Парсинг документов и OCR в 2025 году
Парсинг документов и OCR в 2025 году
Внезапно тема понимания сложных документов оказалась на хайпе - за короткий срок вышло большое количество крутых VLM, заточенных под задачи OCR и понимания структуры документа, а совсем на днях ещё и DeepSeek-OCR подогрел градус дискуссии. Меня самого эта история тоже интересует - регулярно появляются разные внутренние и внешние задачи, связанные с обработкой сложных документов - сканированных PDF, PDF с таблицами и рисунками, картинок с текстом, Excel-таблиц и так далее. Я решил разобраться в теме и практически (об этом в другом посте), и теоретически.

Кратко о задаче
Задача в общем и целом звучит так - превратить любой входной файл в текстовый или иной формат пригодный для дальнейшей автоматизированной обработки. В 2025 году эта обработка чаще всего заключается в анализе документов с помощью LLM - как независимо, так и в рамках RAG-пайплайнов.
Лет пять назад для распознавания текста на фото паспортов нам пришлось строить довольно сложный пайплайн:
- Классификатор - паспорт или другой док
- Детектор 6 точек и выравнивание изображения
- Детектор полей
- Image2Sequence распознаватель текста в полях
Какие сейчас есть подходы к задаче парсинга документов?
- Если документ исходно не является картинкой, то можно просто детерминированно распарсить его в некую текстовую форму. Можно использовать какую-нибудь внешнюю библиотеку типа Markitdown или сервис типа Unstructured.
- Если документ представляет из себя изображение, то можно составить сложный пайплайн из разных моделей - например, распознать текст OCR-моделью, распознать структуру документа Layout-моделью, и результаты как-то скомпоновать в итоговый текст. Аналогично если текстовый документ содержит внутри себя изображения, то их тоже можно обработать таким же пайплайном или сгенерировать их общее описание с помощью VLM.
- Для всех типов файлов можно взять VLM и end-to-end сгенерировать по изображению структурированный аутпут - JSON, Markdown или HTML. Это относительно свежий подход.
- Для RAG-систем можно вообще выкинуть промежуточный этап с конверсией документа в текст и сохранять его как набор визуальных эмбеддингов как в подходе ColPali. На инференсе мы матчим визуальные эмбеддинги с запросом пользователя, достаём нужные страницы из документов и засовываем их в VLM как дополнительный контекст.
Хорошее овервью, включая описание популярных VLM под эту задачу можно прочитать на Huggingface.
Что я читал в сентябре-октябре
Здесь расскажу кратко про статьи, которые я читал за последние несколько недель. В основном все этой осенью и вышли. Безусловно, есть и другие заслуживающие внимания статьи и технические отчёты, которые появились весной-летом.
DeepSeek-OCR: Contexts Optical Compression
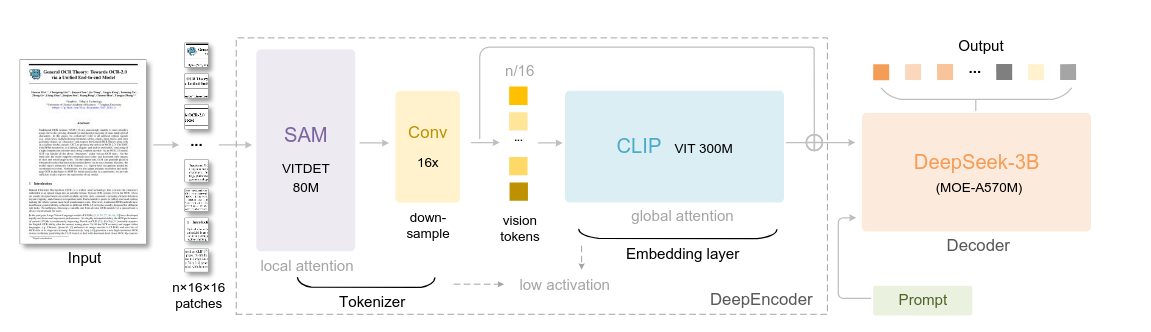
Зачем читал: хайп хайповый (“НЕУЖЕЛИ МОЖНО ОТКАЗАТЬСЯ ОТ ТЕКСТОВЫХ ТОКЕНОВ И СЖАТЬ ПРОМПТ В 20 РАЗ??”) + интересно, чем архитектура отличается от других OCR-решений.
