселю” предсказывается вероятность, что там находится объект. Топ-k точек забираем как референсы и перегоняем их энкодер-репрезентации в box queries.
Второе нововведение - инициализация content queries не нулевыми векторами или выучиваемыми фиксированными эмбеддингами, а с использованием того же аутпута энкодера.
Наконец, они придумывают свой row-column этеншн, который выглядит очень похоже на своего собрата из Anchor DETR.
DAB DETR (2022)
131 цитирование, 374 звёздочки
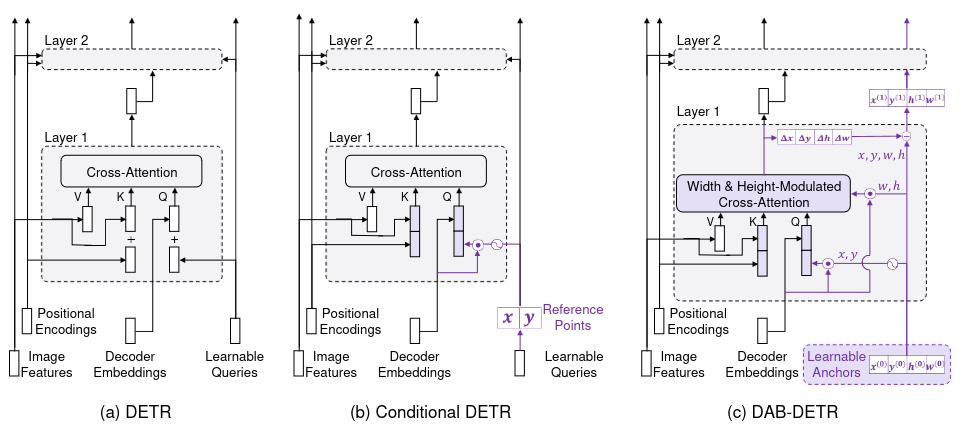
Почти все описанные статьи работают с 2D-точками в качестве референсов. Исключение - Deformable DETR с iterative box refinement. DAB DETR предлагает вернуться к классическим старым добрам энкорам, которые кодируются четырьмя числами - координатами верхнего левого угла, шириной и высотой коробки. Ширина и высота энкора необходимы для более корректного софт-пулинга фичей энкодера. Подобно механизму iterative box refinement, от слоя к слою декодера мы можем всё точнее предсказывать координаты и размеры коробки и пулить фичи всё более точно.
В предыдущих работах мы либо предсказывали референс-точки по positional queries как в Deformable DETR или Conditional DETR, либо фиксировали их и переводили в эмбеддинги как в Anchor DETR. Авторы DAB DETR утверждают, что никакой другой полезной информации кроме координат бокса в positional query и не содержится. А зачем тогда вообще использовать какие-то positional queries, если их можно заменить на конкретные обучаемые энкоры?
Сказано - сделано, каждый энкор теперь - это выучиваемый вектор, состоящий из четырёх компонент - координаты центра, высота и ширина. Теперь каким-то нужно информацию о них прокинуть в self- и cross-attention декодера. Для self-attention всё просто - энкодим каждый энкор синусоидально и пропускаем через MLP, а затем складывем с content-частью. Cross-attention заимствует идею из Conditional DETR - всё тот же синусоидальный энкодинг, который затем домножается на так называемый рескейл-вектор, предсказанный по content-части, и конкантенируем с content-частью.
Раз positional queries теперь имеют вполне конкретную интерпретацию (координаты центра и размеры коробки), то вполне логично их делать более точными от слоя к слою, предсказывая оффсеты и накладывая стандартный matching loss.
Последнее важное изменение DAB DETR - использование ширины и высоты энкора для модулирования cross-attention, которая позволяет учитывать его размер для получения более сфокусированных этенш-мап.

Для этого синусоидальный эмбеддинг энкора мы домножаем на отношение предсказанного размера объекта (например, ширины) и текущего размера энкора. Если объект сильно отличается от энкора, то prior на веса будет соответствующим образом скорректирован. Правда, авторы, кажется, сами не до конца понимают, почему это нормально работает, но какая разница? =)
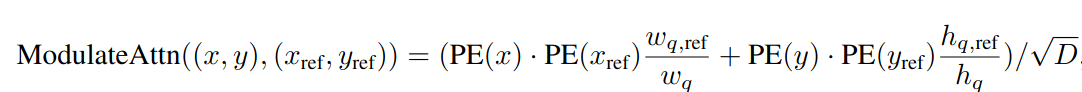
Подводя итог, главная идея архитектуры - простая, интерпретируемая и хорошо сочетается с другими модификациями - например, с тем же Deformable DETR.
DETR SMCA (2021)
146 цитирований, 145 звёздочек
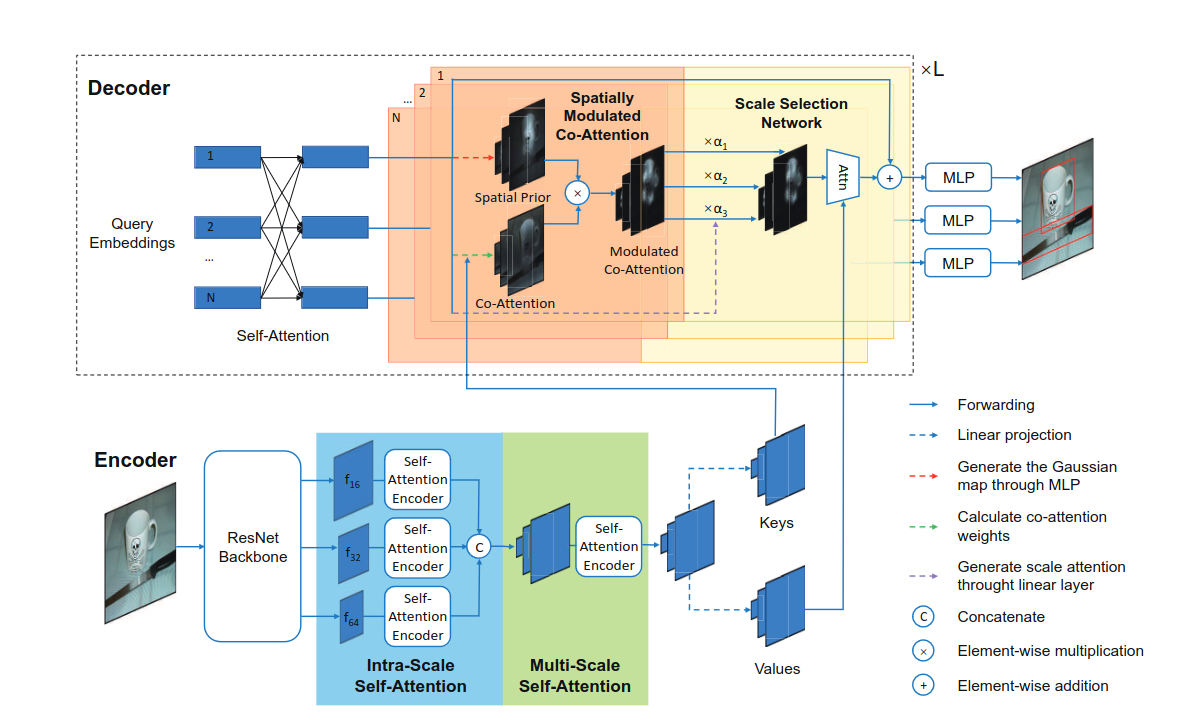
Идея Spatially Modulated Co-Attention, как понятно и из названия, как раз заключается в модуляции этеншн-весов. Логично предположить, что вероятность того, что близлежащие локации окажутся важнее дальних, в большинстве случаев выше. Так что можно домножать этеншн-мапы на spatial prior, чтобы ближайшие локации автоматически получали больше веса.
Работает это всё не очень сложно:
- Перед первым слоем декодера по каждому object query предсказывается референс-точка (центр объекта).
- Перед каждым слоем декодера по каждому object query предсказывается оффсет относительно референс-точки.
- Чем дальше каждая точка фиче-мапы от предсказанной точки (рефренс + оффсет), тем меньше исходный вес ей присваивается. Если точнее, итоговая карта весов из этенешна складывается с этими исходными значениями, и уже на эту сумму накладывается софтмакс. В формуле ниже c - это координаты предсказанной точки, s - предсказанные размеры объекта, β - гиперпараметр, i и j - координаты “пикселя” на фиче-мапе.
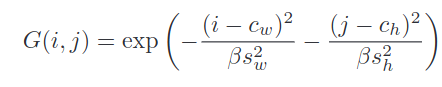
Ещё в статье упоминается адаптация SMCA под multi-scale фичи. Я хотел в ней разобраться и скачал ZIP-архив с имплементацией, который лежал в репе, и внутри увидел это:
Пожалуй, оставлю разбор в качестве домашнего задания. В сухом остатке SMCA докидывает и даже используется в качестве дополнительного улучшайзера в некоторых других статьях.
Efficient DETR (2021)
52 цитирования
Во всех модификациях DETRа по умолчанию используется 6 слоёв энкодера и 6 слоёв декодера - авторы оригинальной статьи в своём ablation study показали, что такое количество даёт оптимальные результаты. А почему так? Почему не хватает пары слоёв? Авторы Efficient DETR винят рандомные инициализации positional queries (DETR) или референс-точек (Deformable DETR).

Как видно из картинки, вне зависимости от способа инициализации исходных референс-пойнтов, на 6 слое декодера они приходят к практически одинаковым позициям. Это наводит на мысль, что если сразу похитрее инициализировать изначальные точки, то несколько слоёв декодера можно безболезненно срезать. А как получить хорошие начальные точки? Да просто навесив RPN на фичи энкодера.
Так-так, а в чём ключевые отличия архитектуры от two-stage Deformable DETR?
- Content queries инициализируются как фичи энкодера из соответствующей позиции. То есть, каждому query перед первым слоём декодера у нас соответствует предсказанный энкор и визуальные фичи из энкодера. Аналогичная идея впоследствии была применена в Conditional DETR v2
- Постепенно снижают число queries с 300 до 100 по ходу обучения.
- Показывают, что такая инициализация позволяет уменьшить количество слоёв декодера аж до 1 без особой потери качества.
Официальной имплементации я не нашёл, но нужные куски можно найти в репозитории Sparse DETR - вот инициализация queries с помощью фичей энкодера.
Team DETR (2023)
13 звёздочек
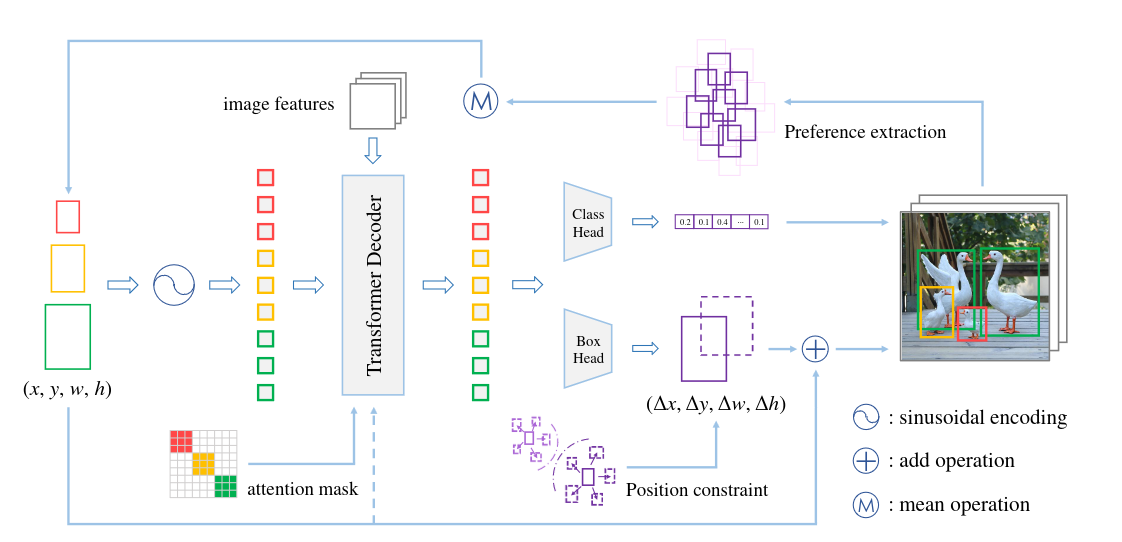
В этой достаточно свежей статье тоже работают с привязкой object queries к геометрии. Авторы берут за основу DAB-DETR и показывают, что каждый энкор (object query) в этой архитектуре предсказывает достаточно разнообразные коробки. Да, они сосредоточены вокруг энкора, но разброс по размеру весьма значительный (верхний ряд на картинке).

Предлагается простая идея - queries делятся на группы, и каждая группа отвечает за предсказание объектов своего скейла. Например, при разделении на 4 группы будут такие диапазоны скейлов (относительно размера изображения) - (0, 0.25], (0.25, 0.5], (0.5, 0.75], (0.75, 1.0). Детали имплементации:
- Маска для self-attention создаётся таким образом, что группы не могут обмениваться информацией.
- Размер изначальных энкоров инициализируются не случайно, а с учётом скейла группы.
- Венгерский матчинг при обучении тоже происходит внутри групп.
- К лоссу добавляется компонент, который наказывает queries за предсказания, которые находятся слишком далеко от соответствующего энкора.
- Самый интересный нюанс - на валидации для каждого query вычисляется средний предикт, и этот предикт становится новым энкором.
Вообще статья интересная, и имплементация несложная. Меня немножко смутил одушевляющий лексикон - “query’s personality”, “capabilities of each team member”. Вообще я когда-то писал, что такие метафоры могут помочь пониманию, но в данном конкретном случае выглядит странновато.
AdaMixer (2022)
Код (предупреждаю - паршивая структура mmdetection)
28 цитирований, 204 звёздочки
AdaMixer показывает очень неплохие результаты и является сильным бейзлайном в нескольких других статьях. Основная идея заключается в том, что процесс декодирования должен быть более адаптивным. Давайте попробуем раскрыть, что это значит.
