Матожидание количества успешных гипотез
Матожидание количества успешных гипотез
В наших проектах самая важная цель часто формулируется очень просто - “поменьше ложноположительных, поменьше ложноотрицательных”. Короче, нужно повышать метрики модели. Однако, если постоянно брать только задачи на повышение метрик, проект в итоге может оказаться в достаточно плачевном состоянии:
- неистовые ML-эксперименты имеют свойство снижать среднее качество кода на проекте
- вечная гонка за метриками не даёт возможности отдышаться, посмотреть на архитектуру всей системы свежим взглядом, изучить что-то новенькое
- иногда задачи, которые не дают буст метрик прямо сейчас, могут дать мощный долгосрочный эффект
Если упрощать, то в любой момент время команда распределяет свои усилия между двумя направлениями:
- проверка гипотез на улучшение метрик или добавление новой функциональности
- задачи или другая деятельность, которые могут повысить скорость проверки гипотез или добавления фичей в будущем, а также среднее качество гипотез
Одна из важных обязанностей ML-лида - поддерживать правильный баланс между этими ветками в каждый момент времени. При этом баланс может меняться в зависимости от обстоятельств - краткосрочные и долгосрочные бизнес-цели, накопленный технический долг, качество продукта конкурентов, дедлайны по контрактам. Половина этой информации обычно ещё и неизвестна или, хуже того, неверна.
Ещё одна проблема - выделение бюджета времени на работу с техдолгом. Посмотрим на упрощённый график зависимости прироста скорости проверки гипотез от приложенных усилий на примере задачи рефакторинга проекта или изменения архитектуры системы.
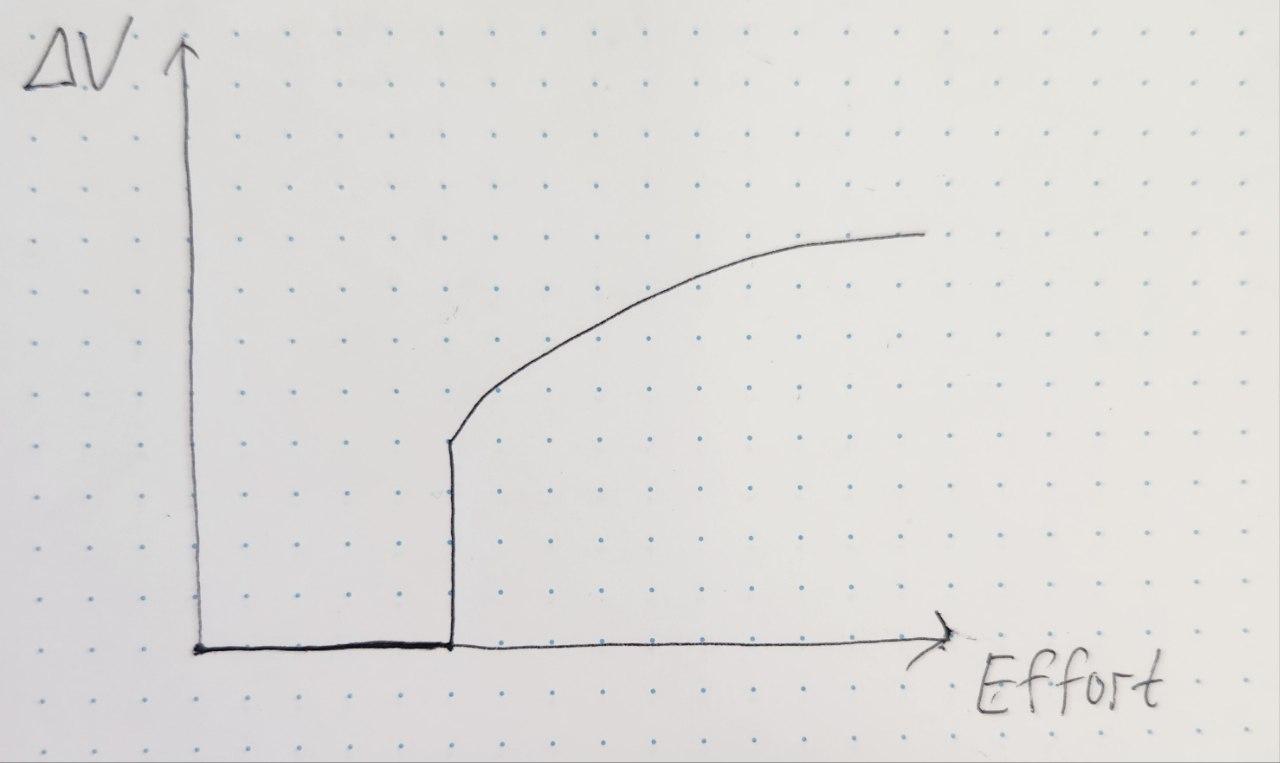
Это я нарисовал от руки
Как только мы начинаем рефакторить или перепиливать дизайн нашей ML-системы, сначала никакого положительного эффекта на скорость проверки гипотез не будет. Скорее, наоборот - какое-то количество людей будет занято на этой задаче, и общий throughput по гипотезам упадёт. Предсказать время, которое пройдёт до получения эффекта не всегда просто - на это влияет количество легаси, сложность системы, возможность атомизации задачи на отдельные кусочки, продуманность ML-дизайна. В некоторых случаях можно добавить ценности и за 15 минут, а иногда надо конкретно перепилить весь проект. Можно, конечно, ограничить время на задачу сверху - например, не более 4 недель. При этом есть риск не успеть и остаться вообще ни с чем (точнее, с полуготовой веткой refactoring/fucking_shit).