Суть кратко: вообще статья написана для иллюстрации концепта - можно передать текстовую информацию через значительно меньшее количество визуальных токенов изображения этого же текста. Для иллюстрации используется задача OCR - если мы можем её решать с очень высокой точностью, значит и информация в процессе визуального энкодинга никакая не теряется. Например, при уменьшении количества токенов в 10 раз точность OCR на бенчмарке - 97%.
- Энкодер (380 миллионов параметров) состоит из SAM+downsample-конволюции+CLIP. SAM берёт на вход патчи 16x16, извлекает локальные признаки, генерирует много токенов (скажем, для изображения 1024x1024 - 4096 токенов). Затем, с помощью конволюционного компрессора сжимаем 4096 токенов в 256 токенов. Эти токены уже поступают в блок CLIP, который отвечает за global attention.
- Декодер (3 миллиарда параметров) - Mixture-of-Experts модель, во время инференса активируется 570 миллионов параметров.
У модели есть “Deep parsing” режим - модель находит картинки внутри документов и отправляет их на описание отдельными запросами.
Конкретно по качеству OCR сам ещё не успел затестить, в твиттере отзывы от “чуть хуже SOTA” до “очень хорошо”. Вообще, забегая вперёд, результаты по качеству на русском языке опубликую отдельно. А в твиттере по большей части обсуждают не качество OCR, а пора ли выбрасывать на помойку токенайзеры и обрабатывать текст как картинки. Думаю, что пока всё-таки рано.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
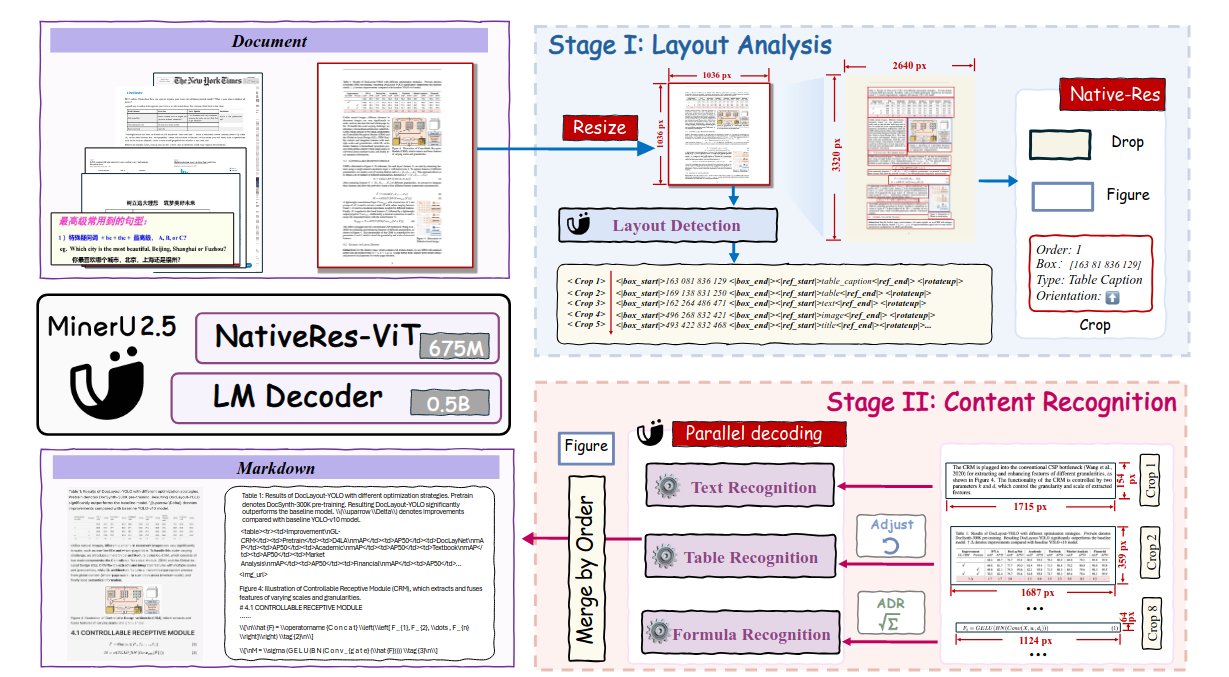
Зачем читал: техрепорт по одной из лидерских маленьких моделей (1.2B) для задач парсинга сложных и сканированных документов.