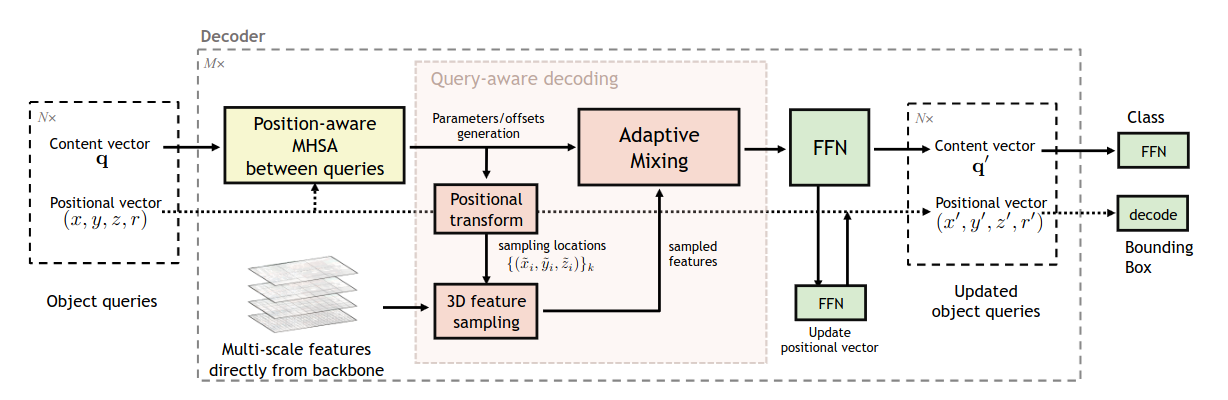
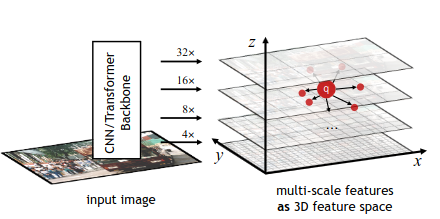
Positional query в AdaMixer состоит из четырёх частей - x, y (координаты центра), z (логарифм размера), r (соотношение сторон). Из них при необходимости легко можно получить стандартное представление коробок - координаты центра, ширина, высота.
Первая задача архитектуры - сделать так, чтоб декодер сэмплил фичи энкодера с учётом обеих частей object query - positional (включая размер объекта) и content. В классических детекторах энкоры маппятся на конкретный уровень фича-пирамиды в зависимости от их размера. Здесь решили поступить хитрее и элегантнее. Сначала фича-мапы располагаются в пространстве по третьей координате z. Затем мы берём content query и с помощью линейного слоя предсказываем три набора оффсетов - по x, y и z, и добавляем их к точкам из positional queries. Наконец, из полученных точек можем засэмплить фичи. Сначала на каждом уровне пирамиды делается стандартный сэмплинг с помощью grid_sample по x и y, а затем фичи с каждого уровня сэмплируются с учётом гауссовских весов, рассчитанных по предсказанной координате по z. Сэмплирование производится по группам, чтобы разнообразить набор точек, из которых производится сэмплирование. Итоговые фичи зависят от обеих частей object query, а ещё и учитывают размер объекта благодаря трюку с сэмплированием по z.
Сэмплировать фичи - это только первый шаг, их ещё нужно декодировать в объекты. В DETR и Deformable DETR фичи энкодера в этеншн-механизме просто проецируются линейным слоем, и эта проекция не зависит от текущего состояния object queries. AdaMixer вместо стандартного cross-attention использует механизм Adaptive Mixing.
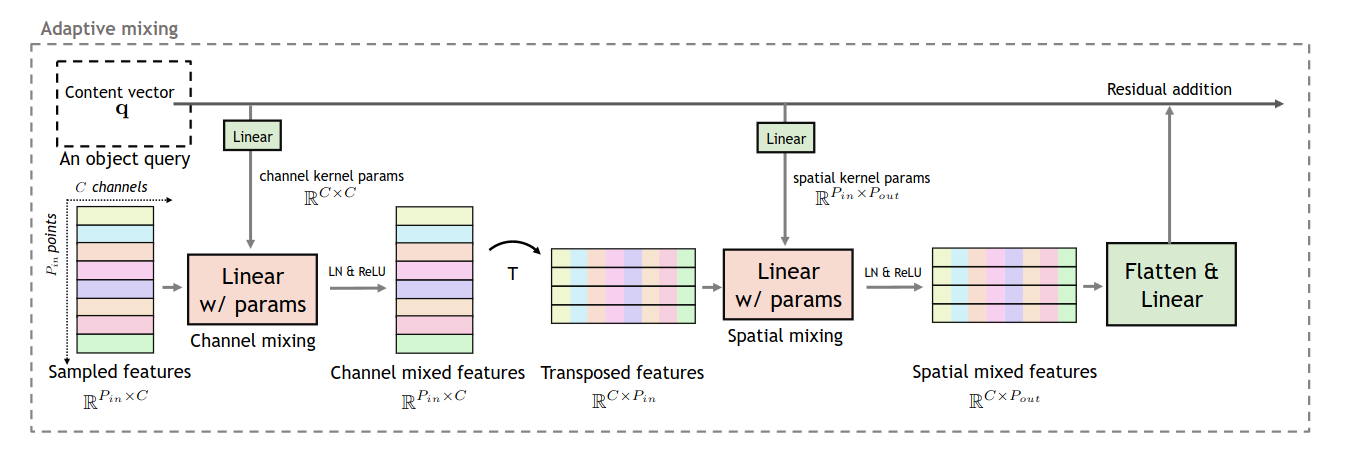
Adaptive Mixing состоит из двух частей. Сначала производится channel mixing. Content queries линейно проецируются в матрицу параметров размером CxC, где C - количество каналов. Фичи энкодера умножаются на эту матрицу, тем самым происходит смешивание фичей между каналами. Матрица рассчитывается независимо для каждой группы фичей, но шарится для всех пространственных точек.
Следующий шаг - spatial mixing. Аналогично, по content queries рассчитывается адаптивная матрица весов, с помощью которой производится миксинг фичей по пространственному измерению. Полученные фичи проецируются в размерность content queries и складываются с ними же, чтобы получить финальный результат работы слоя. Новые фичи пропускаются через FFN, а затем по ним предсказываются оффсеты для positional queries (x, y, z, r) и вероятности классов.
Последнее, что стоит отметить - это то, каким образом в self-attention прокидывается positional-информация. Помимо стандартного синусоидального энкодинга всех четырёх частей используется информация о том, насколько пересекаются коробки, соответствующие каждой паре object queries. Чем меньше пересекаются две коробки, тем более жёсткий отрицательный базовый вес присваивается этой паре. В случае, если коробка i содержится внутри коробки j, то штрафа нет. Таким образом, облегчается дедупликация предсказаний. Чтобы сеть могла всё-таки моделировать и отношения между непересекающимися объектами, штраф домножается на скаляр, который выучивается отдельно для каждой головы.
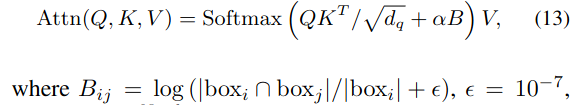
Вот в общем-то и всё. Итоговая сетка бьёт DETR, Deformable DETR и Sparse-RCNN.
Denoising queries
DETR предложил новую архитектуру для детекции - с энкодером, декодером, positional queries, двумя типа этеншна. Но ещё одним ключевым нововведением стал уникальный one-to-one matching loss. Вместо матчинга нескольких предсказаний и одной GT-коробки, мы находим оптимальную комбинацию, которая даёт минимальный лосс. Есть ли у этого подхода недостатки? Оказалось, что да.
DN-DETR (2022)
111 цитировний, 412 звёздочек
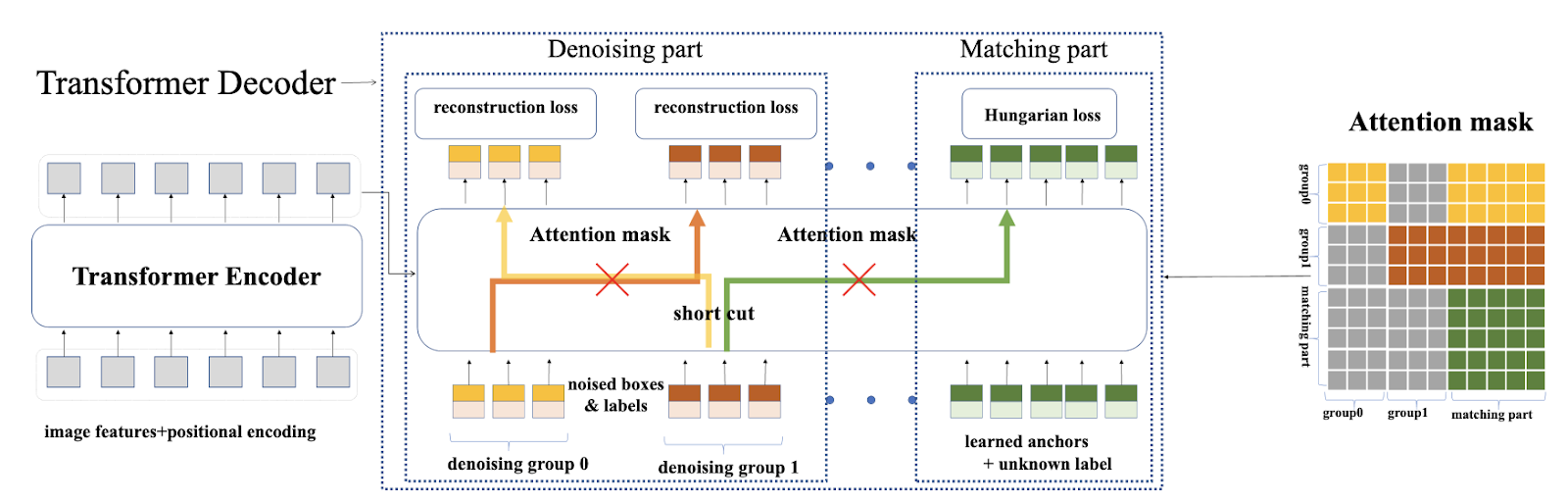
В начале обучения DETR часто выдаёт не очень качественные предсказания и большое количество дубликатов. Это приводит к тому, что оптимальный матчинг между queries и GT-боксами очень нестабилен - небольшое изменение весов сетки может привести к абсолютному другому матчингу. Один и тот же query на двух соседних эпохах может быть заматчен с разными GT-коробками или вообще с бэкграундом, что приводит к нестабильности обучения. Авторы статьи предлагают решить эту проблему так - давайте в качестве вспомогательной задачи кормить сетке зашумлённые GT-боксы (смещённые, увеличенные, уменьшенные) и просить её восстановить оригинальную коробку.
Имплементация достаточно проста - давайте создадим N дополнительных queries и разобьём их на m групп, так что в каждой группе окажется k=N/m queries. Каждая группа будет отвечать за денойзинг своего GT-бокса. Чтобы “скормить” GT-бокс своей группе queries, используется идея DAB-DETR, в котором каждый query - это конкретный бокс со своими координатами и размером. Берём коробку, зашумляем её k раз и инциализируем каждый query в группе своей версией шумного бокса. Задача декодера - воссоздать оригинальную коробку, то есть найти такой шифт зашумлённой версии, который вернёт её к истинной коробке.
В принципе это всё, но дьявол как всегда кроется в деталях:
- Наивная имплементация такого дизайна ведёт к двум мощным ликам из-за механизма self-attention в декодере. Оригинальные queries получают доступ к зашумлённым версиям реальных коробок, а denoising queries внутри группы могут смотреть на другие зашумлённые версии самой себя. Что ж, слава богу, в MultiheadAttention есть замечательный аргумент attention_mask. Достаточно аккуратно инициализировать этот тензор, и queries не смогут смотреть, куда им смотреть не следует.
- Предложенный дизайн никак не использует информацию о классе объекта. Для повышения эффективности метода мы можем заставить сетку осуществлять и label denoising. Для этого мы можем случайным образом поменять истинный лейбл GT-коробки и прогнать его через эмбеддинг-слой. В итоге каждый query в декодере инициализируется как сумма positional-части (проекция синусоидального энкодинга зашумлённой коробки) и content-части (проекция эмбеддинга зашумлённого лейбла). Сетке нужно предсказать не только настоящие координаты и размер коробки, но и её настоящий класс.
Почему это всё вообще должно увеличивать стабильность матчинга?
Авторы разделяют процесс обучения DETR на две задачи - выучивание хороших энкоров и предсказание хороших оффсетов для этих энкоров. Из-за нестабильности матчинга (особенно на первых эпохах) вторая задача усложняется - ведь каждому query постоянно нужно предсказывать разные оффсеты в зависимости от того, с каким объектом он в этот раз сматчился. Для демонстрации этого эффекта авторы рассчитывают параметр IS (instability). Если query на двух соседних эпохах сматчился с разными объектами - добавляем единичку. Использование denoising queries ведёт к более стабильному матчингу, ведь “хорошим энкором” как раз выступает зашумлённый GT-бокс.
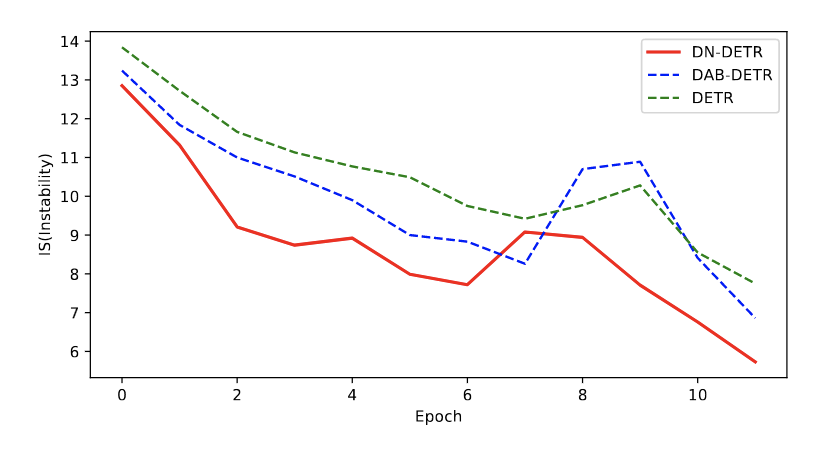
Дополнительно решение задачи денойзинга ведёт к тому, что каждый query более расположен к поиску близлежащих объектов. На картинке мы видим, что оффсеты между энкорами и итоговыми предсказанями значительно ниже для DN-DETR, чем для DAB-DETR.
Вот такая вот несложная идея, которая сильно забустила метрики и заложила основу для одной из лучших версий DETRа - DINO.