Тема сложная - недавно на одном из проектов как раз столкнулись с подобной дилеммой. Качество кода и данных деградировало, уменьшилась скорость проверки гипотез, и хочется уделить какое-то время улучшению технического качества проекта. При этом и по метрикам конкуренты поджимают, и нужно не сильно отстать. Чтоб было полегче составить такой техплан, я решил составить небольшую шпаргалку, которая содержит разные способы, которыми можно повысить общий ожидаемый результат проверки гипотез. Она точно не полная, но может помочь нащупать направления, которые могут дать буст по ожидаемому количеству гипотез, сработавших за единицу времени. Курсивом выделены примеры конкретных идей.

Примерный пайплайн гипотезы
Начнём именно со скорости - увеличения количества гипотез, которые мы можем тестировать в единицу времени.
Уменьшить время на понимание того, сработала ли гипотеза (latency, time-to-value)
Чем быстрее мы делаем вывод по гипотезе - тем быстрее мы можем выкатить её в продакшн или же перейти к следующей идее, если эта на сработала. Когда решение о ценности гипотезы занимает несколько месяцев - двигаться быстро вряд ли получится.
Улучшить процесс формулирования гипотез и работы над гипотезами
Иногда проблема кроется не в коде, а в процессах. Человек берётся за задачу, пишет код, ставит эксп, а в итоге выясняется, что он протестил совсем не то, что изначально обсуждали. Конкретное решение такой проблемы будет зависеть от ваших процессов, но вот пара идей:
- Внедрить шаблон карточки гипотезы с описанием идеи, возможных методов реализации, рисков, требуемых ресурсов
- Внедрить процесс дизайн-ревью перед непосредственным написанием кода
Уменьшить время, необходимое на написание корректного кода, нужного для тестирования гипотезы
Сам процесс написания кода в некоторых случаях тоже может быть долгим. А ещё мало просто написать код - желательно сделать это так, чтоб не нужно было десять раз перезапускать эксперимент на удалённой машине и принтовать в логи промежуточные значения.
- Провести рефакторинг кодовой базы, который позволит быстрее внедрять новые гипотезы в код проекта. Симптом, что пора заняться рефакторингом или даже переписыванием - одно маленькое изменение (например, дополнительный параметр в функции) требует изменений по всему проекту. При этом подойти к этому тоже надо с умом - провести ретроспективный анализ и понять, какие особенности кода и части проекта замедляют написание кода для новых гипотез, проанализировать кодовую базу смежных команд, атомизировать рефакторинг в отдельные законченные задачи.
- Улучшить кодовые и архитектурные навыки ML-инженеров. Возможно, код деградирует, потому что команде не хватает навыков. Тогда стоит уделить вниманию обучению. Тема большая, но чисто из книг могу порекомендовать Clean Machine Learning Code и Architecture Patterns with Python.
- Ускорить проверку того, корректно ли работает код эксперимента. ML-инженер должен иметь возможность максимально быстро понимать, будет ли его код работать на той машине, где он планирует его завести. Например, можно написать лёгкий локальный тест трейн-лупа или добавить проверку на наличие всех нужных данных на сервере перед стартом эксперимента.
Уменьшить количество этапов, которые нужны для тестирования гипотезы
В некоторых случаях чтобы понять, сработала ли гипотеза, недостаточно просто запустить обучение сетки и сравнить в конце метрики. Иногда нужно подобрать пороги срабатывания, провести human evaluation, обучить следующие сети в каскаде моделей. Всё это естественным образом увеличивает тот самый time-to-value, время до результата проверки гипотезы. Имеет смысл рассмотреть возможности сокращения количества этапов:
- Придумать метрику, которая будет коррелировать с финальной, но которую можно считать во время основного эксперимента.
