Субъективный гайд по использованию Claude Code
Субъективный гайд по использованию Claude Code
За прошлый год я потестил достаточно большое количество ИИ-инструментов для разработки (Cursor, Claude Code, Codex, Cline, Aider, RooCode, Kilo, Augment) и даже написал обзорный пост. Какие-то отбросил почти сразу, какие-то прям поюзал и даже посравнивал на одних и тех же задачах. В итоге сейчас я отменил все подписки кроме Claude Code Max и в качестве IDE использую Zed, в котором есть нативная интеграция через Agent Client Protocol. Почему Claude Code?
- Главная причина - на моих субъективных ненаучных сравнениях качество намного лучше, чем у конкурентов
- Богатая эко-система плагинов и в целом это популярный развивающийся инструмент
- Адекватная цена - за 100/200 долларов я получаю практически безлимитные запросы и не парюсь о тратах
Спорный момент - ухудшают ли использование ИИ-агентов понимание кода и контроль над кодовой базой? Наверное, да, особенно если работать в YOLO-режиме и не ревьюить решения агента и код. В любом случае мне сейчас не очень нужно глубокое понимание самого кода, достаточно архитектурного понимания, как всё работает, так как почти все мои задачи делятся на три типа:
- Одноразовые задачи - проанализировать файлы, сделать рисёч, побрейнстормить
- Создание внутреннего инструментария для автоматизации рутинных задач (как моих, так и всей компании)
- ML-эксперименты с новыми архитектурами - 90% не сработает, 10% можно вникнуть в детали кода пост-фактум
В этом году мы решили централизованно внедрять ИИ-инструменты для разработки в техническом отделе, до этого только точечно компенсировали стоимость подписки энтузиастам. Для начала я решил взять пять мест в командном плане Claude Code - как раз потому что это мой любимый инструмент, по которому я могу дать какие-то субъективные советы. Написал для коллег гайд и решил поделиться с вами его слегка переработанной версией.
Если вы никогда не использовали CC или подобные инструменты, то рекомендую забить на гайды в стиле “запускаем 5-10 агентов параллельно” и поработать сначала в максимально простом режиме - без плагинов, с одной открытой вкладкой, можно через плагин для VS Code или в Zed. Так вы лучше поймёте сильные и слабые стороны, как лучше формулировать свои запросы и не пропустите момент, когда его нужно останавливать.
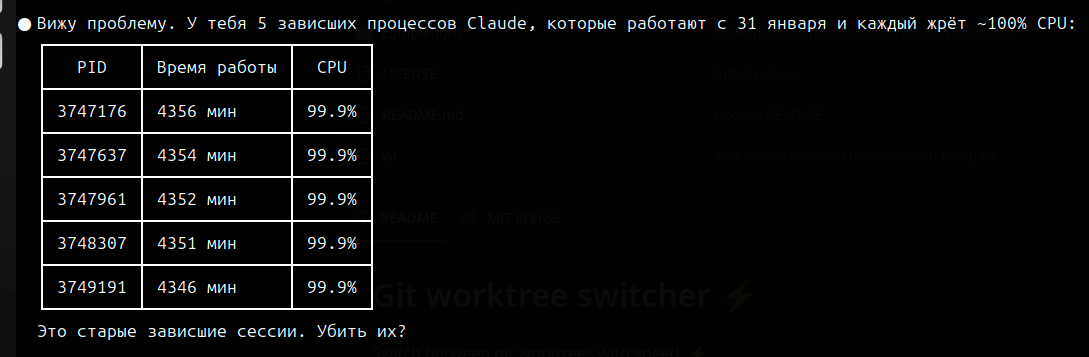
Best practices
Если вы в России
Я использую такую схему - VPN настроен через Shadowsocks, сверху поднят Privoxy, так как CC не заработал у меня с SOCKS5-прокси.
Схема простая, ставим Privoxy (sudo apt-get install privoxy), в конфиг /etc/privoxy/config добавляем строчку
forward-socks5t / 127.0.0.1:1080 .
И перезапускаем: sudo systemctl restart privoxy.
Для удобства у меня в ~/.bash_aliases есть такие команды:
alias setproxy='export http_proxy=http://127.0.0.1:8118; export https_proxy=http://127.0.0.1:8118; export no_proxy=localhost,127.0.0.1; export HTTP_PROXY=$http_proxy; export HTTPS_PROXY=$https_proxy; export NO_PROXY=$no_proxy'
alias unsetproxy='unset HTTP_PROXY; unset HTTPS_PROXY; unset NO_PROXY; unset http_proxy; unset https_proxy; unset no_proxy'
В no_proxy можно добавить любые адреса, к которым CC должен обращаться не через VPN.
Теперь в терминале достаточно набрать setproxy и потом уже claude.
CLAUDE.md и правила
Не забывайте добавлять важные штуки в CLAUDE.md в корне проекта (ещё есть общий на все проекты - ~/.claude/CLAUDE.md). Например:
- Используй только uv для установки питон-пакетов
- Используй энв ~/.virtualenvs/breastcancer для запуска питон-команд
- Все новые ветки называй либо features/, либо experiments/
Без этого CC будет постоянно совершать одни и те же бесячие ошибки. Время от времени можно его компрессить с помощью самого CC.