DINO (2022)
162 цитирования, 1.3к звёздочек
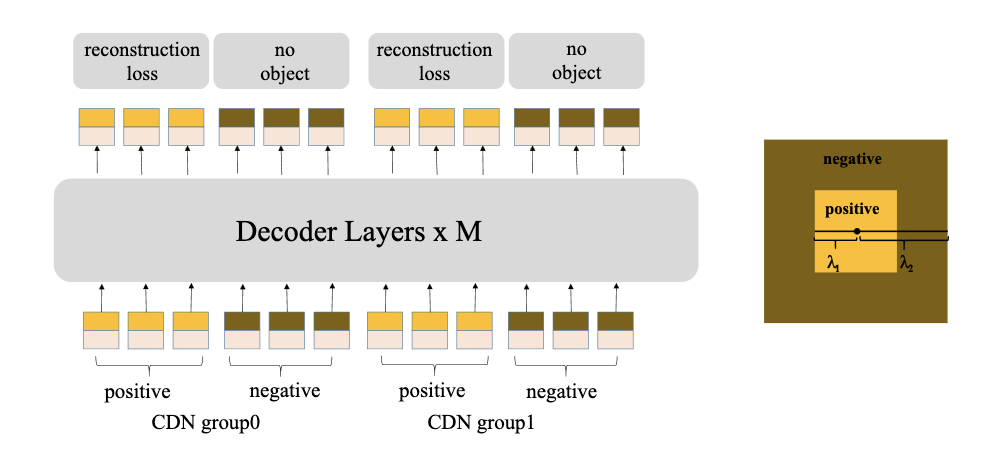
Идея DN-DETR проста и мощна - мы используем денойзинг шумных GT-коробок как вспомогательную задачу для ускорения обучения. Но умение предсказывать хорошие оффсеты поможет, только если у нас есть хорошие энкоры. А что делать с плохими, рядом с которыми нет никаких GT-объектов?
DINO предлагает использовать в задаче денойзинга не только положительные примеры, но и отрицательные. В каждой группе мы можем попросить часть вспомогательных queries денойзить хорошие энкоры, а часть - отвергать энкоры средненького качества. Чтобы сгенерить такие “так себе” энкоры достаточно наложить на центр GT-коробки более сильный шум (на картинке - точки внутри коричневого квадрата). При этом он должен быть не слишком сильным - чтобы энкор был всё ещё близок к объекту, но хуже, чем другие энкоры. В итоге модель в contrastive-манере учится понимать, что вот эти энкоры - хорошие, а вот эти - не очень, и для них нужно предсказать высокую вероятность background. Такой метод позволяет ещё сильнее уменьшить количество дубликатов - когда есть один хороший предикт и несколько посредственных. Особенно это помогает находить хорошие энкоры для маленьких объектов.
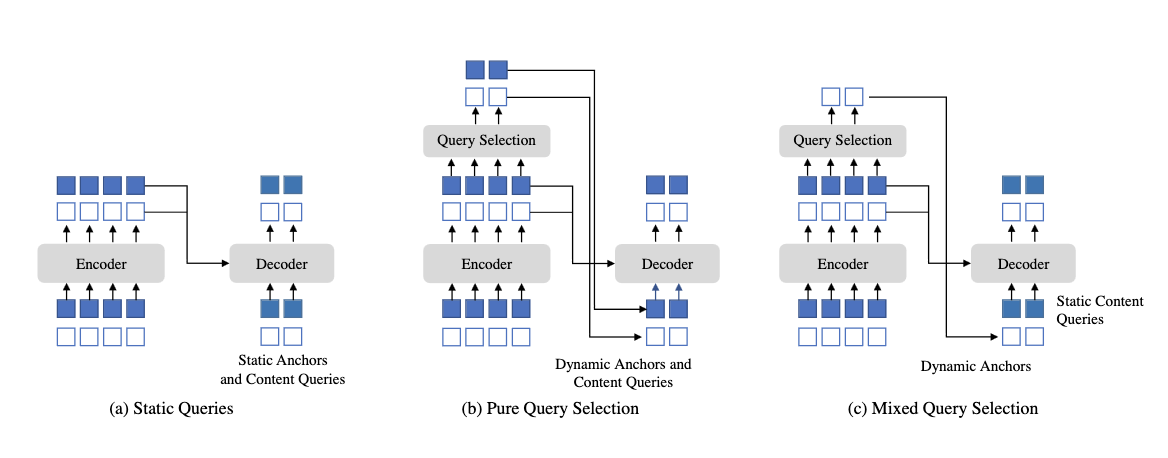
Второе важное отличие DINO называется mixed query selection. В оригинальном DETR positional queries и инициализация content queries статична в том смысле, что никак не зависит от текущей картинки. Мы просто выучиваем хорошие энкоры и инциализируем content queries как нулевые векторы (картинка a). Некоторые архитектуры (например, two-stage Deformable DETR и Efficient DETR) отказываются от этого и динамически иницализируют энкоры и их content-часть с помощью энкодера (b). В DINO используется смешанный подход - positional-часть использует лучшие пропозалы энкодера, а вот content-часть остаётся независимой. Правда, в данном случае это не нулевые векторы, а выучиваемые эмбеддинги (c).
Последняя модификация - это look forward twice. Качество предсказанной коробки на i-ом слое декодера зависит не только от текущего предсказанного оффсета, но и от текущего состояния энкора (positional query). Если энкор хороший - то и оффсет предсказывать легче. При этом, напомню, что в iterative box refinement Deformable DETR мы блокируем градиент между слоями. То есть, мы наказываем сетку за плохо предсказанные оффсеты, но не учитываем при этом качество исходного энкора. В DINO для предсказания промежуточных коробок на слое i используются текущие предсказанные оффсеты и недетачнутая версия референс-точек со слоя i-1. Звучит сложновато, но по факту это четыре символа в коде.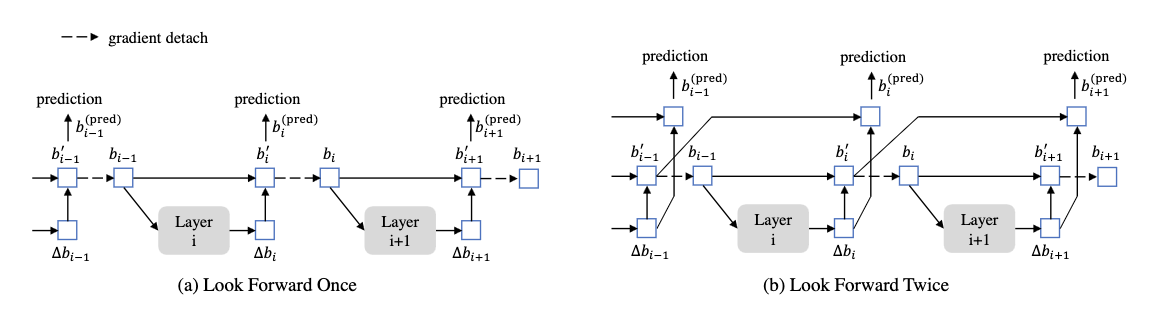
DINO стоит на плечах предыдущих достижений - Deformable DETR, DAB DETR и DN DETR, но предложенные модификации позволяют достичь мега-соты.
DEYO (2022)
Забавная идея, которая развивает архитектуру DINO. Если в DINO для инициализации queries используется пропозалы из энкодера, то тут для генерации энкоров дополнительно используется ещё и аж целый YOLOv5. Насколько я понял, 800 queries инциализируется как обычно, а 100 из предиктов YOLO.
По факту к этой секции отношения особо не имеет, поскольку главное изменение - это именно YOLO, но ладно уж.
Exploiting positive anchors
Лосс DETRов состоит из трёх комопонентов - бинарная кросс-энтропия, GIoU и L1. На вход кросс-энтропии идут все 100/300/900 queries, а вот локализационные лоссы получают супервижн только от тех queries, которые были сматчены с GT-коробками. Их на каждой картинке обычно не так чтобы очень много. Можем ли мы как-то облегчить для сетки задачу локализации? Конечно, да.
H-Deformable-DETR (2022)
19 цитирований, 151 звёздочка
Одна из моих любимых статей про DETR - потому что она мега-простая в понимании и имплементации, но при этом эффективная. Раз у нас мало GT-объектов - давайте возьмём и продублируем их, например, 6 раз. За предсказание этих фейковых объектов будут ответственны специально выделенные под эту задачу queries. Конечно, не забываем при этом сгенерировать нужную attention-маску для self-attention, чтобы исключить взаимодействие двух групп queries. Вспомогательные queries на инференсе отбрасываются. Всё! Уложились в один параграф.
На выходе получаем улучшенные метрики и ускоренное обучение за счёт роста потребления видеопамяти и небольшого замедления на трейне. На инференсе лишние queries можно отбросить.
Group DETR (2022) и Group DETR v2 (2022)
3 цитирования
Идея очень похожа на предыдущую, только каждая копия GT-объектов матчится к своей выделенной группе queries. Естественно, мы блокируем self-attention между группами. На инференсе используем только одну группу - говорят, что можно брать любую, результаты одинаковые.
Во второй версии модели авторы собирают все топовые фишки (group assignment, DINO, ViT как бэкбоун) и получают мега-гига-соту.
Co-DETR (2022)
Код (code will be available soon lol)
5 цитирований, 56 звёздочек
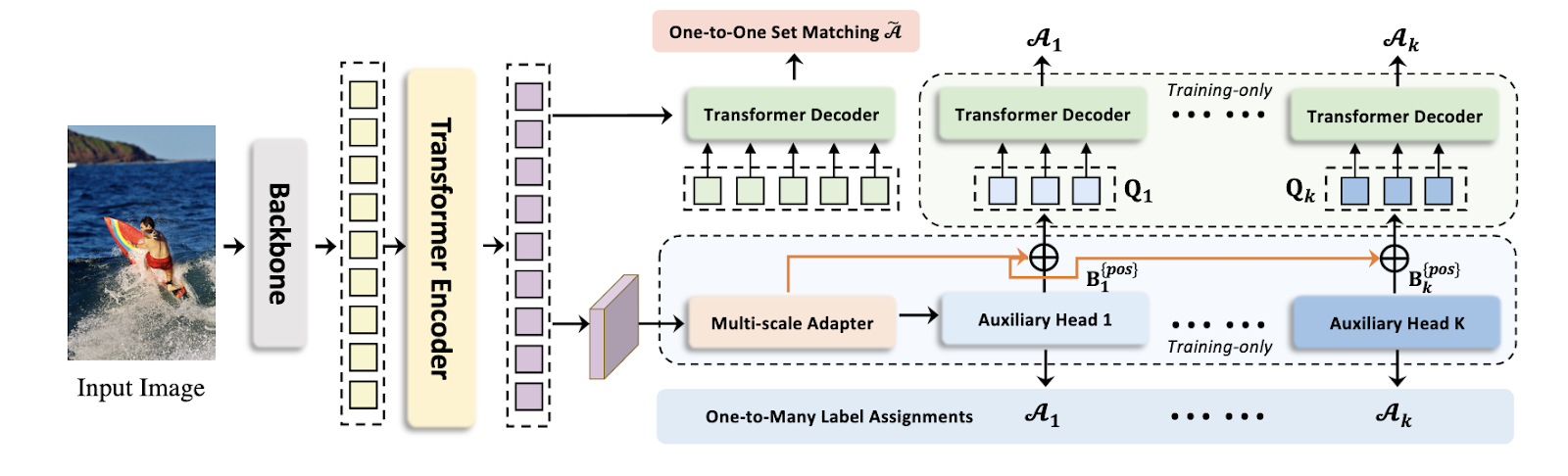
Я уже упоминал, что детекторы можно выстраивать из кубиков, выбирать разные компоненты и соединять в хитрые архитектуры. Например, мы можем вместо декодера с positional queries и one-to-one матчингом просто навесить на энкодер другие детекционные головы - например, Faster-RCNN, RetinaNet или FCOS (кстати, тут есть старая запись моего доклада про anchor-free детекторы, сорри за ужасный звук). Зачем бы нам это делать? А затем, что традиционные детекторы используют one-to-many assignment - к примеру, в Faster-RCNN любой предикт, который имеет IoU с GT-коробкой выше порога (обычно 0.5 или 0.7), используется как положительный пример. Благодаря этому мы получаем намного больше примеров для супервизии трансформер-энкодера и бэкбоуна.
В Co-DETR энкодер отдаёт фича-мапу одного скейла, затем мы строим из неё пирамиду фичей. Происходит это очень просто - никаких FPN или чего-то хитрого, просто делаем апсэмплинг и даунсэмплинг единственной фича-мапы. На полученную пирамиду мы можем навесить любую любимую детекцию - например, RPN + RCNN из Faster-RCNN. Получаем её предсказания, делим их на foreground и background согласно IoU или другому критерию, накладываем лосс.
На этом ребята не останавливаются - хочется ведь помочь и декодеру. Все положительные предсказания из каждой головы можно превратить в positional queries как в DAB-DETR и DN-DETR - координаты и размер коробки энкодятся синусоидально и проецируются в новое пространство. Матчинг для этих queries не нужен, мы уже знаем, какие GT-коробки им соответствуют.
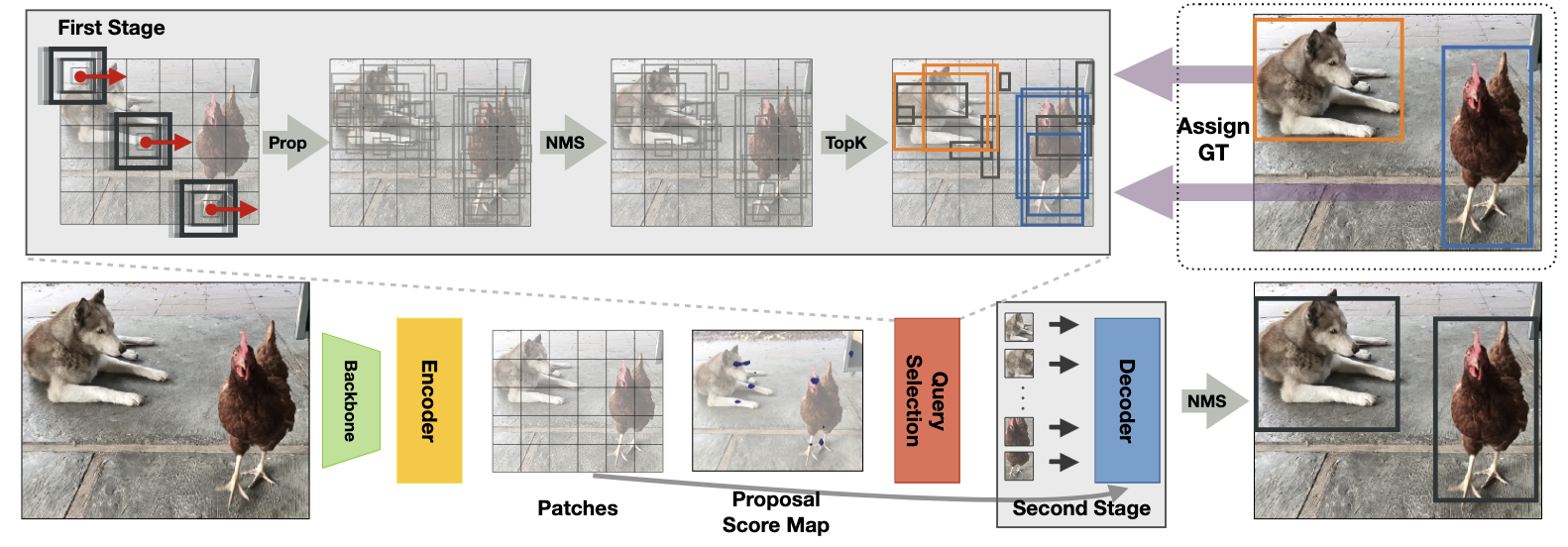
NMS Strikes Back (DETA) (2022)
2 цитирования, 165 звёздочки
А нужен ли вообще one-to-one матчинг, если от него столько проблем? В DETRообразных архитектурах одна из основных его задач - дедубликация предсказаний, которая позволяет отказаться от NMS. А так ли он плох?