Суть кратко: разделяют задачу на два этапа - сначала детекция структуры документа на уменьшенной версии картинки (на выходе список из объектов с тегом - таблица, заголовок таблицы, картинка, текст, координаты, угол поворота, ориентация на странице), затем экстракция кропов по найденной структуре и их параллельная обработка.
В самой модели используются всякие фишечки типа M-RoPE, pixel-unshuffle (“сшиваем” вместе группы токенов 2x2, объединяя их в 1 токен, прежде чем отправить в LLM на анализ). Вообще отчёт очень интересный, подробно описывается генерация данных, система тегов, советую почитать.
PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
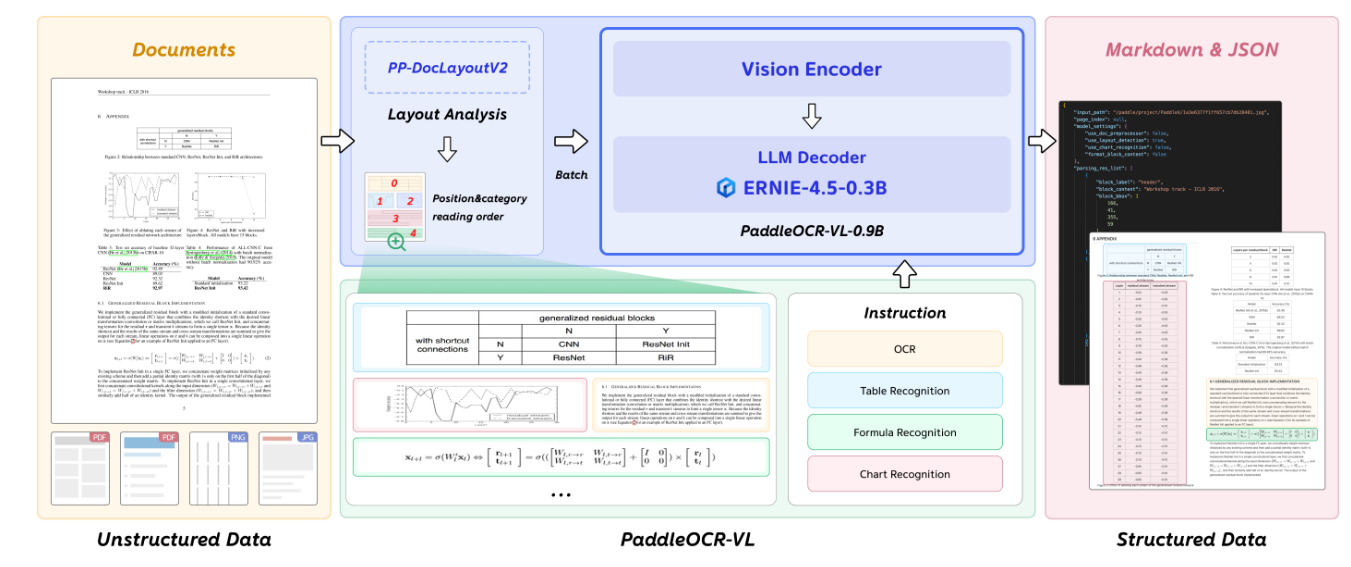
Зачем читал: ультра-маленькая модель, которая по качеству якобы бьёт даже признанных лидеров типа dots.ocr.
Суть кратко: сразу выясняется небольшая хитрость, кроме самой 0.9B-модели есть ещё и отдельная модель PP-DocLayout V2 под выявление структуры документа. Она состоит из RT-DETR модели, которая детектит и классифицирует разные элементы документа (параграф, изображение, текст и так далее), а также специальной сетки, которая предсказывает логический порядок этих элементов на странице.