- Передизайнить архитектуру системы, чтобы модели были независимы друг от друга.
- Сравнивать модели на дефолтных порогах срабатывания - типа 0.5 или аргмакс для классификации.
Уменьшить время, затрачиваемое на один эксперимент
Чем быстрее мы обучаем модели или подбираем постпроцессинг, тем быстрее мы можем сравнивать гипотезы. Как сократить время от старта до конца всего эксперимента?
- Уменьшить количество скрытых багов, которые появляются в ходе работы над гипотезой. Очень обидно зарядить на ночь эксп, чтоб утром узнать, что модель училась на кривой разметке. Рецепты тут похожи на пункт про написание корректного кода - провести рефакторинг, который уменьшит количество багов, увеличить покрытие проекта локальными быстрыми тестами, добавить визуализацию данных, которые поступают в сетку.
- Ускорить обучение нейронки. Добавить кэширование препроцесснутых данных, использовать техники ускорения обучения, ускорить сходимость модели до финальных метрик, обучать сетки не с нуля при добавлении данных в датасет. Отдельная и большая тема.
- Сравнивать гипотезы для нефинальных версий моделей. В некоторых случаях можно обучать модели на меньшем сабсете данных или меньшее количество эпох, и этого достаточно для адекватного сравнения гипотез.
Увеличить количество гипотез, которые мы можем тестировать параллельно (throughput)
Ещё один способ увеличить общее количество гипотез - не ускорить проверку каждой конкретной гипотезы, а устранить пропускные боттлнеки и запускать больше экспериментов параллельно. Боттлнеки могут быть связаны с людьми, компьютерами, да даже с влажностью воздуха в офисе.
- Уменьшить количество времени инженеров, которое нужно для тестирования гипотезы. Автоматизировать или упростить пайплайн тестирования гипотезы, сократить количество других задач, делегировать часть задач с ML-инженеров на аналитиков.
- Нанять людей.
- Уменьшить объём вычислительных ресурсов, нужных для тестирования гипотезы. Использовать различные техники компрессии моделей, упростить архитектуру, уменьшить размер входного изображения.
- Увеличить количество компьютерных ресурсов.
Увеличить качество гипотез и процент успешных гипотез
Рост количества тестируемых гипотез - не единственный способ увеличения ожидаемого выхлопа. Если из 10 гипотез срабатывают 10, то о скорости особо можно и не париться. Конечно, это, скорее, из области научной фантастики, но наращивать процент успешных гипотез можно и нужно.
- Улучшить качество приоритизации гипотез. Организовать процессы обучения и шаринга данных в команде и между командами, внедрить экспертный способ приоритизации, нанять человека с широким кругозором и большим опытом, проанализировать итоги проверки прошлых гипотез в своей и других командах.
- Улучшить качество данных. Жизнь показывает, что гипотеза вполне может докинуть на хороших данных и не докинуть на отстойных. Автоматическая и ручная очистка датасета от мусора, изменение правил разметки, переразметка старых данных, внедрение дата-тестов - всё это часто повышает процент успешных гипотез.
- Внедрить инструменты для работы с данными. Возможность удобно и быстро визуализировать данные, предсказания модели на продакшне, промежуточные значения позволяет глубже понимать работу системы и генерировать более качественные гипотезы.
- Повысить доменную экспертизу. Помогает анализировать данные и генерировать хорошие и простые гипотезы. Особенно актуально для таких областей как медицина. Можно нанять эксперта или попробовать прокачаться самим, если область не очень сложная.
Ещё бывают мега-гипотезы - обычно они требуют больших временных и интеллектуальных затрат, а значит браться за них рискованно. Не у всех есть возможность постоянно вести затратный рисёч, но бывают времена, когда нужно не улучшать по мелочи, а принимать смелые решения и вкладываться в долгие и мощные гипотезы.
По итогу
Как же балансировать между краткосрочной выгодой и долгосрочными инвестициями, особенно учитывая количество развилок? Вопрос вечный, простого ответа нет, но есть варианты на подумать:
- Постоянно выделять фиксированный процент времени на подобные задачи
- Уходить на техдолговые каникулы после каждого успешного релиза, если впереди нет важных дедлайнов и краткосрочных бизнес-целей
- Начинать работать по этому треку, когда члены команды начинают ругаться матом при проверке новых гипотез
- С осторожностью использовать среднее время до релиза или средний time-to-value гипотез как прокси-метрику для балансировки между треками проверки гипотез и технического улучшения
В любом случае невредным будет иметь отдельный список с идеями технических улучшений, чтобы при возможности оперативно брать оттуда задачи.