Авторы статьи берут за основу двухстадийный Deformable DETR и заменяют one-to-one matching на обычный IoU-assignment как в Faster-RCNN и других детекторах. Делается это на обеих стадиях (энкодер и декодер) - сейчас будем разбираться как именно.
Напомню, что на стадии энкодера в two-stage Deformable DETR каждый “пиксель” генерит кандидата на хороший пропозал. Это происходит путём предсказания оффсета относительно энкора с фиксированным размером стороны и центром в этом “пикселе”. При IoU-assignment нам сначала нужно определить, а является ли вообще этот энкор положительным или отрицательным. Для этого каждый энкор матчится с GT-объектом, с которым у него наибольший IoU, при этом он должен быть выше порога. Я не знаю, насколько это хорошо будет работать для супер-маленьких объектов, не уверен, что они будут матчиться с энкорами фиксированного размера даже на самых больших фиче-мапах, надо проверять. В любом случае авторы указывают, что можно все назаматченные GT-объекты в итоге связать с ближайшим ещё незаматченным предиктом, и хуже это не сделает. На это всё сверху накладывается обычный бинарный классификационный лосс, как в RPN. Раз несколько предиктов теперь могут соответствовать одному GT-объекту, это неминуемо ведёт к очень похожим пропозалам, так что NMS накладывается уже на этой стадии. Собственно, как и в обычном Faster-RCNN.
На второй стадии всё точно так же, только вместо фиксированных энкоров для матчинга используются улучшенные пропозалы из энкодера. Вот тут авторы как раз подмечают, мол, даже если снизить порог IoU с 0.7 до 0.6, у больших и средних объектов будет значительно больше сматченных предиктов, чем у маленьких. Для поддержания баланса можно ограничить количество предиктов, который могут сматчиться с одним и тем же объектом. И, конечно же, не забываем накинуть NMS сверху.
В общем-то всё! Оказывается, что можно обучить DETR и без one-to-one матчинга, и метрики получаются даже лучше - ведь как показали H-DETR, Group DETR и Co-DETR, увеличение количества позитивных сэмплов помогает обучению. Из дополнительных плюсов - можно убрать self-attention между queries, из минусов - снова появляется NMS, к которому нужно подбирать IoU-трешхолд под свою задачу. А на каких-то задачах NMS может и вовсе фейлиться.
Другие формулировки задачи
Все упомянутые DETRы решают одинаковую задачу - предсказание координат центра, а также ширины и высоты коробки. Статьи в этой секции предлагают другие формулировки задачи детекции.
Pair DETR (2022)
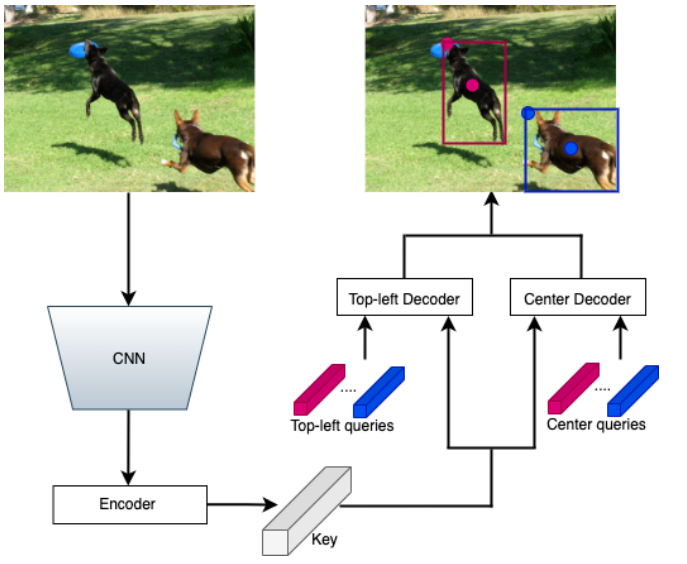
Есть такой старый прикольный детектор - CornerNet, он детектит верхние левые и правые нижние углы, и потом связывает их в пары через специальный хитмап эмбеддингов. Если эмбеддинги двух точек похожи - значит, это углы одного объекта. Pair DETR использует похожую формулировку - предсказываем левую верхнюю точку и центр коробки, причём за эти два предсказания ответственны два разных декодера. Центральный декодер ещё и предсказывает класс объекта. Собственно, поэтому здесь и используется не правый нижний угол, а центр, потому что там обычно больше важных для классификации фичей.
Детали дизайна:
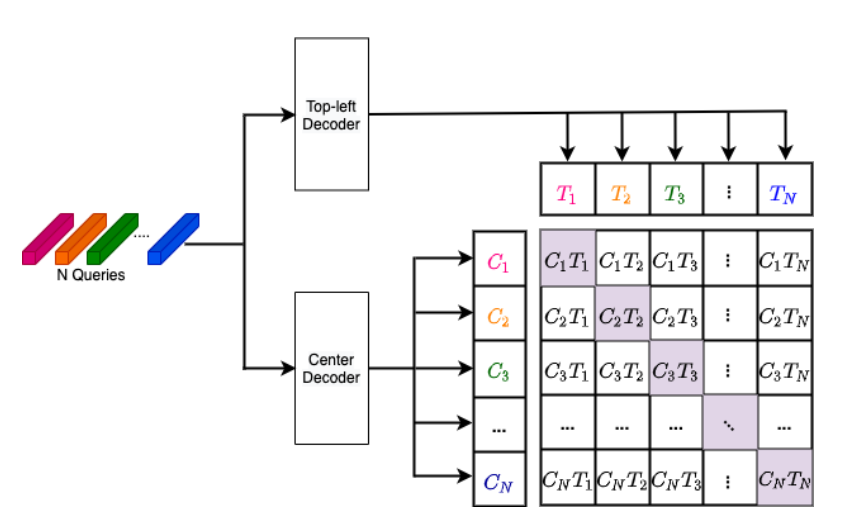
- Фичи из энкодера и выучиваемые positional queries шарятся между двумя декодерами. i-ый query в одном декодере будет соответствовать i-му query во втором, то есть, они должны предсказывать точки одного и того же объекта. Это позволяет нам в духе SimCLR составить N (число queries) позитивных пар точек. Аутпуты декодеров для этих пар мы просим сделать похожими, а в качестве негативных примеров, которые должны отличаться берём остальные 2N - 2 (в статье написано 2N - 1, но я не понял почему) аутпутов декодера. Этот лосс прибавляется к классическим классификационным и регресионным.
- Остальная архитектура соответствует Conditional DETR.
Метрики, вроде бы, повыше, а ещё показывают на примерах, что улучшается детекция объектов, которые сливаются с фоном, маленьких объектов внутри больших объектов и объектов по краям изображения.
SAM-DETR (2022) и SAM-DETR++ (2022)
31 цитирование, 261 звёздочка
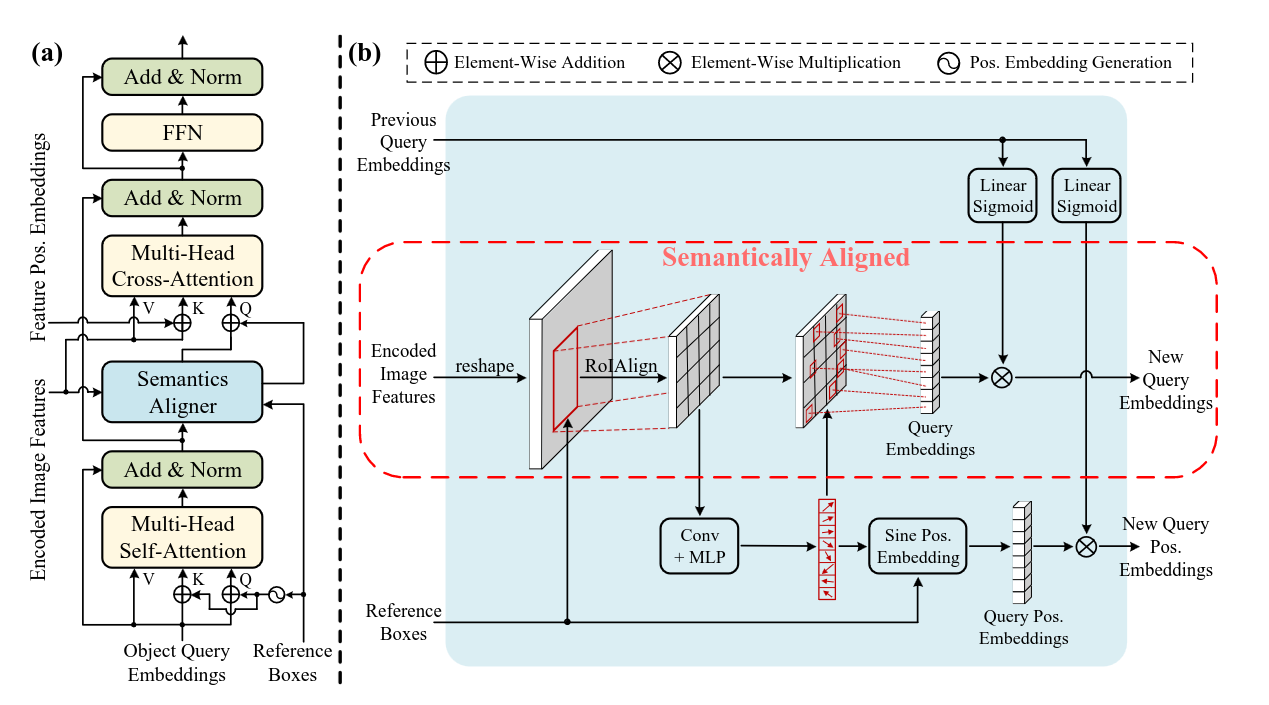
Строго говоря, статья не подходит в эту категорию, предсказываются в ней всё так же центры и размеры коробок, но одна из идей тут связана со следующей архитектурой SAP-DETR. Итак, авторы утверждают - одна из причин медленной сходимости DETR заключается в том, что в cross-attention Q (object queries) и K (фичи энкодера) оперируют в разных пространствах. Сюда они приплетают сиамские сети - мол они как раз созданы, чтоб переводить Q и K в одно пространство для сходимости. А в DETR Q и K в cross-attention имеют абсолютное разное происхождение. Соответственно, в начале обучения object queries примерно одинаково “размазывают” своё внимание по всем регионам, и требуется какое-то время, чтоб научиться фокусироваться на определённых.
Проблему предлагается решить достаточно необычным способом. По сути, мы просто берём и генерим content queries напрямую из фичей энкодера. Давайте разбираться…
- В качестве positional queries используются выучиваемые референс-боксы.
- Эти боксы используются для того, чтобы спулить фичи энкодера, которые предварительно решейпятся обратно в прямоугольник, с помощью старого доброго RoIAlign.
- По этим фичам предсказываются M координат точек, где M - число attention-голов в cross-attention. Из этих точек с помощью grid_sample забираются фичей наиболее важных точек бокса.
- Эти фичи и становятся новыми content queries. Возникает разумный вопрос - а нафига нам content queries с предыдущего слоя, если они тупо заменяются фичами из энкодера? Происходит ход конём - с их помощью генерируются веса, на которые домножаются новые content queries.
- Предсказанные точки также используются для генерации новых positional queries. Трансформируем их внутрикоробочные координаты в глобальные, генерим синусоидальный энкодинг и тоже домножаем на веса, полученные из content queries.
В журнальной версии статьи (аж с двумя плюсами) убирается дропаут в трансформерах и добавляется поддержка multi-scale фичей. Первые слои декодера работают с самыми маленькими фичами, следующие два - с картой побольше, и последние два - с самым высоким разрешением. Благодаря описанному выше алгоритму семантического матчинга content queries подстраиваются под фичи того уровня, с которым мы сейчас работаем.
SAP-DETR (2022)
2 цитирования, 18 звёздочек
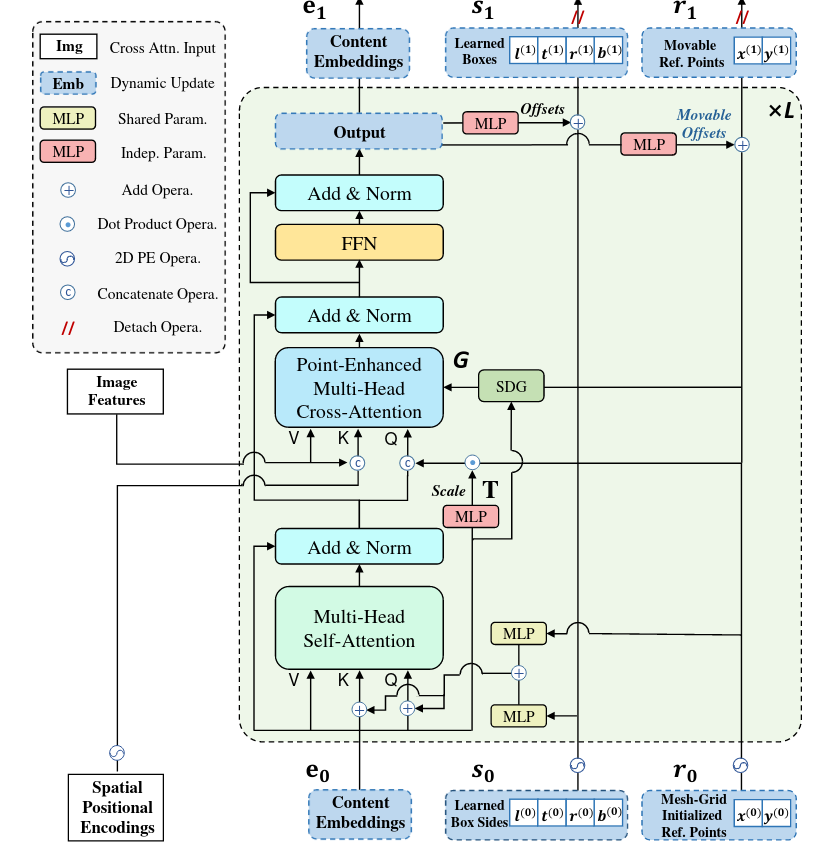
Модификации DETR, которые эксплицитно моделируют референс-точки или боксы, обычно используют центры объектов. Если задуматься, возможно, это не самое лучшее описание объекта с точки зрения задачи детекции - центры пересекающихся объектов часто находятся примерно в одном месте, а ещё это ведёт к тому, что появляется много queries, которые неплохо локализуют объекты, но всё равно попадают в негативные сэмплы после матчинга. А это сильно замедляет обучение. Какие есть альтернативы?