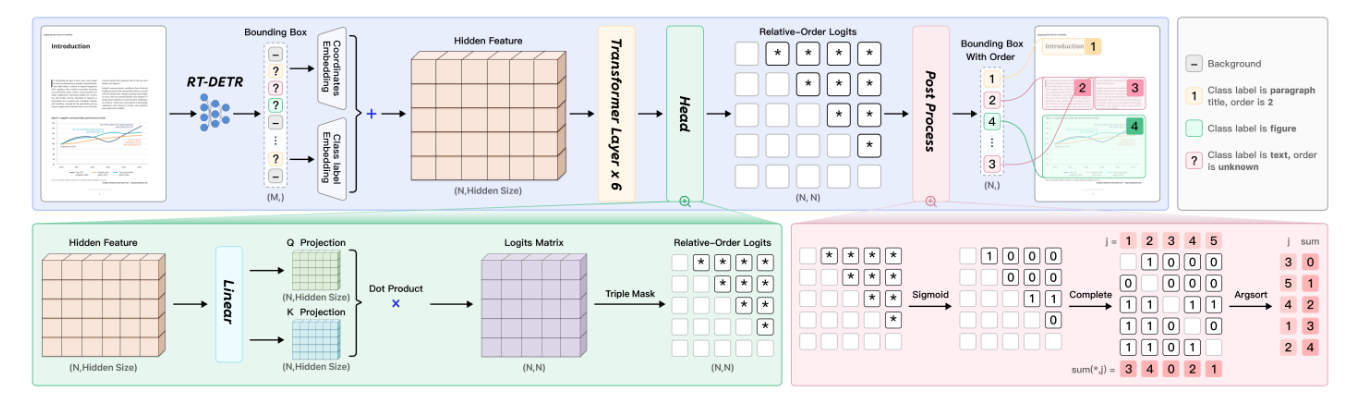
Найденные элементы затем вырезаются из документа и подаются на вход в VLM, которая уже превращает их в текст. Для работы с разными размерами изображений используется NaViT-энкодер (патчи из нескольких изображений могут паковаться при обучении в одну последовательность с self-attention масками; 2D позиционные эмбеддинги по относительным координатам).
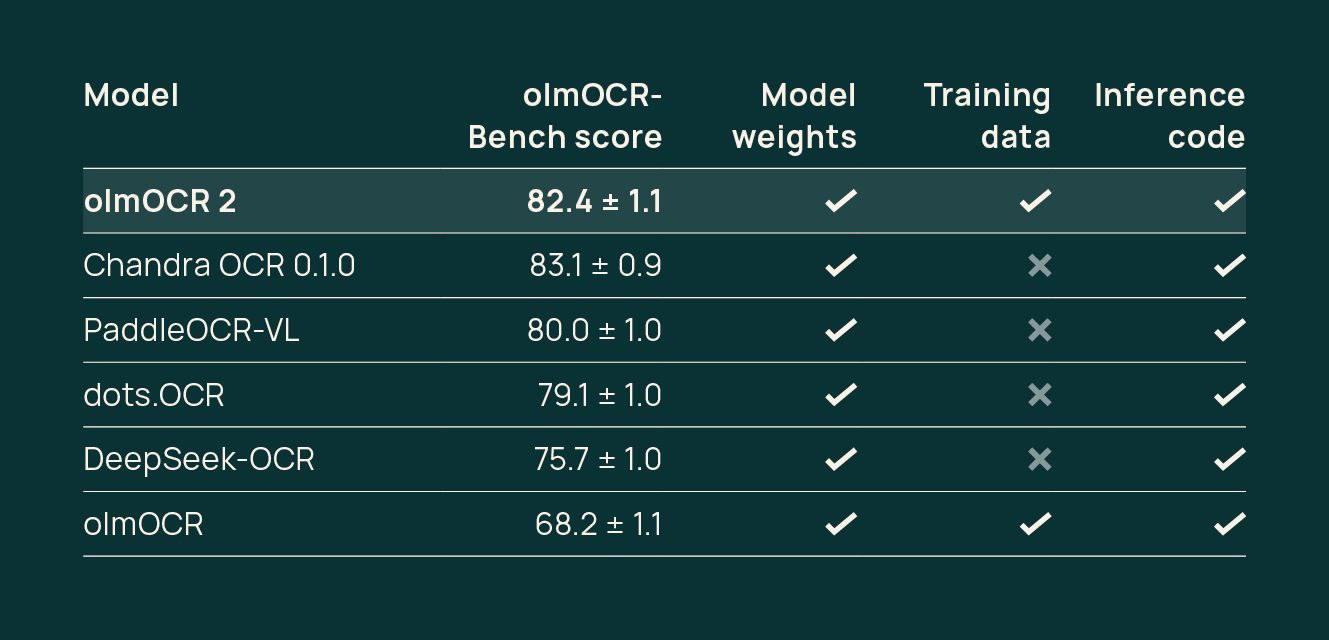
Даже по бенчам от olmOCR получается сильная модель (Chandra - это новая опен-сорс модель от автора Surya).
