Будущее ИИ в рентгенологии
Будущее ИИ в рентгенологии
В конце октября вышла статья “The Future of AI and Informatics in Radiology” под авторством Кёртиса Ланглотца, профессора радиологии и биомедицинского data science в Стэнфорде. Она содержит 10 предсказаний о будущем ИИ в нашей индустрии. Хочу по ним пробежаться и поделиться своим видением текущей ситуации.
Radiology Will Continue to Lead the Way for AI in Medicine
Говорим “ИИ в медицине”, держим “ИИ в рентгенологии” в уме. Во многом это правда - медицинские изображения продолжают генерировать внушительное количество статей, выступлений, обсуждений, датасетов. При этом больше половины российских регионов в этом году закупили системы не рентгенологические ИИ-системы, а предиктивную аналитику по электронным медицинским картам (предсказание вероятности возникновения сердечно-сосудистых заболеваний). В этом году также сильно перетянули на себя внимание медицинские LLMки - их хватило уже аж на целый обзор.
Но, пожалуй, с точки зрения стадии взросления, количества преодолённых проблем, ожидаемого экономического эффекта, понятных сценариев применения, картиночные системы продолжают быть в авангарде продуктового медицинского ИИ. Всё-таки задача поиска определённых паттернов на 2D и 3D-изображениях очень хорошо приспособлена для решения с помощью ML. К тому же, ИИ отлично закрывает частые причины ошибок врачей - усталость и большая нагрузка, “слепые пятна” на исследованиях, когнитивные искажения. При этом ИИ всё ещё порядочно уступает врачу в плане способностей агрегировать всю информацию о пациенте и выдавать хорошие рекомендации лечащему врачу.
В общем, AI in medical imaging уже не на волне хайпа, но точно с нами надолго.
Virtual Assistants Will Draft Radiology Reports and Address Radiologist Burnout
В этом году мы очень постарались сделать наши текстовые отчёты максимально стандартизированными и более удобными для врача. Для этого понадобилось большое количество доработок - добавление новых классов, дополнительных функций, а ещё мы перенесли генерацию текста на сторону ML для гибкости и скорости разработки и более полного тестирования.

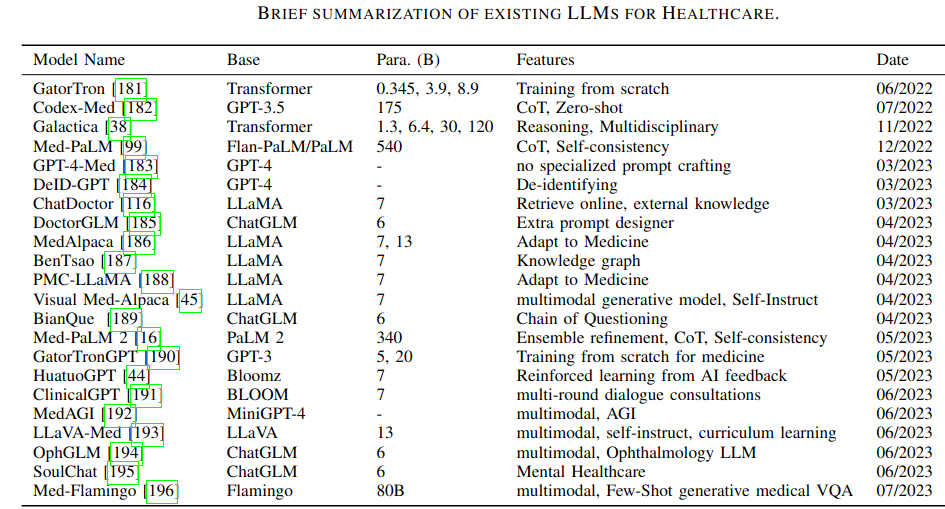
Пример протокола по ММГ
В статье предполагается, что текстовые отчёты будут генерироваться с помощью LLM на основе предиктов картиночных нейронок. С этим мне пока согласиться сложно. Я не очень понимаю, какие преимущества LLM дают по сравнению с детерминированным алгоритмом генерации, а вот потенциальные проблемы лежат на поверхности (галлюцинации и всё такое). В теории можно предположить вариант с суммаризацией текстового отчёта, истории болезни и направления терапевта на исследование, но и тут я пока не готов сделать ставку исключительно на LLM.