Только что упомянутый SAM-DETR пытался найти внутри бокса наиболее важные точки. Авторы SAP-DETR двигаются дальше - и предлагают в качестве референс-точки использовать наиболее важную для данного объекта точку.
Каждый positional query в SAP-DETR состоит из двух частей - референс-точка и четыре расстояния до каждой стороны бокса (как во FCOS). Референс-точки можно равномерно раскидать по всему изображению.

Каждый слой декодера предсказывает новые оффсеты для этих четырёх расстояний. Каждый object query стремится предсказывать только боксы, которые включают в себя референс-точку. Это делается с помощью добавления специального лосса, который накладывает штраф, если мы сматчили query с рефренс-точкой вне GT-бокса.
Изображение может быть большим, и раскиданные точки могут не покрывать все объекты. Особенно это касается маленьких и удлинённых объектов. Чтобы решить эту проблему, референс-точкам разрешается ездить по картинке, но не слишком далеко. Для этого предсказанное “путешествие” домножается на скейл-фактор, равный единице, делённой на корень из размера грида (на картинке 4).
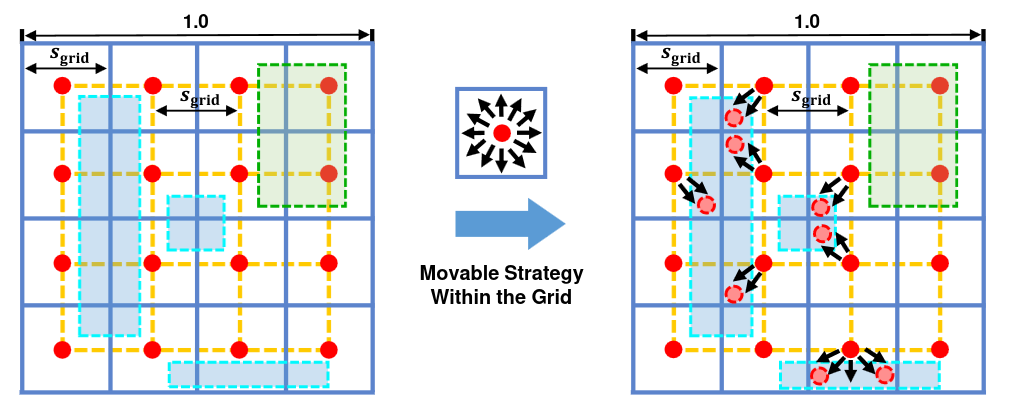
Вот так выглядит движение точек на реальных картинках:
Последнее важное изменение касается cross-attention. Визуализация весов этого attention в DETR показывает, что queries обращают внимание на центры и края объектов, что звучит логично. Если у двух queries похожие референс-точки и веса этеншна на края объекта, то начинаются проблемы. SAP-DETR разделяет cross-attention на две карты, которые потом суммируются.
Первая называется Side Directed Gaussian и является развитием идеи DETR SMCA. Считается он примерно так:

Я даже попытался в ноутбучке поразбираться с тем, как генерируются все эти оффсеты и карты. Суть заключается примерно в следующем. Мы берём нашу референс-точку и сдвигаем её ближе к сторонам коробки - например, вправо и вниз. Направление движения (влево-вправо, вверх-вниз) определяется знаком o_i, который предсказывается по текущему content query. От этой новой точки и разбрасывается гауссианская этеншн-мапа. Таким образом, каждая голова этеншна может больше обращать внимания на тот или иной край объекта.
Вторая карта называется Point Enhanced Cross-Attention или PECA. Авторы говорят - посмотрели мы, значит, на визуализацию spatial attention в Conditional DETR, и увидели, что в основном весь этеншн идёт на одну из сторон объекта. В связи с этим предлагается конкатенировать энкодинг координат сторон объекта к Q в Cross-Attention.
Итоговая этеншн-мара формируется как сумма SDG и PECA. В общем и целом, не фанат, довольно перегруженная идеями архитектура. Да, есть прирост, но по сравнению с тем же SAM-DETR не гигантский.
Pretraining
Да-да, мы помним, DETR долго обучается. А что если его предобучить, да ещё и в self-supervised манере?
UP-DETR (2020)
303 цитирования, 443 звёздочки
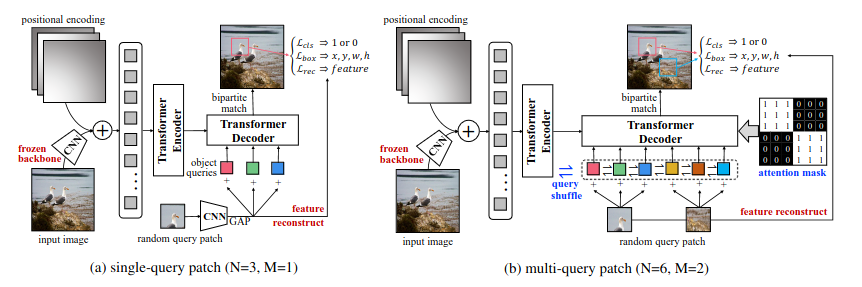
Идея максимально простая - берём рандомный кроп из изображения, засовываем его фичи в queries, и просим DETR предсказать координаты этого кропа. Авторы сразу подмечают, что если это сделать максимально просто, то мы столкнёмся с парой проблем:
- раз мы просто сетку решать только задачу локализации, то мы уничтожим классификационные фичи
- на одном изображении обычно много объектов, так что лучше просить сетку предсказать несколько кропов
Чтобы скормить кроп картинки декодеру, фичи кропа сначала преобразуются в вектор с помощью AdaptiveAvgPool2d, приводятся к нужному размеру (обычно 256) линейным слоем, а затем ещё зануляется 10% получившейся репрезентации. Получившуюся штуку приплюсовываем к традиционным learnable positional queries из DETR. Стоит отметить, что вся картинка и патч прогоняются через один и тот же CNN-бэкбоун раздельно.
Для решения проблемы отсутствия задачи классификации в такой схеме претрейна, вводится дополнительная задача - по аутпуту декодера будем восстанавливать исходные фичи кропа (после адаптивного пулинга). Кроме того CNN-бэкбоун во время претрейна заморожен и вместе с DETR не обучается.
Механизм предсказания нескольких кропов тоже реализован достаточно просто. Все queries делятся на количество групп, равное количеству кропов. К каждой группе добавляются фичи одного из кропов. Поскольку в реальных задачах queries не связаны ни в какие группы, для каждого батча порядок queries перемешивается, то есть, каждый раз образуются случайные группы. Логика группового разделения такая - это позволяет сети научиться делать дедубликацию похожих предиктов внутри группы queries. Традиционно группы не взаимодействуют между собой благодаря этеншн-маске.
Такой механизм позволяет претрейнуть DETR, если у вас есть большой неразмеченный датасет из такого же домена, что на практике встречается достаточно часто.
DETReg (2021)
44 цитирования, 302 звёздочки
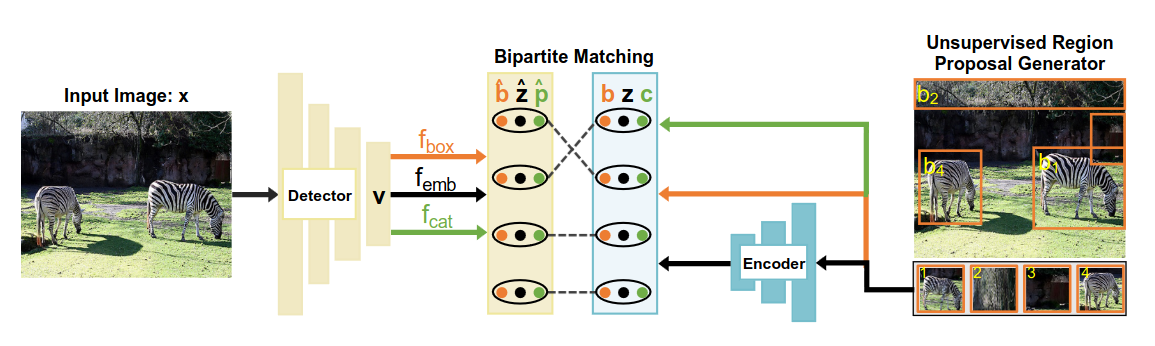
Главный минус подхода UP-DETR - мы пытаемся предсказать расположение рандомных патчей, на которых может вообще не быть никаких объектов, может быть часть объекта или несколько объектов. Короче говоря, UP-DETR не учится находить реальные объекты. Подход DETReg отличается - давайте возьмём какой-нибудь простой метод поиска потенциальных мест интереса, например, Selective Search, который использовался ещё в R-CNN до появления RPN. Selective Search - это старый алгоритм, который эксплуатирует тот факт, что объекты часто однородны по цвету и имеют продолжительные непрерывные границы. Задача сетки - найти области, которые выплюнул этот алгоритм. Можно искать рандомные K областей или отсортировать их в иерархическом порядке - от наибольших регионов к наименьшим. Как и в UP-DETR, в такой задаче отсутствуют классы и задача классификации. Для решения этой проблемы найденные регионы кодируются отдельной претрейнутой сеткой, а задача DETReg - восстановить эти эмбеддинги. В общем-то это всё.
Дистилляция
DETRы могут бить по метрикам классические детекторы, но обучаются медленнее. А что если дистиллировать знание обученных детекторов в DETRы? К сожалению, оказывается, что известные методы дистилляции для детекторов не очень хорошо работают для передачи знаний DETRам. В этом разделе рассмотрим методы дистилляции, разработанные специально под эту архитектуру.
Teach-DETR (2022)
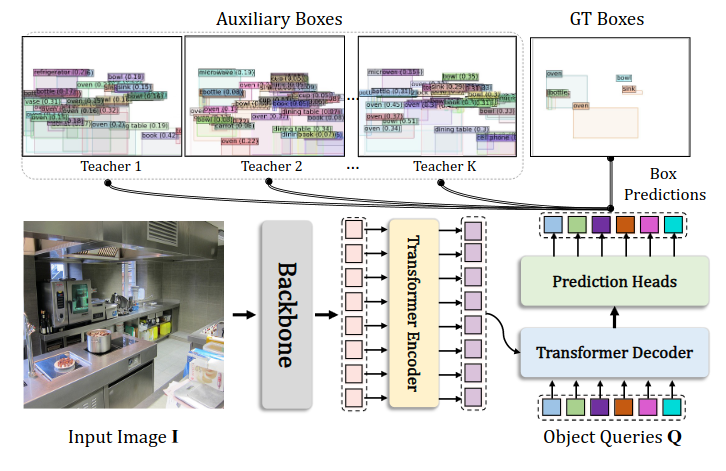
В качестве конкурентов своему подходу авторы берут три проверенных метода дистилляция для детекторов.
Первый метод - это FGD. Он основан на дистилляции на уровне фичей, только вот простая дистилляция для детекции работает плохо - слишком велик обычно дисбаланс FG и BG, а дистилляция только по FG не так уж и докидывает по метрикам. Авторы предлагают модуль фокальной дистилляции, который отдельно дистиллирует фичи бэкграунда и объектов. Добавляются всякие дополнительные фишки - учитываются размеры GT-объектов, степень FB-BG имбаланса, сильнее дистиллируются “пиксели” и каналы, которые играют более важную роль. Ещё используется модуль глобальной дистилляции, основанный на GcBlock. Не буду углубляться в детали, про дистилляцию детекторов можно писать отдельный пост, но вкратце мы пытаемся заставить сеть-ученика выучивать те же глобальные зависимости между фичами, которые есть в сети-учителе.
Второй метод - FKD. Снова похожее обоснование неуспешности обычных методов на детекторах, снова нелокальная дистилляция, и в целом довольно похожая статья.
Наконец, последний конкурсант - DeFeat, который тоже на основан на идее, что дистилляция бэкграунд-фичей полезна для сети-ученика. Но здесь дистиллируются уже не только фичи, но и вероятности из RPN. Аналогично фокальной дистилляции из FGD, фичи делятся на две части по бинарной GT-маске и дистиллируются с разными весовыми коэффициентами. Примерно то же самое делается и для вероятностей пропозалов из RPN.
Заканчиваем краткий экскурс в дистилляцию и возвращаемся к Teach-DETR. Напоминаю, что мы изначально в интересной ситуации - дистиллировать мы пытаемся модель Mask-RCNN, метрики которой ниже чем у DETR. В итоге все три упомянутые метода дистилляции через фичи ухудшают метрики. Идея следующая - раз архитектуры, лоссы и фичи двух сеток такие разные, давайте забьём на дистилляцию фичей и будем дистиллировать только конечные предикты - то есть, боксы.
Одна проблема всё равно остаётся - DETR использует one-to-one матчинг, и если просто добавить к GT набор предиктов Mask-RCNN, ничего хорошего не получится. Вместо этого используется идея, отдалённо похожая на Group DETR. Queries для разных групп GT-боксов (как оригинальных, так и учительских, которых может быть несколько в зависимости от количества моделей-учителей) используются одни и те же, а вот матчинг делается независимо для каждой группы. Лоссы в конце просто суммируются для всех групп.
На выходе получаем рост AP на 1 пункт по сравнению с оригинальным H-Deformable DETR. Почему это всё вообще работает? Авторы предлагают три объяснения:
- От учителя приходят в том числе новые боксы, которые не были размечены в оригинальном датасете.