Qwen3-VL-8B
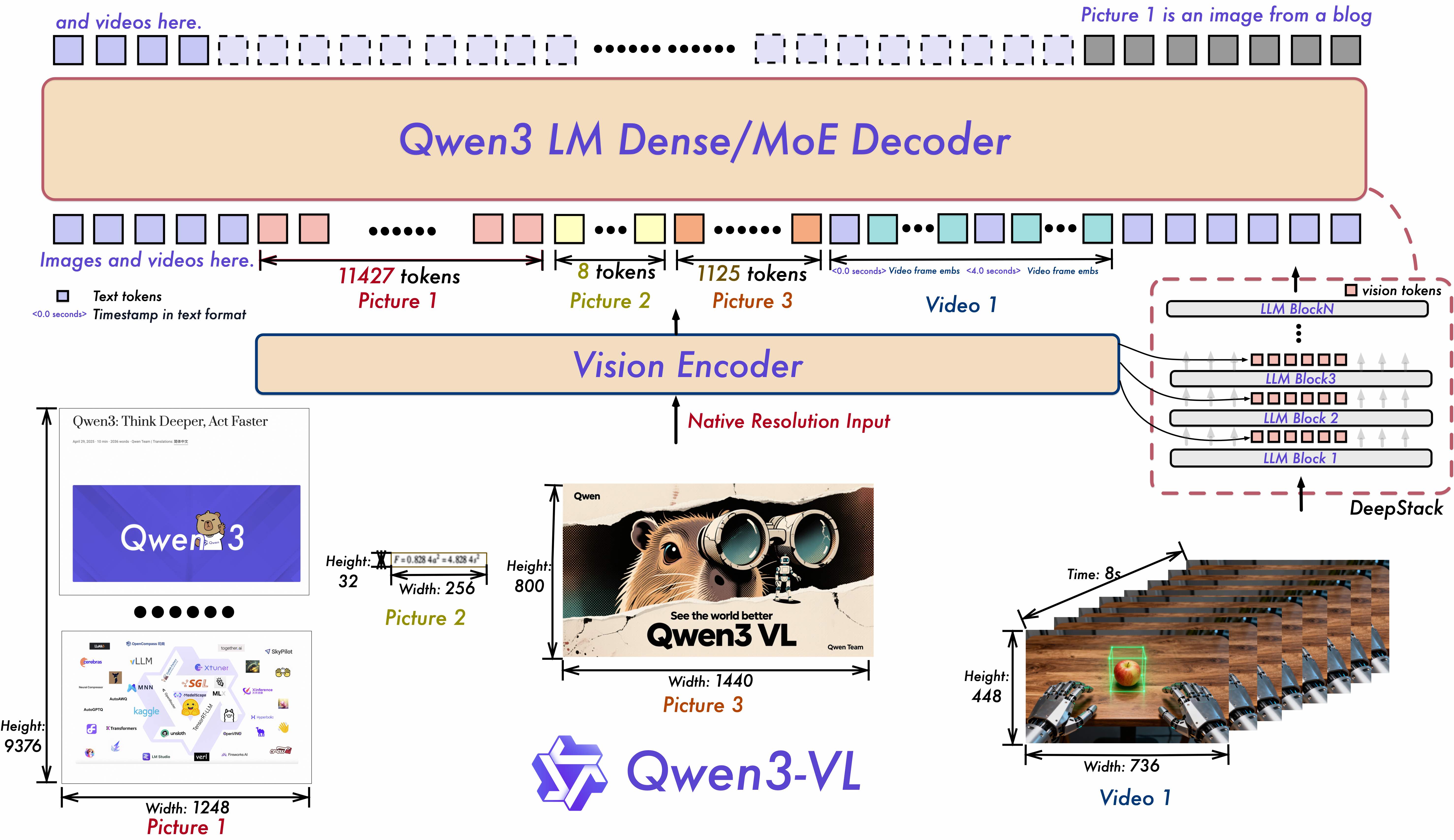
Зачем читал: читать тут особо нечего (техрепорта по VL-версии пока нет), но захотелось включить в силу того, что это совсем другой подход к OCR - просто запихиваем всё в одну VLM. Работает это обычно хуже, чем специализированные модели, но свои плюсы тоже есть. Например, одной моделью можно и делать OCR, и семантически описывать картинки внутри документов, и отвечать на текстовые запросы пользователей по документам.