An Intelligent Image Interpretation Cockpit Will Become as Pervasive as Email
В этом предсказании описан красивый пайплайн работы рентгенолога. Всё развёрнуто в облаке, к моменту начала работы врача уже всё сегментировано, описано, измерено и сгенерирован первый вариант отчёта. Все эти измерения можно на лету отредактировать голосом или парой кликов.
В принципе в некотором виде этот процесс работы уже существует, но куда же без сложностей:
- До сих пор существуют большие непонятки со стандартизацией формата хранения результатов работы ML-сервисов. На данный момент у нас 100% интеграций сделано через комбинацию Secondary Capture (SC) + Structured Report (SR). Проблема SC в том, что это отдельное RGB-изображение - полная копия исходного исследования с нанесённой на него разметкой. Это позволяет генерировать красивые картинки, но значительно утяжеляет коммуникацию между медицинском учреждением и ИИ-сервисом и требует больших затрат на хранение. В DICOM-формате существуют другие, очень лёгкие способы хранения различных видов разметки (классификация, сегментация, детекция), и даже есть питоновские библиотеки, которые позволяют удобно с ними работать. Увы, пока с этим никто особо не хочет запариваться, но, думаю, всё впереди. Ещё одна альтернатива - использование платформ типа deepc, которые берут интеграцию между больницами и ИИ-вендорами на себя. В этом случае разработчику достаточно предоставить результаты работы в формате JSON, а генерацию всех репортов в нужном формате берёт на себя платформа.
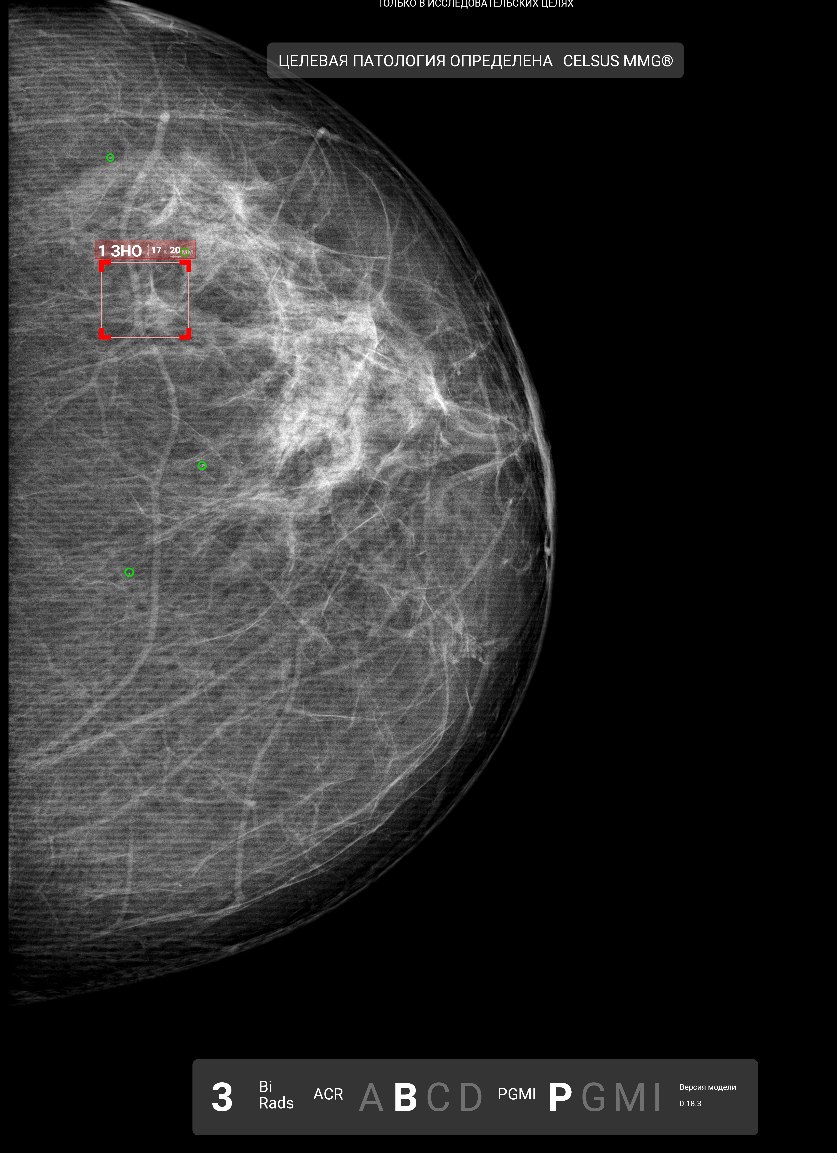
Пример SC-файла
- Популярной схемой в регионах остаётся локальное развёртывание на физической машине в контуре клиента. Это даёт определённые преимущества (например, скорость обмена данными и инфобез), но при этом и затрудняет всякие модные облачные сценарии взаимодействия, а также мониторинг качества работы ИИ-систем.