- Учитель может исправлять классы для некоторых шумных боксов.
- Учитель может передавать информацию о каких-то внутренних свойствах объектов - например, насколько сложен тот или иной объект для правильной классификации или локализации.
DETRDistill (2022)
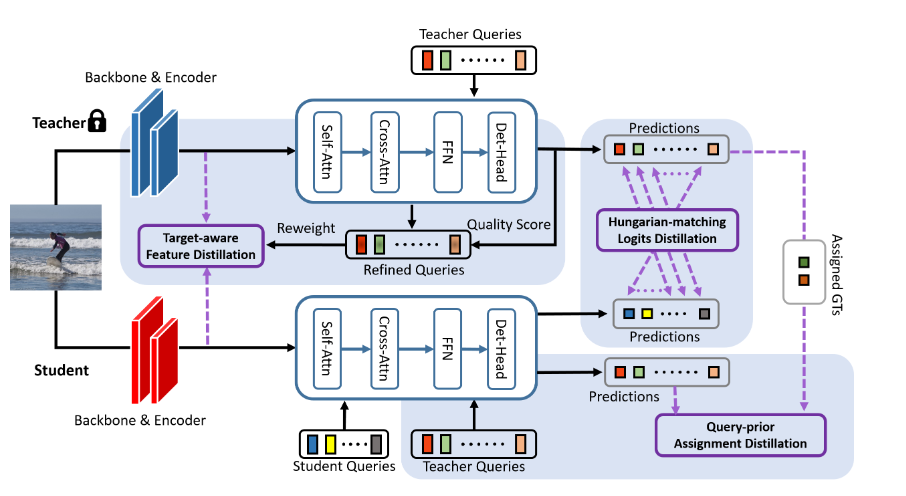
В этой статье речь идёт о дистилляции между двумя DETRами разных размеров. Помимо дистилляции на уровне фичей в качестве опции рассматривается дистилляция на уровне предсказанных лоджитов. В качестве примера приводится Localization Distillation, которая в свою очередь базируется на идее из очень любопытной статьи Generalized Focal Loss. GFL использует IoU GT-коробки и предсказанной коробки в качестве софт-таргета вероятности, а координаты объекта предсказывает как распределение вероятностей по возможным координатам. Вообще у меня очень велик сейчас соблазн свалиться в эту кроличью нору, так что пишите комментарии и ставьте лайки, если хотите больше статей про детекцию. Если не терпится, то подробнее изучить код generalized focal loss можно здесь.
Короче говоря, предлагается три компонента, отвечающих за дистилляцию. Увы, кода нет, поэтому и описание будет довольно общее.
Во-первых, используем предикты учителя как псевдо-разметку и с помощью всё того же венгерского матчинга находим лучшее соответствие между предиктами учителя и ученика. Увы, наивная имплементация не приносит много буста - ведь используются только немногочисленные позитивные предикты, которые к тому же ещё и обычно похожи на GT-коробки. Так что матчим и queries, не предсказавшие объект, и по ним тоже проводим дистилляцию. Для матчинга используются только боксы, без лоджитов. Дистиллируется отдельно каждый слой декодера (в ученике может быть и меньше слоёв).
Дистиллируются и фичи, причём вес для каждого “пикселя” увеличивается, если на него него похожи content queries, которые хорошо предсказывают объекты на данном изображении. Немного странно, что берутся не усреднённые веса из cross-attention, а именно перемножение матрицы фичей (HxWxd) и матрицы queries (Mxd).
Наконец, чтобы облегчить проблему нестабильного матчинга между GT-боксами и queries, которая уже много раз упоминалась выше, предлагается использовать стабильные, хорошие queries учителя. С помощью них генерируется матчинг GT-боксов и queries ученика. Как - я (и некоторые ревьюеры) понял не до конца, кажется, что queries учителя матчятся с GT, а queries ученика уже заматчены с queries учителя. Получаем некий транзитивный матчинг.
Метод не только докидывает при self-distillation (одинаковая архитектура учителя и ученика), но и позволяет передавать знания от моделей с большим количеством слоёв энкодера/декодера и моделей с большим бэкбоуном.
D3ETR (2022)
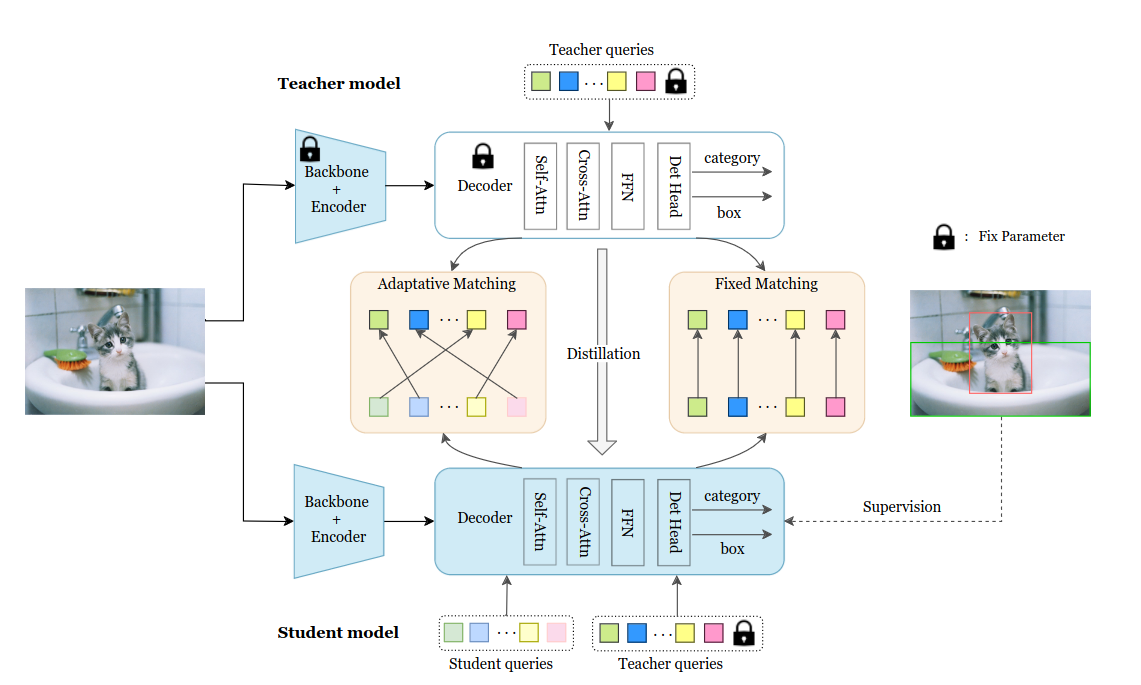
Как и в DETRDistill, в качестве главной проблемы выделяется отсутствие явного матчинга между предиктами учителя и ученика. В общем-то прям в статье написано “DETRDistill is the most related work to ours”. Для матчинга используется две стратегии:
- Адаптивный матчинг аналогично DETRDistill - матчатся предсказания с минимальной суммарной стоимостью матчинга.
- Фиксированный матчинг - к ученическим queries добавляем вспомогательные учительские, и матчим их аутпуты с аутпутами учителя (не по стоимости матчинга, а просто по индексу). Несмотря на одинаковые исходные queries, аутпуты учителя и ученика могут по-разному заматчиться с GT-коробками, поэтому для ученика используется оптимальный матчинг учителя.
Дистилляция производится на трёх уровнях - веса self-attention, веса в cross-attention, предсказания.
KS DETR (2023)
1 звёздочка
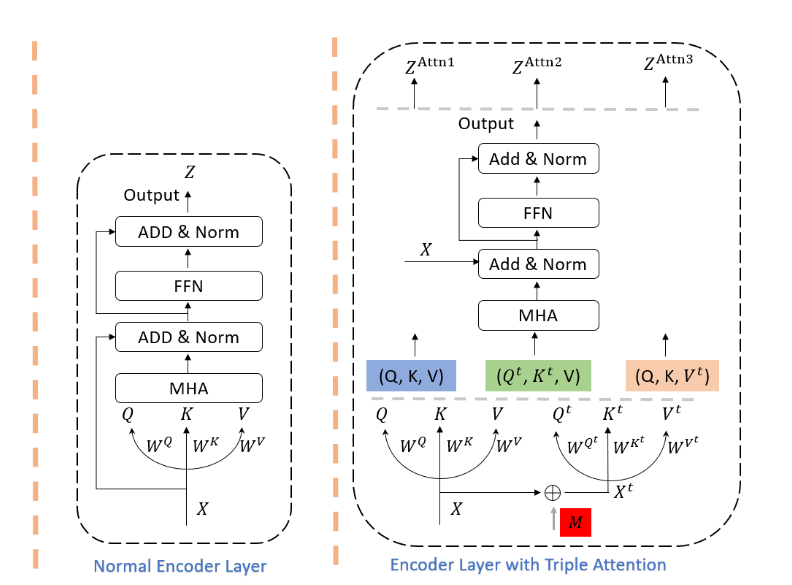
Здесь DETR дистиллирует сам себя прямо внутри энкодера. В последний энкодер-слой добавляется два дополнительных этеншна, которые прокидывают информацию в первый, основной этеншн. Лишние слои на инференсе отбрасываются.
Основная идея заключается в том, чтобы помочь энкодеру выучить более релевантные веса для этеншна. Сначала на основе известных GT-коробок генерируется бинарная маска (красный квадрат на картинке выше) - есть в конкретном “пикселе” какой-то объект или нет. Эта маска используется для обогащения входных фичей X. Бэкграунд-“пиксели” не изменяются, а “пиксели” с объектами пропускаются через линейный слой с релу-активацией. Такое вот выборочное усиление сигнала. Во второй этеншн в качестве Q и K идут обогащённые фичи, в качестве V - обычные. В третьем наоборот - обогащается V.
Получается, что второй этеншн выдаёт более качественные этешн-веса, но использует те же V, что и основной этеншн, что “заставляет” выучивать более качественные V. Третьий этеншн получает более релевантные V и шарит этеншн-веса. Все три аутпута отдельно прогоняются через декодер, затем считается суммарный лосс. Читаю я, конечно, это описание - выглядит как бред сумасшедшего.
Но в целом идея не очень сложная - используем GT-разделение на FG и BG для ускорения обучения. Такая процедура позволяет этеншну легче обучаться, куда обращать внимание - ведь чаще всего нам нужны именно foreground-”пиксели” с объектами.
###
С облегчением
DETR, особенно оригинальный, является достаточно тяжёлой архитектурой. Cross-attention, несколько слоёв энкодера и декодера - всё это ведёт к высокой вычислительной сложности. Статьи в этом разделе предлагают способы решения именно этой проблемы.
Sparse DETR (2021)
44 цитирования, 133 звёздочки
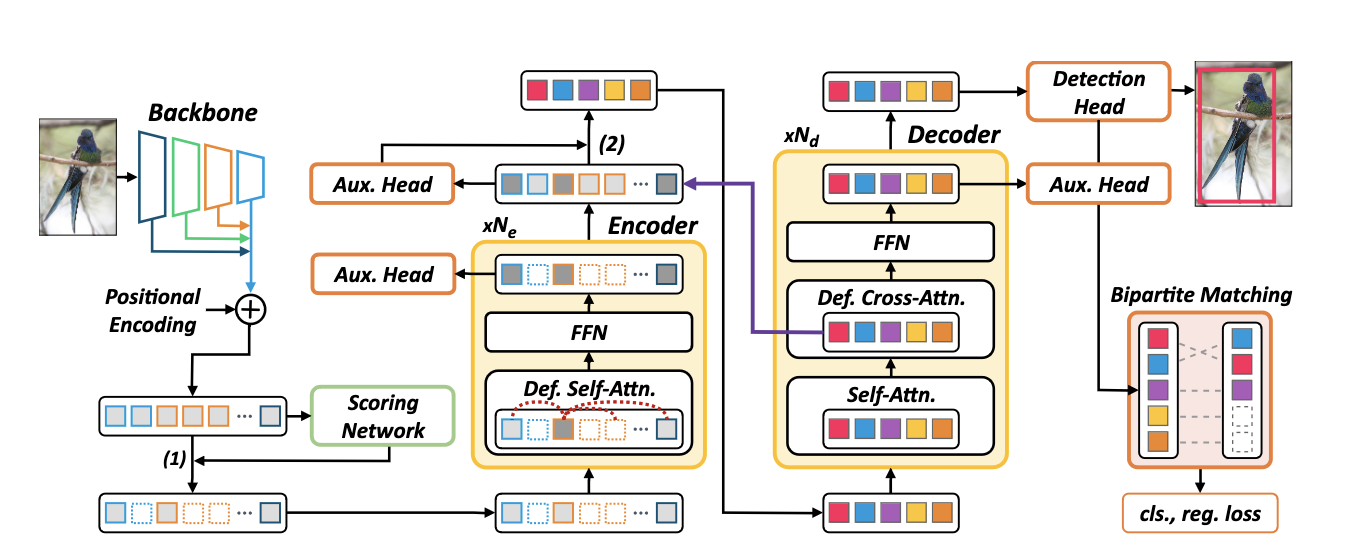
Очень симпатичная статья с несложной идеей. Казалось бы, Deformable DETR решает проблему квадратичных вычислений в энкодере - теперь каждый токен этендится на фиксированное число токенов вне зависимости от размера картинки. Однако, инференс при этом становится медленнее! Как так?
Причина кроется в использовании multi-scale пирамиды фичей - в ней тупо очень большое число токенов. А нужно ли нам действительно их все обновлять в энкодере? На самом деле нет, ведь декодер смотрит на довольно ограниченное количество токенов - в основном на те, где есть какие-то объекты. Если мы сможем найти эти токены, то можно в энкодере обогащать глобальной инфой только их, и тем самым сэкономить нехилое количество вычислений.
Сделать это можно как-нибудь простым способом - например, с помощью RPN-модуля, который будет предсказывать по CNN-фичам, где находятся важные токены. Но это не очень хорошо, не факт, что мы сможем найти все токены, на которые важно будет смотреть декодеру. Авторы предлагают очень элегантное решение - давайте просуммируем все этеншн-веса со всех слоёв декодера и обучим сетку, которая по тем же CNN-фичам будет предсказывать, на какие токены будем смотреть этеншн. Для ванильного DETRа просуммировать эти веса очень просто, для Deformable DETR лишь капельку сложнее.