Prompt-Optimized OCR for Production: GEPA Shows OCR is Steerable for Business Document Pipelines
Зачем читал: интересны реальные эффекты от хайпового метода GEPA.
Суть кратко: недавно появился эволюционный алгоритм GEPA, который итеративно улучшает промпт модели через анализ логов работы LLM (могут включать ризонинг, вызов инструментов, аутпут, метрики, логи evaluation-функции). Сама идея подбора автоматического тюнинга промпта не нова - например, есть популярный фреймворк DSPy. Но GEPA наделал шуму, показав, что может побить SOTA RL-методы дообучения типа GRPO за кратно меньшее количество итераций.
В этой статье проверили, можно ли за счёт промпта улучшить качество парсинга документов. Интуитивно кажется, что вряд ли - боттлнеком почти всегда будет качество визуальной модели и качество самих документов. Оказывается, что часть ошибок может быть связана не с визуальной составляющей. Для проверки они разбили пайплайн на два этапа - сначала Image2Markdown (извлекаем текст и примерную структуру), потом Markdown2JSON (извлекаем содержание по строго заданной схеме). Сама система использовала Gemini 2.0/2.5 Flash, а промпт улучшали с помощью GPT-5 High.
Результат - прирост 3-4 процентных пункта именно на этапе перевода извлечённого текста в структурированную схему. На этапе OCR промптить особо нет смысла. Наверное, если сделать одноэтапный пайплайн (Image2JSON), то можно улучшить качество таким образом.
ColPali vs OCR
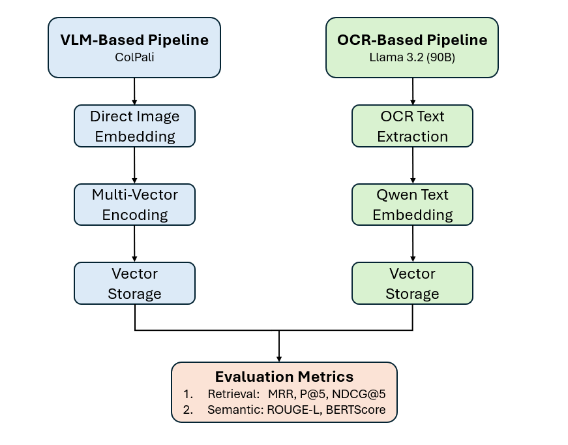
Зачем читал: очень интересны метрики ColPali на внешних бенчмарках.
Суть кратко: недавно тестил метод ColPali/ColQwen, и первые результаты были очень интересные. Но полноценный тест только собираюсь провести, так что интересно посмотреть, насколько результаты из статьи генерализируются.
Сравниваются ColQwen 2 7B и OCR через визуальную модель (Llama 3.2 90B и Nougat OCR) + RAG через Qwen-Embedding. Главный вывод - без файнтюна под конкретный домен ColQwen хуже находит нужные документы, чем OCR-подход. А вот на своём датасете метрики ColQwen лучше. Особенность этого датасета - отличное качество документов, но более сложные для OCR-подхода пары “запрос - документ”.
Что дальше?