Highly Sensitive AI Will Reduce the Need for Human Image Interpretation
Идея этого сценария работы проста - часть исследований может обрабатываться автоматически, без какого-либо участия врача. Особенно это актуально для сценариев массового скрининга, где подавляющее количество исследований не содержит патологию и не представляет большой сложности в плане интерпретации.
По итогам 3 квартала этого года наш сервис по флюорографии обработал в сценарии “highly sensitive AI” более 60к исследований. Чувствительность сервиса составила 99.93% при автоматической генерации заключения “без патологии” для 67% исследований. При этом пересмотр врача-эксперта подтвердил расхождение только для 40% из этих 0.07% расхождений. Иными словами, сервис автоматически присвоил категорию “норма” более 40к исследованиям, при этом было допущено около 15-20 ошибок.
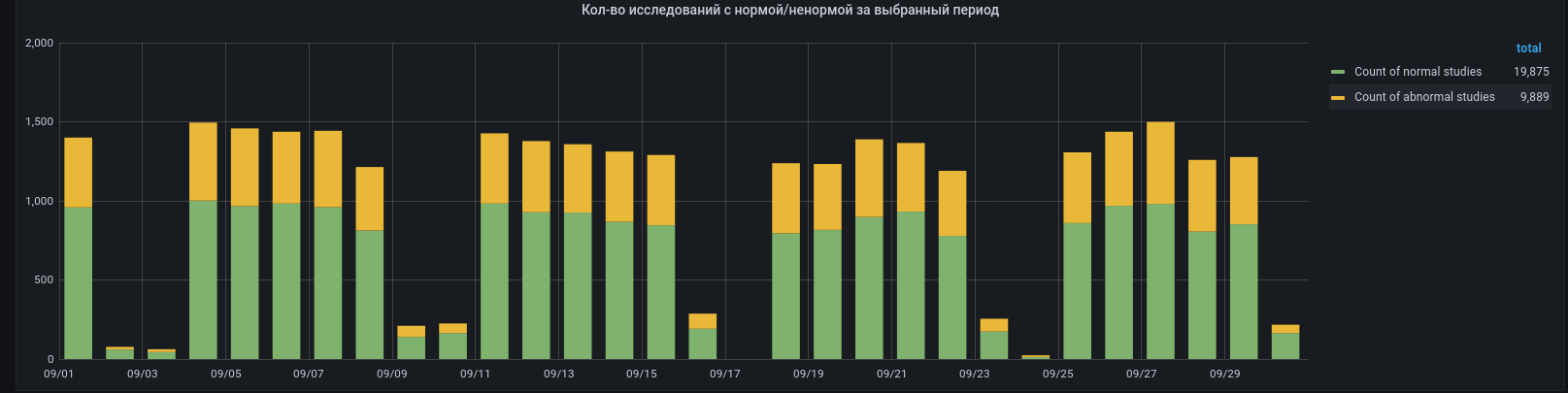
Статистика за сентябрь
Барьеров для полноценного внедрения ещё немало - нужно ещё сильнее улучшать чувствительность (в основном решать проблемы со всякими сложными случаями и редкими патологиями) и понять, что делать с точки зрения ответственности разработчиков в случае ошибки, но перспективы реального применения автономных сценариев явно вышли из области фантастики.
