Как я сделал сайт для Варим МЛ с RAG-чатом
Я уже довольно долгое время хотел переехать с Телеграфа на другую платформу:
- Ограничение на длину постов
- Очень неудобно грузить картинки, приходится пользоваться внешними хостингами + это ненадёжно
- Хочется видеть все свои посты в одном месте, искать по ним, сортировать. Я же пишу не только для вас, но и для себя - иногда нужно что-то найти
Один из ML-блогов, которые мне нравятся, сделан на связке Jekyll + Github Pages. Что особенно приятно, это бесплатно, но блог должен лежать в публичном репозитории, это для меня не проблема, весь контент и так доступен. По ходу работы количество хотелок начало разрастаться - например, мне захотелось добавить RAG-чат вместо обычного поиска. В первую очередь, чтобы протестировать, как добавлять такие штуки на сайты, но и в качестве забавной игрушки сгодится.
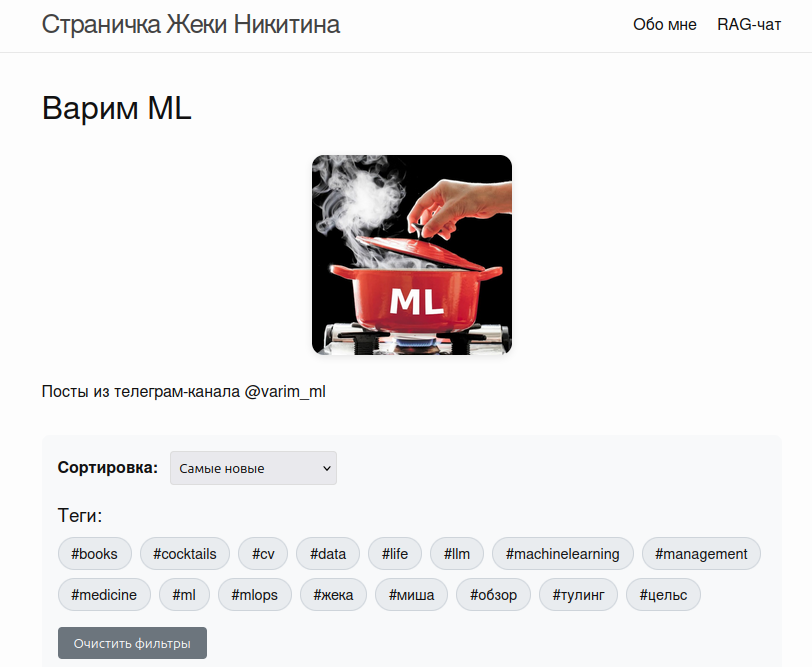
Какие требования в итоге у меня были к сайту:
- Минималистичный дизайн
- Сортировка постов по просмотрам и по дате
- Фильтрация по тегам
- Страничка “Обо мне”
- RAG-чат
- Хорошее качество retrieval, но чтоб это было просто (лень поднимать где-то отдельный бэкенд) и желательно бесплатно
- Безопасный доступ к LLM - чтоб никто не мог украсть мои ключики или абьюзить чат, задавая нерелевантные вопросы
- Чтоб можно было задавать дополнительные вопросы после ответа LLM
Итак, что же у меня получилось, и какие технологии я применил?
Фронтенд и деплой
В основе блога лежит Jekyll. Это генератор статических сайтов, который берёт HTML-шаблоны и контент в Markdown (в моём случае посты из Варим МЛ) и генерирует набор статических файлов (.html, .css, .js), которые затем публикуются на Github Pages. Посты лежат в _posts, шаблоны в _layouts и _includes (здесь лежит переиспользуемый футер). В конфиге можно выбрать тему и нужные плагины. Вообще весь код сайта доступен тут, можно поизучать или скопировать себе.
Любой пуш в репозиторий тригерит пересборку сайта через jekyll build. Буквально через минутку обновления уже доступны на сайте. Для тестов можно сёрвить локально через bundle exec jekyll serve.