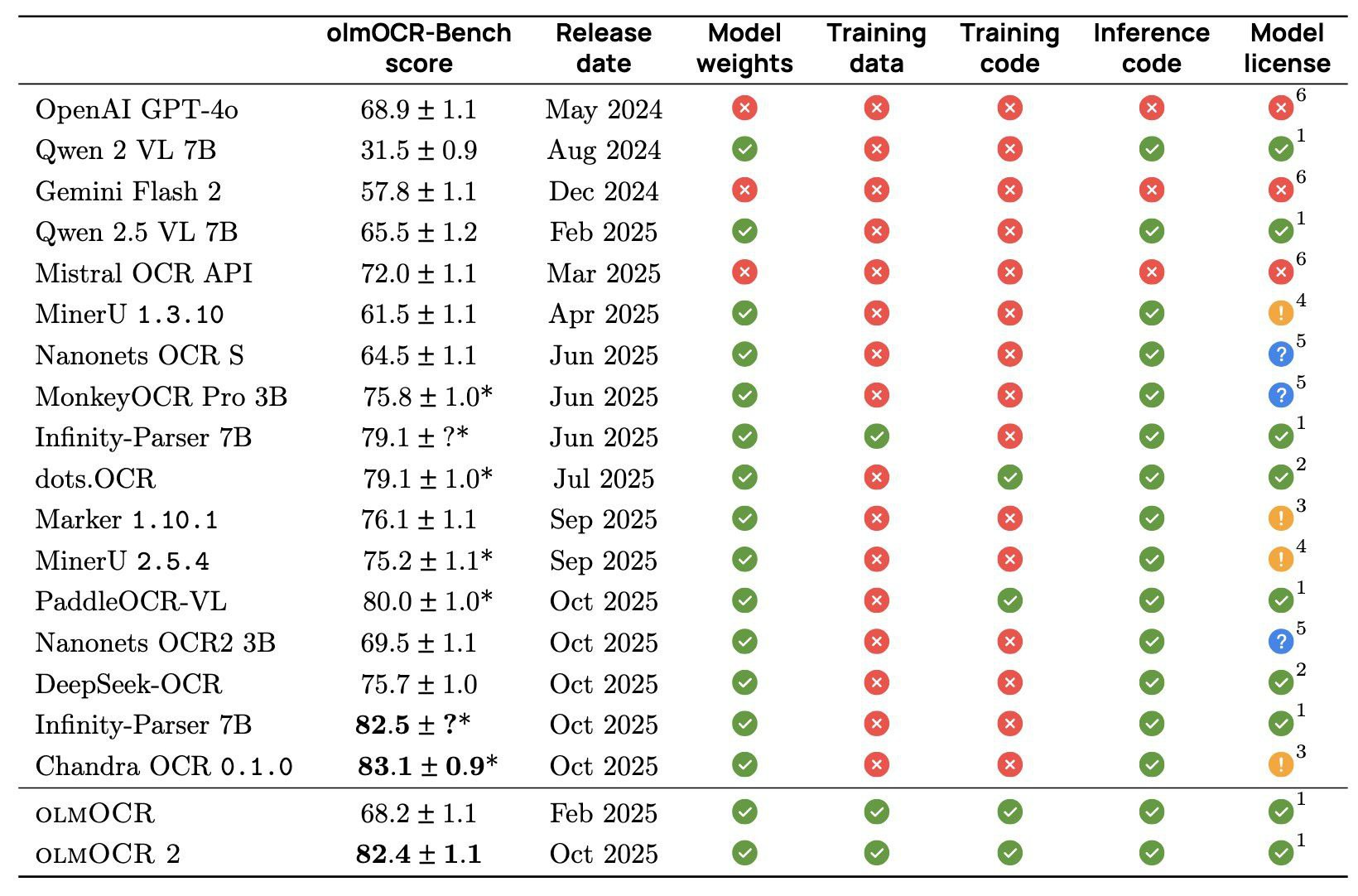
Как мы видим, и подходов, и разных специализированных OCR-моделей и фреймворков (olmOCR 2, Chandra, PaddleOCR, docling, MonkeyOCR, dots.ocr) более чем достаточно. Остаётся ряд важных вопросов:
- Что по русскому языку?
- Что лучше работает на практике на разных типах документов - картинках, сканированных PDF, рукописных текстах, обычных PDF со сложной структурой, документах с печатями и пометками?
- Как это всё вписывается в RAG-пайплайны для QA по документам?
- Всё-таки ColQwen или OCR? Можно ли парсить сложные несканированны документы без моделей?
- Можно ли подобрать пайплайн, который будет качественно работать из коробки на всех нужных документах без дообучения? Нужно ли использовать разные модели/библиотеки для разных видов документов?
На эти вопросы я сейчас пытаюсь для себя ответить на нашем внутреннем бенчмарке. Результатами поделюсь в одном из следующих постов.