На каждой итерации будем суммировать эти веса и выбирать фиксированный процент самых важных токенов со всех уровней пирамиды. Этим токенам присваиваем лейбл 1, остальным - 0, и накладываем на предикты обычный BCE-лосс. Всё, теперь у нас есть модуль, который позволяет предсказывать токены, на которые, скорее всего, будет обращать внимание декодер. С целью экономии ресурсов “неважные” токены в энкодере обновлять не будем (то есть, не будем включать их в множество Q), но них могут этендиться “важные” токены - таким образом может происходить передача от невыбранных токенов к выбранным.
В общем-то это основная идея. В качестве дополнительных фишек предлагается:
- Добавить вспомогательные лоссы не только в декодер, но и в энкодер. Каждый “важный” токен на каждом слое будет предсказывать какую-то коробку, и мы можем накладывать обычный matching loss.
- Аналогично Efficient DETR предлагается инициализировать content queries из аутпута энкодера. Для этого мы можем взять top-k токенов согласно предсказанию дополнительной objectness головы.
Оказывается, что даже используя всего лишь 10% токенов, можно получить результаты аналогичные Deformable DETR.
PNP-DETR (2021)
30 цитирований, 123 звёздочки
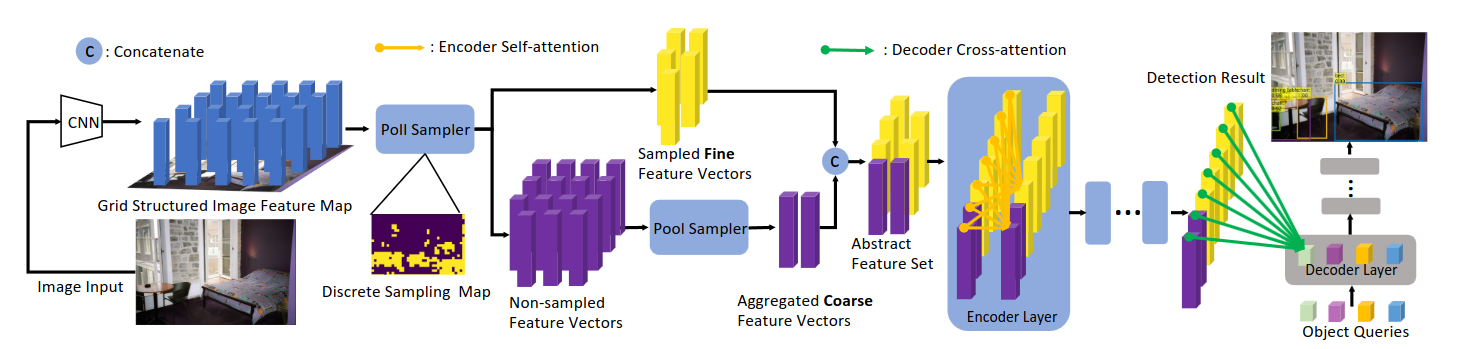
В большинстве доменов картинки в основном состоят из бэкграунда без объектов. На эти области тратится большое количество вычислений в self-attention энкодера и в cross-attention декодера. При этом в бэкграунде всё-таки может содержаться полезная для детекции информация, хотя и в избытке. Поэтому в отличие от Sparse DETR авторы предлагают не отказываться от бэкграунда целиком, а компактнее упаковать его перед подачей в трансфомеры.
Первый новый модуль называется Poll Sampler. Это небольшая сеточка (конв-релу-конв-сигмоид), которая выдаёт скоры для каждого “пикселя” CNN-признаков. Сортируем все признаки (предположим, их L= H*W) по убыванию скора, берём топ-N из них - это наши основные фиче-векторы, на которых, вероятно, содержатся объекты. Отобранные фичи пропускаются через LayerNorm и домножаются на скор, чтоб Poll Sampler мог обучаться через бэкпроп (через индексы torch.topk градиент не течёт). N фиксирован и не зависит от картинки, хотя авторы и подмечают, что для разных картинок может быть оптимальным разное количество фичей.
Второй модуль называется Pool Sampler. В нём и заключается основная фишка архитектуры, он нужен для того чтобы собрать информацию из большого количества неотобранных фичей (K = L - N) и агрегировать их в M новых фичей такой же размерности, где M - какое-то небольшое число, скажем, 60. Эти K фичей пропускаются через ещё одну сеточку (линейный-релу-линейный), которая для каждой фичи выдаёт вектор из M весов. Далее софтмакс нормализует их по измерению фичей. То есть, если взять первый элемент этого вектора для каждой из фичей, то их сумма будет равна единице. Затем K неотобранных фичей пропускаются через линейный проекционный слой. Наконец, с помощью полученных векторов весов M раз складываем с разными весами K фичей. На письме звучит заумно, но идея по факту не такая сложная - разными способами агрегируем большое количество бэкграунд-фичей, чтоб получить их более сжатую репрезентацию. Positional-энкодинги для этих фичей получаются аналогичной агрегацией с использованием тех же весов.
Результаты работы Poll Sampler и Pool Sampler просто напросто конкатенируются и подаются в энкодер. На картинке справа изображены карты плотности весов. Отобранным фичам из Poll Sampler присваивается вес 1, а для остальных берётся суммарный вес из Pool Sampler. Мы видим, что большая часть выбранных фичей относится к объектам, а также используются некоторые бэкграунд-локации.

L-DETR (2022)
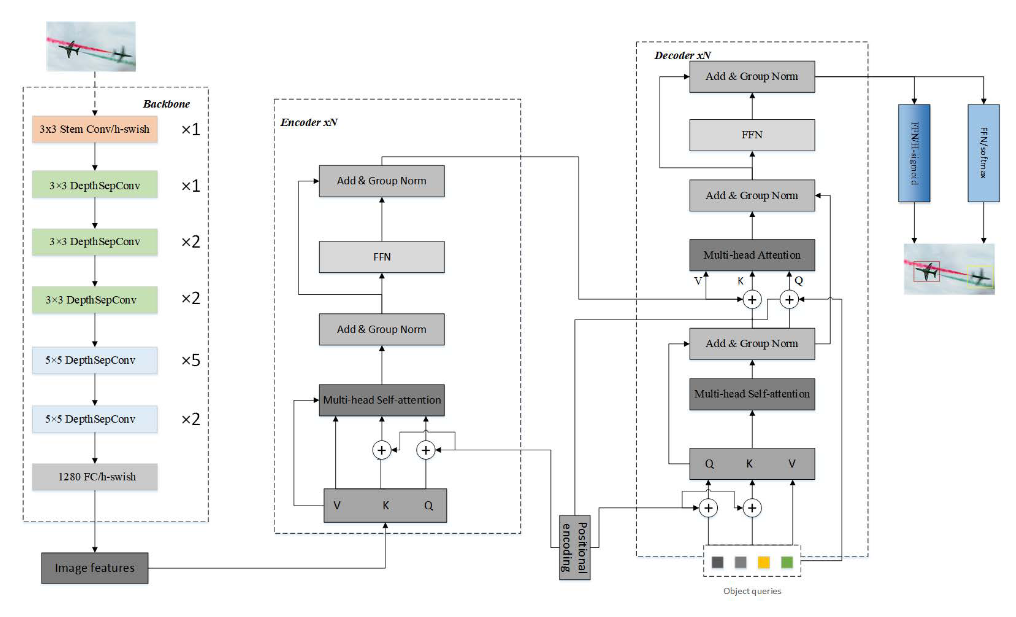
DETR можно облегчить просто - например, снизить количество слоёв энкодера и декодера, не использовать уровни фича-мап с большим разрешением, уменьшить размер feedforward-слоёв. Всё это снижает метрики, но часто не сильно.
Авторы L-DETR предлагают ещё пару несложных идей:
- Заменить бэкбоун на более лёгкий, основанный на архитектуре PP-LCNet (для скорости)
- Заменить релу-активации в трансформере на hard-версии из MobileNetV3 (для стабильности обучения и частично для скорости)
- Заменить layer normalization на group normalization в декодере
Lite DETR (2023)
2 цитирования, 103 звёздочки
Описание будет добавлено на этой неделе
Архитектурные трюки
В этом разделе собрались DETRы с разными архитектурными трюками, которые не попали ни в одну из групп. О каких-то расскажу подробнее, о каких-то - коротко, а то статья уже подкатывается к ста тысячам знаков…
WB-DETR (2021)
15 цитирований
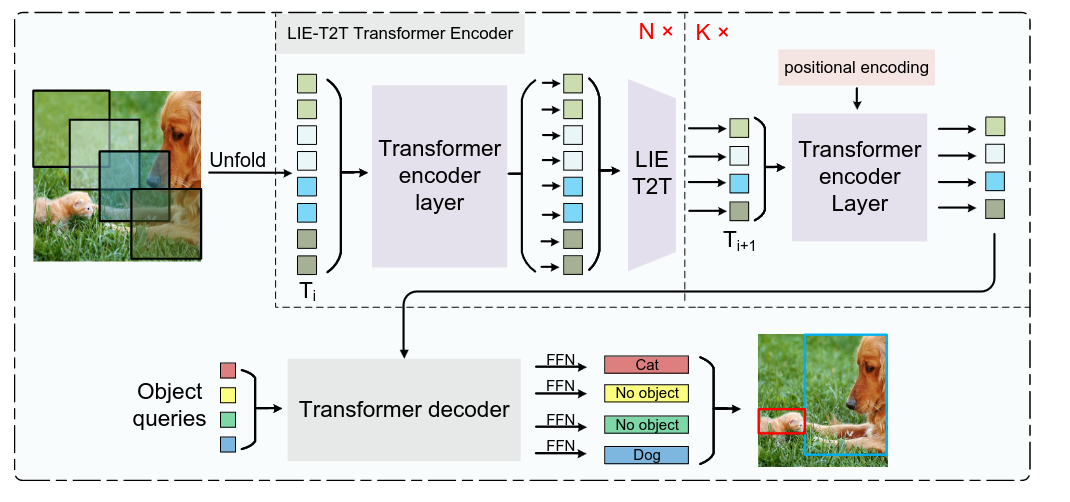
Попытка выкинуть CNN из игры - оставляем только энкодер и декодер, при этом энкодеру на вход идут патчи оригинального изображения как в ViT. Давайте покопаемся в архитектуре:
- Первым делом режем картинку на патчи одинакового размера (можно с перекрытием), делаем их плоскими и прогоняем через линейную проекцию, чтоб привести к желаемой размерности. К получившимся токенам прикрепляем обучаемые positional embeddings.
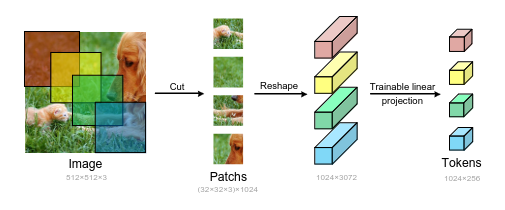
- При такой схеме обработки картинки локальная информация хранится только внутри токена. В теории токены могут обмениваться информацией, но в любом случае понятно, что моделирование локальной информации в таком подходе хуже, чем с использованием CNN. Это может быть критично для задачи детекции. Для решения этой проблемы в конце каждого слоя энкодера добавляется специальный модуль LIE-T2T. Он основан на модуле T2T, который работает очень просто - токены обратно собираются в матрицу, соседние патчи окном с перекрытием собираются в длинные токены (длины kxkxc, где k - сторона окна, на картинке k=2). Для усиления определённой локальной информации внутри токенов поверх обычного T2T на эти длинные токены дополнительно накладывается этеншн на каналы (а-ля Squeeze & Excitation). После этого токены можно вернуть в нужный размер линейной проекцией. Сама размерность фиче-мапы при этом будет уменьшаться, в статье ничего про это не говорится, но в T2T используется паддинг, полагаю, что и тут тоже.
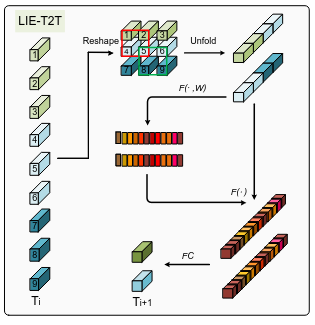
Такие дела. Количество параметров падает, метрики не хуже, LIE-T2T докидывает по сравнению с T2T.
Miti-DETR (2021)
8 цитирований, 2 звёздочки
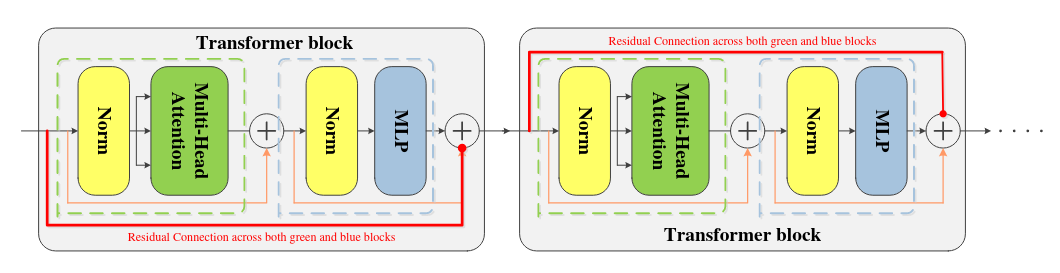
Статья, полностью основанная на выводах другой статьи с очень необычным названием Attention is Not All You Need. Оказывается, если из self-attention сетки убрать skip-connection и MLP, то её аутпут с большой скоростью скатывается к матрице с рангом 1, то есть, по сути все её строчки становятся одинаковыми независимо от инпута. На картинке ниже изображена стандартная self-attention сеть с H головами этеншна, между слоями обычно вставляют MLP (в оригинальном DETR с двумя линейными слоями).
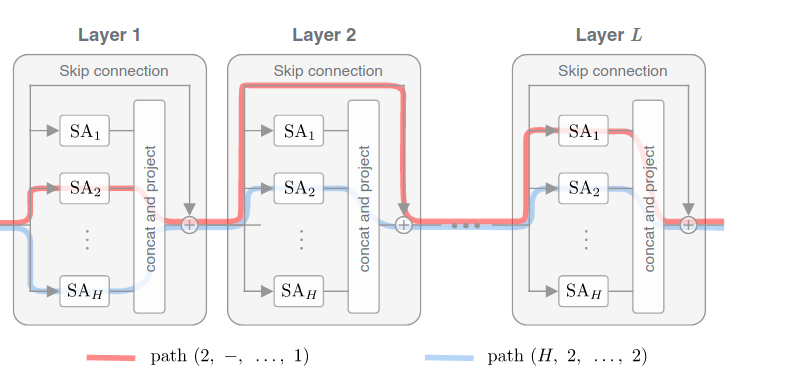
Дальше следует немалое количество линейной алгебры, которое ведёт к тому, что результат работы такой сети с L слоями можно представить в виде суммы результатов работы всех возможных “путей”:
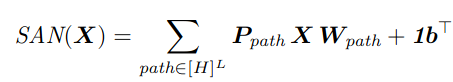
На картинке два разных “пути” обозначены красным и синим цветом. Например, из первого слоя мы берём результат работы второй головы этеншна, на втором идём через скип-конекшн и так далее. Таким образом, такую сеть можно интерпретировать как ансамбль более простых сетей с одной (или нулём) этеншн-головой в каждом слое.