Добавление постов
Новый пост я сейчас пишу в маркдаун-формате (например, в IDE) с шапкой мета-данных в формате YAML front matter, коммичу, и вот он на сайте, можно публиковать в канал. Если точнее, то есть специальный питоновский скрипт, который из маркдауна с постом генерит нужные мета-данные, рассовывает картинки в нужные папки, генерит и эмбеддит чанки и делает всю остальную рутинную работу.
А что делать со старыми постами? Естественно, нужно автоматизировать процесс сбора. Подключаемся к Telegram через Telethon, сканируем канал Варим МЛ, ищем все ссылки на Telegraph-посты и на гугл-доки (была парочка постов через них). Далее
- Скачиваем контент поста
- Через Telegram API забираем количество просмотров
- Генерируем краткое описание поста через OpenRouter
- Создаём маркдаун-файл
На выходе получаем папку с маркдаунами и отдельную папку assets/images с картинками из постов.
RAG-чат
Самый сложный технически компонент сайта - это RAG-чат. Давайте по кусочкам разберём, из чего он состоит, а главное почему.
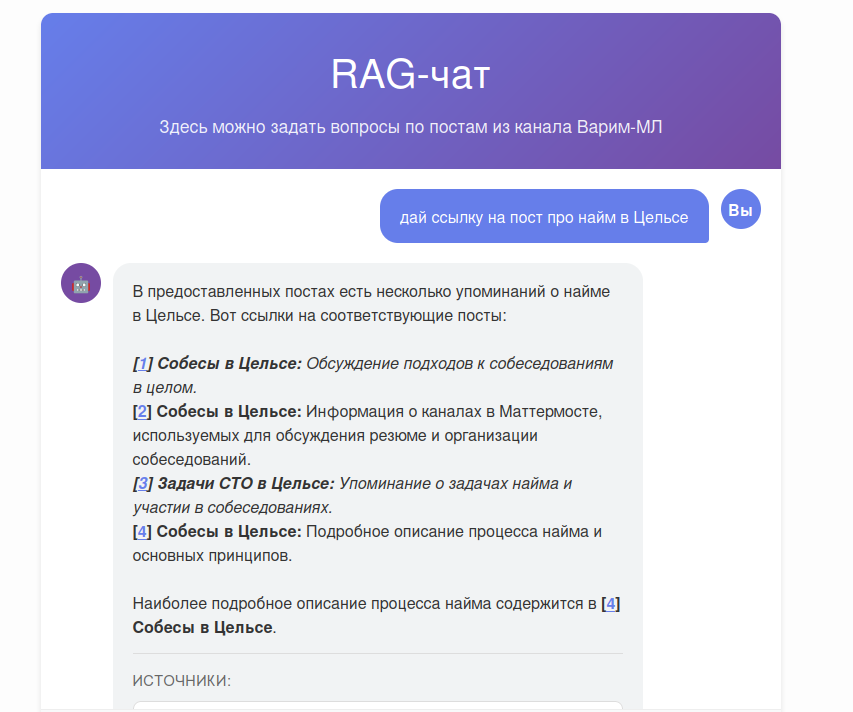
Retrieval
Для начала нам нужно почистить посты и нарезать их на чанки. Пишем питон-скрипт, который загружает маркдаун, удаляет лишние символы и информацию, а затем создаёт чанки из саммери и из самого текста поста. Чанкование я тут решил сделать простое, 512 токенов с перекрытием в 50 токенов, разбиение самое простое, просто по пробелам. В реальных проектах часто лучше использовать что-то похитрее, но это пока больше демка, поэтому пока оставил так.
Для поиска решил использовать гибридную стратегию - эмбеддинги + BM25. Вопрос - где гонять эмбеддинг-модель? Деплоить отдельный бэкенд и векторную БД? Искать готовую API и платить деньги? Неохота, давайте переложим головную боль на клиента (а заодно поиграемся с модельками в браузере).