LLMs Will Transform Patients’ Understanding of Radiology
Пожалуй, единственное применение LLM в рентгенологии, которое мне на данный момент видится реальным. Когда я делал МРТ колена, голеностопа и поясницы, мне каждый раз приходилось гуглить, что же у меня там такое нашлось, и что с этим делать. В идеале это, конечно, должен пояснять врач, но не всегда это возможно, к тому же любопытным пациентам часто хочется перепроверить всё самим. В общем, “перевод” с медицинского на русский - направление перспективное.
Multimodal AI Will Discover New Uses for Diagnostic Images
Искренне верю и давно хочу поработать с мультимодальными данными (простой пример приводил выше - агрегация текстового отчёта об исследовании, истории болезни пациента и заметок с приёма пациента), но всё упирается в их фактическое отсутствие у разработчиков. Самое похожее, что у нас реально есть на руках в адекатных объёмах - это пары “картинка - заключение врача”, но с этим особо каши не сваришь. Есть мнение, что на самом деле даже и неплохо, что ИИ описывает только визуальную информацию, не ориентируясь на априорные данные. Но всё-таки верится, что мультимодальность позволит совершить рентгенологическому ИИ следующий большой скачок.
Online Image Exchange Will Reduce Health Care Costs by over $200 Million Annually
Звучит правдоподобно. Экспертом здесь не являюсь, так что и комментировать не буду.
Reformed Regulations Will Accelerate AI-based Improvements in Care Delivery
На данный момент обновление регистрационного удостоверения на медицинское изделие занимает не менее полугода. То есть, каждое обновление нейронки - от переобучения до изменения формата отчёта, в теории должно сопровождаться долгим и муторным процессом обновления сертификации. Все в индустрии понимают, что нужно что-то менять. FDA предложило документ, посвящённый этой проблеме, российский набор ГОСТов по ИИ в медицине тоже затрагивает эту проблему. Дело за малым - имплементировать возможность быстрого обновления версии на практике. Тем более, что есть хороший опыт Московского эксперимента.
Отдельно хотел бы отметить важность прозрачности в этом процессе. Наличие подробной документации, описывающей сами ИИ-системы, процесс и результаты их тестирования, процедуру переобучения и использованные набора данных значительно снижает риск появления критических ошибок при обновлении версии алгоритма. В рамках процедуры подготовки к получению ISO 13485 мы пересмотрели процесс документирования тестирования новых версий систем. Все релизы делятся на minor и major. Minor-версии (без изменения метрик качества) сопровождаются релизным чек-листом, а к major-версиям прилагается обязательный отчёт по тестированию и техническое задание.
A Widely Available Petabyte-scale Imaging Database Will Unleash Unbiased AI
За время существования компании мы накопили уже четверть петабайта данных. Прямо сейчас находимся в размышлениях, что со всем этим делать, нужны ли нам все данные, и какие политики хранения внедрить, чтобы не тратить каждый месяц мешок денег. Разговоры о каком-нибудь безумном претрейне то и дело возобновляются (прямо сейчас я пробую обучить свой DINO на всём объёме неразмеченных маммографических данных), но по факту обычно не хватает ни времени, ни вычислительных ресурсов. Время от времени в опенсорсе появляются всякие штуки типа MedSAM, но обычно (кажется) выгоднее вложиться в создание качественных датасетов под свои нужды и их улучшение. Рано или поздно ситуация, наверное, изменится, но пока претрейны в опенсорсе не являются панацеей от всех проблем.
Flexible and Collaborative Academic Organizations Will Lead AI Innovation
Пункт про важность интердисциплинарных команд поддерживаю обеими руками. В каждой ML-команде сейчас есть врач, который активно участвует в работе: отвечает на вопросы команды, мониторит поток, генерирует гипотезы, выстраивает процесс разметки.
При этом слабо себе могу представить, чтобы на данный момент эти команды возглавлялись врачами, и чтобы в них в обязательном порядке присутствовали специалисты по этике, экономисты и философы. Эти специалисты нужны для изменения регуляторики, сопровождения внедрения и других подобных задач, но непосредственно разработка сейчас базируется на ML-компетенциях с консультативной поддержкой со стороны медицины.
Что касается главенства университетов в развитии области - не знаю. Безусловно, есть пример моего родного NYU, у которого есть куча данных, специалистов, вычислительных мощностей и возможностей для партнёрства с медицинскими организациями, но я уверен, что коммерческие компании играют и продолжат играть очень важную роль в реальном прониковении ИИ в сферу рентгенологии.