Благодаря такой декомпозиции, можно облегчить анализ работы сетки и рассматривать упрощённую сеть с одной головой. Возьмём инпут-матрицу X и найдём для неё такой вектор x, который при вычитании из каждой строчки X, минимизирует L2-норму полученной матрицы (она здесь называется residual). Если эта норма в какой-то момент будет равна 0, это значит, что все строчки матрицы идентичны. Так вот, оказывается, что в чистых self-attention-сетях норма residual убывает с двойной экспоненциальной скоростью, соответственно и ранг X быстро скатывается в 1.
А skip-connection как раз помогает решить эту проблему - например, существует путь, который пропускает вообще все слои self-attention и множество неглубоких путей, которые используют только несколько голов этенша.
Возвращаясь к Miti-DETR - само изменение очень-очень простое, несмотря на относительную сложность лежащей за этим математики. По сути, в каждом слоё энкодера и декодера мы просто добавляем к выходу слоя его вход. Демонстрируется, что это ускоряет convergence и улучшает метрики по сравнению с ванильным DETR.
CF-DETR (2021)
7 цитирований
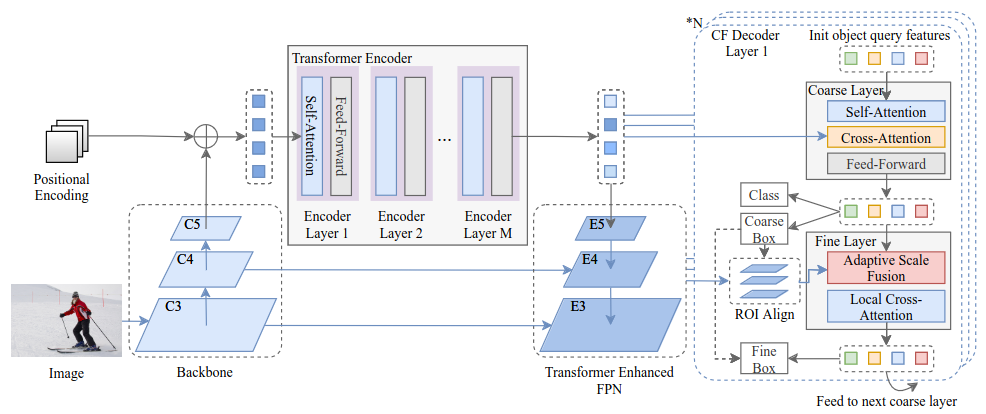
Сравнение всех моделей детекции всегда проходит одинаково - берём COCO и считаем AP@[.50:.05:.95] - то есть average precision с IoU-порогом от 0.5 до 0.95 с шагом 0.05. Такой выбор метрики благоволит моделям, которые очень точно локализуют боксы объектов. В этой статье предлагается очень разумная вещь - давайте посмотрим, как ведут себя модели на другом диапазоне IoU-порогов - например, с 0.1 до 0.5. Вообще, проблеме корректного выбора метрик уделяется слишком мало внимания - подробнее можно почитать здесь, здесь и здесь.
Так вот, оказывается, что при низких IoU-порогах DETR работает на маленьких объектах так же или даже лучше, чем классические детекторы Faster-RCNN и Sparse-RCNN. То есть, DETR нормально находит любые объекты, но не может их точно локализовать. Если для вашей задачи нужна корректная локализация небольших объектов - можно посмотреть на этот подход. Сама статья написана нудновато, постоянно везде в тему и не в тему суют слово “novel”, но в целом идея достаточно простая.
Основная идея - добавить в архитектуру несколько модулей, которые будут обогащать DETR локальной информацией и позволять более точно предсказывать координаты коробок:
- Первый модуль на картинке называется “Transformer Enhanced FPN”. По сути, это обычный FPN, но фичи последнего уровня берутся из трансформер-энкодера. Следующий уровень (четвёртый) собирается из этих фичей и CNN-фичей того же уровня. По итогу получается пирамида фичей, обогащённая одновременно глобальными фичами энкодера и локальными CNN-фичами каждого уровня.
- Декодер начинается как обычно - self-attention + cross-attention. По итогу получаем предикты координат, которые мы называем “coarse”, то есть грубые. Теперь мы хотим их уточнить с помощью некоего fine-слоя.
- Аналогично классическим двухстадийным детекторам, мы с помощью coarse-координат и модуля RoIAlign можем спулить нужные фичи из пирамиды. Вместо использования эвристики для выбора уровня пирамиды используется особый модуль Adaptive Scale Fusion, который агрегирует RoI-фичи, спуленные со всех уровней. При этом используется информации из object query.
- Наконец добавляется модуль local cross-attention, который выполняет роль обычного cross-attention, на спуленных локальных фичах. В качестве Q выступает object query (кажется, используется сумма positional и content, как в оригинале), расширенный до размеры фича-мапы, в качестве K - фичи после depthwise-конволюции, в качестве V - фичи после 1x1-конволюции. Почему так сложно? Да бог его знает, якобы для облегчения использования локальной информации. В итоге мы получаем аутпут декодера, обогащённый локальной информацией.
- Эти дополнительные слои можно повторять несколько раз внутри одного слоя декодера. Да, я сам немного в шоке. Итоговые лоджиты берутся из последнего coarse-слоя, а коробки - из fine.
Вот такая вот несколько запутанная статья, но мне понравилась изначальная мотивация - поглубже изучить метрику и понять, в чём конкретно проблема (как в фреймворке TIDE).
DETR++ (2022)
3 цитирования
Я не очень понял, почему эта статья вышла в 2022, почему в ней не цитируются многие другие и много чего ещё не понял. Суть крайне простая - берём BiFPN-слой и накладываем его несколько раз на пирамиду фичей. В энкодер в итоге идёт последний уровень C5, обогащённый информацией из других слоёв пирамиды. Эту идею они сравнивают с несколькими другими вариациями, но особого внимания они не стоят. BiFPN докидывает на маленьких объектах по сравнению с ванильным DETR.
Backpropagating through Hungarian (2022)
Интересная деталь - форвард-пасс венгерского матчера в DETR обёрнут в torch.no_grad(). Действительно, венгерский матчинг - это комбинаторный оптимизационный алгоритм, и градиент через него не прокинуть. Вместо этого мы находим оптимальный матчинг, и используем только его, игнорируя
В этой статье рассматривается очень интересный вопрос - а можно ли честно оптимизировать сетку, если она содержит модуль с комбинаторной оптимизацией? В статье есть отдельная секция, посвящённая разным способом решения этой задачи. Метод, который в итоге используется, описан в статье Differentiable Combinatorial Losses through Generalized Gradients of Linear Programs.
Есть проблема - метрики с таким лоссом получаются намного хуже. Но мне всё равно статья показалось достаточно любопытной, так что решил её включить.
DESTR (2022)
7 цитирований
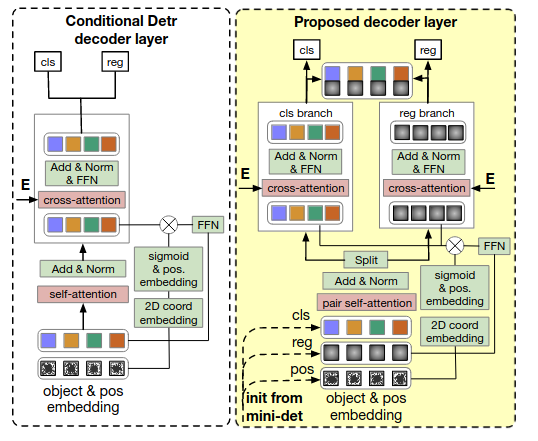
Вариант Conditional DETR с тремя основными модификациями:
- Для генерации референс-точек и content queries используется отдельный мини-детектор, который навешивается на фичи энкодера. В данном случае используется FCOS.
- Cross-attention в каждом слое декодера делится на две части - одна отвечает за классификацию, а другая за локализацию.
- Самое эзотерическое изменение - self-attention в декодере превращается в некий pair self-attention. Идея такая - обычно наибольшее влияние на object query оказывает его ближайший сосед. Помимо этого, этеншн-вес между двумя объектами обычно снижается, если один из объектов частично закрыт каким-то соседним объектом. В общем, для каждого query находится его ближайший сосед (по IoU между предсказанными боксами), и этот сосед конкатенируется к object query, и attention вычисляется между этими парными репрезентациями.
Все три изменения суммарно добавляют почти три пункта AP по сравнению с ванильным Conditional DETR.
Honorable mentions
Хоть я и обещал рассказать только об обычной 2D-детекции, несколько статей всё-таки захотелось упомянуть.
What makes for end-to-end object detection? (2022)
Что позволяет DETRу (почти) не делать дублированных предиктов в отличие от классических детекторов? Ответ кажется очевидным - one-to-one матчинг между предиктами и GT (см. NMS Strikes Back (2022)) и self-attention. На самом деле ситуация чуть интереснее
Авторы заменяют one-to-many матчинг на основе IoU в RetinaNet, CenterNet и FCOS на one-to-one матчинг. Например, в RetinaNet в качестве единственного позитивного сэмпла для каждой GT-коробки берётся бокс с наибольшим IoU. Любопытно - при такой схеме обучения NMS всё ещё заметно повышает метрики. Оказывается, что дело не только в схеме матчинга, но и в критерии, по которому рассчитывается стоимость матчинга. В DETR при нахождении оптимального матчинга учитывается не только степень пересечения коробок, но и корректность предсказания класса. Если изменить критерий, и использовать не только IoU, но и предсказанные вероятности, то классические детекторы практически перестают предсказывать дубликаты. Такая модификация и отказ от NMS позволяют значительно поднять метрики на датасетах с большой плотностью объектов
Хорошее напоминание, что стоит изучать каждый компонент вашей сетки и подгонять его под вашу задачу. Например, в некоторых медицинских задачах для матчинга предиктов и GT-боксов можно использовать Boundary IoU или Intersection-over-Reference.
AO2-DETR (2022)

Модификация DETRа для решения задачи детекции, где коробки могут быть повёрнуты на любой угол. Я когда-то подумывал использовать Oriented-RCNN в задаче детекции полей на повёрнутых документах, но в итоге мы поступили проще - предварительно стали выравнивать сам документ. Но задача более чем актуальна для детекции объектов на спутниковых изображениях.
Основная идея тут такая же - просто добавляем угол поворота в список аутпутов, которые должна предсказывать сетка. Есть, конечно, куча нюансов - например, конволюционные фичи не очень приспособлены для по-разному повёрнутых объектов, которые ещё и имеют разный размер, так что авторы добавляют специальные модули, которые обогащают исходные фичи с учётом пропозалов, сгенерённых сеткой.
Omni-DETR (2022)
Интересный фреймворк для обучения, основанный на DETR. Он позволяет использовать любые аннотации, которые есть в наличии - точки на объектах без классов и с классами, классы без локализации, коробки без классов, количество объектов каждого типа. Поверьте, такой зоопарк лейблов встречается в медицине сплошь и рядом.

В сеть-учитель поступает исходное изображение с лёгкой аугментацией, для которого генерируется обычное предсказание - коробки и классы. Это предсказание фильтруется с помощью разметки, которая доступна для этой картинки. У нас есть K предсказаний и G каких-то лейблов, нам нужно найти оптимальный матчинг между ними, и оставить только те боксы, которые заматчились с GT-разметкой. Например, если мы знаем, что на изображении находятся три овцы и лошадь, то мы оставляем три топовых бокса для овец и один для лошади. Если нам дополнительно известна точка на объекте, то к стоимости матчинга добавляется расстояние между центром предикта и этой точкой. В общем, для любой комбинации слабых лейблов можно найти множество предиктов, которое лучше всего ему соответствует. Эти предикты и становятся GT-разметкой для сети-ученика, в которое поступает изображение с сильной аугментацией.
Мы у себя использовали такую фильтрацию для генерации псевдо-разметки, которая не противоречит известной слабой разметке (например, заключению врача). В общем-то, для реализации такой схемы обучения совсем необязательно использовать DETR.
Points as Queries (2021)
Ещё одна идея, направленная на использование более дешёвой разметки - предлагается вместо коробок использовать для каждого объекта любую точку внутри этого объекта. Для использования такой разметки вводится дополнительный модуль, который трансформирует точки в object queries.
HOI Transformer (2021)
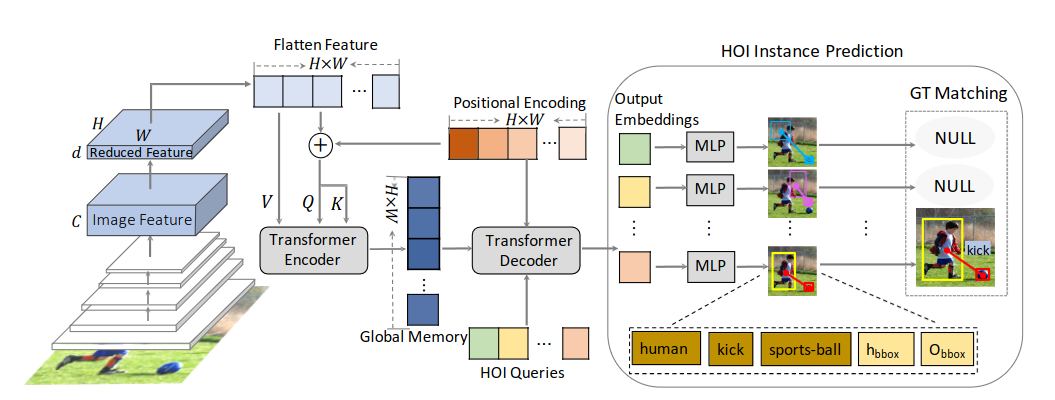
Модификация для предсказания взаимодействия между людьми и объектами (human object interaction, HOI). Архитектурно всё достаточно просто - object queries заменяются на HOI queries, по которым затем предсказываются бибоксы человека, объекта, и конфиденсы человека, объекта и действия. Оптимальный матчинг тоже находится по всем пяти предиктам.