ML в браузере
Когда-то давно я выступал на Кодфесте, и во фронтенд-секции был прикольный доклад Полины Гуртовой про ML в браузере на примере задачи классификации картинок. Ничего нам не мешает запускать в браузере и эмбеддинг-модель. Берём ONNX Runtime Web, выбираем модель и поехали. Но есть нюансы.
Поскольку модель будет гоняться прямо в браузере, она должна быть достаточно маленькой, но совсем ронять качество retrieval тоже не хочется. Идём на лидерборд MTEB, выбираем русский язык, видим, что на первых двух местах модели с миллиардами параметров. На третьем - FRIDA 823 с миллионами, уже лучше, но всё ещё очень много. Немножечко гуглим и видим, что в опенсорсе есть rubert-mini-frida, в которой 7 слоёв вместо 24, а размер самих эмбеддингов уменьшен в 5 раз. Весит она 123 мегабайта, вполне себе неплохо.
Все чанки, естественно, быстро и эффективно эмбеддим заранее на своём компе, а в браузере останется лишь заэмбеддить запрос пользователя и найти наиболее похожие вектора из сохранённых заранее данных. Задеплоил всю эту магию, работает, но есть нюанс - при каждом обновлении страницы пользователю надо перекачивать 123 мегабайта, а это в лучшем случае несколько секунд. Чатимся с Claude, гуглим, выход есть - IndexedDB.
Это встроенное в браузер key-value хранилище для хранения данных на стороне клиента. Первый раз нужно будет скачать, потом перекачка понадобится, только если браузер или пользователь очистят данные сайта.
В итоге весь процесс от начала до конца происходит именно в браузере - токенизация, прогон через модель, mean pooling по токенам, L2-нормализация эмбеддинга. Аналогично BM-25 также написан на JS, и выполняется в браузере. Почему-то меня это очень порадовало, раньше не приходилось иметь дел с модельками в браузере.
LLM
Top-k чанков из постов мы достаём не просто так, а чтобы передать их на вход LLM. Как сделать это безопасно, чтоб никто не украл мой OpenRouter-ключик и не заспамил нейронку нерелевантными запросами? На помощь нам приходит Cloudflare Worker. По сути это такой простой способ выполнять удалённо какие-то серверлесс-функции. Я его использую по ряду причин:
- Есть бесплатный тир, а хочется пока оставить сайт полностью бесплатным
- Чтобы скрыть API-запрос и ключ в OpenRouter, пушим ключ в CloudFlare, и физически только у воркера есть к нему доступ
- Удобный и простой rate limiting IP через key-value хранилище
- Можно настроить CORS, который позволяет делать запросы только с определённых доменов, чтобы не дёргать воркер откуда попало
Сами LLM я беру сейчас бесплатные, но перебираю несколько на случай отключений и ограничений. По умолчанию стоит Gemma 3 27B.
Чат
Ну всё, осталось только собрать все эти компоненты вместе и добавить важные кусочки, а именно:
- Валидация запроса через LLM - чтоб пресекать вопросы пользователей о нерелевантных темах. Конечно, опытные джейлбрейкеры сломают, но базовая защита - уже неплохо.
- Query rephrasing - пользователь может спросить “в какой компании работает автор?”, получить ответ, а потом задать дополнительный вопрос “что это за компания?”. Без перефразирования RAG не найдёт документы о Цельсе, так как в запросе не содержится названия компании.
- История чата - подаём последние 6 сообщений на вход LLM, а не только текущий запрос.
- Фильтрация источников - если какие-то из чанков не использовались LLM, то можно их отфильтровать, чтоб уменьшить количество мусора в разделе источники. Не забываем перенумеровать источники в ответе, чтоб ссылки были корректными.
Ура!
Вот и всё! Получается, базовый блог, в который можно писать Markdown-посты. Для баловства и для образования добавил RAG-чат, для написания всего этого, естественно, использовал Claude Code и немного Cursor. Со временем буду как-нибудь развивать сайт (когда захочется ещё побаловаться), но вся нужная мне сейчас функциональность на нём уже есть.