Ещё можно просить CC самого обновлять этот файл прям по ходу работы. Например, когда вы исправили его ошибку, добавьте - “Обнови CLAUDE.md, чтобы больше не повторять эту же ошибку”.
Во многих командах этот файл коммитят прям в репу и работают над ним коллаборативно.
Если не хочется пихать всё в один файл, то можно использовать правила, их нужно класть в отдельные маркдауны в папку .claude/rules (на уровне проекта) или ~/.claude/rules (на уровне пользователя).
Подробнее про память тут.
Работаем с сессиями
Сессия - основной юнит работы в CC. Каждый раз, когда мы хотим решить какую-то новую задачку, мы создаём новую сессию, в контекст которой загружаются:
- Системный промпт и инструменты
- CLAUDE.md и правила (“memory files”)
- Описания скиллов
- Описания включенных инструментов MCP
- Описание кастомных субагентов
- Если сессия не новая, то предыдущие сообщения
Важные команды для работы с сессиями:
- /rewind - откатиться на какой-то шаг разговора
- /resume - продолжить одну из прошлых сессий
- /fork - форкнуть сессию (создаётся копия текущей с новым айдишником)
- /rename - дать удобное название сессии вместо автоматического
- /compact - можно вручную триггернуть сжатие контекста и инструкцией
Авто-сжатие, кстати, теряет кучу важных деталей (например, какой скрипт с какими параметрами мы сейчас используем для дебаггинга), так что рекомендую такие штуки добавлять в md-файл со спецификацией задачи и сразу его прокидывать в контекст после сжатия.
Ну и вообще наберите / и поизучайте, какие команды есть.
Для продолжения сессий можно также запускать такие команды в терминале:
- claude --continue # последняя
- claude --resume # список для выбора
- claude --continue --fork-session # последняя сессия клонируется
Важно - по умолчанию сессии хранятся 30 дней после последнего изменения. Это можно изменить в конфиге (настройка cleanupPeriodDays).
Удобная тулза для поиска сессий во всех проектах сразу:
https://github.com/affaan-m/everything-claude-code
Чтоб посмотреть, что занимает контекст - наберите /context. Лучше всего отключать неиспользуемые MCP и плагины. Скиллы подгружаются лениво (по умолчанию только название и краткое описание), но, например, тулзы в MCP грузятся целиком.
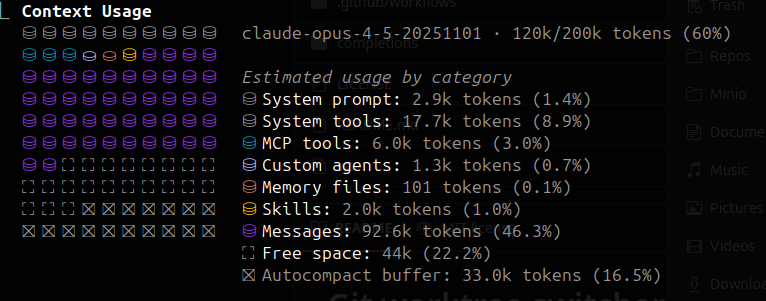
Полезные хоткеи:
- CTRL + U - стереть всю строчку
- Shift + Enter - новая строчка (сначала нужно запустить /terminal-setup). Если не работает, то печатаем бэкслэш \ и нажимаем Enter
Режимы работы
У CC есть три режима работы, которые переключаются по Shift+Tab:
- Дефолтный - спрашивает пользователя перед каждым действием в рамках текущих настроенных разрешений.
- /permissions - команда для установки разрешенных действий.
- Ещё можно покопаться в файле настроек или команде /config.
- Авто-аксепт всех изменений - YOLO-режим, уходим пить кофе и надеемся на чудо.
- Режим планирования - обсуждаем задачу и создаём маркдаун с описанием, пока не делаем никаких изменений.
Иногда CC решает войти в режим планирования самостоятельно.
Ещё можно поменять стиль ответов через команду /output-style:
- Дефолтный
- Объясняющий - более детально обосновывает свои решения
- Обучающий - не просто пишет код, а ещё и просит самому писать часть кода для улучшения понимания
Работа над фичей
Есть разные варианты, как стартовать работу над фичей:
- Просто описать в промпте, что вам надо - “поправь баг по этому трейсбеку”. Подходит для несложных задач.
- Создать md-файл (или несколько) с детальным описанием задачи - самому или в режиме планирования.
- Можно использовать скилл “Plan with files” (команда для добавления маркетплейса -
claude plugin marketplace add OthmanAdi/planning-with-files), тогда результатом планирования всегда будут три файла - декомпозированный план задачи, находки по ходу работы (очень полезно при переполнении контекста, чтоб не потерялись всякие детали) и текущий прогресс.
- Можно использовать скилл “Plan with files” (команда для добавления маркетплейса -
- Подключить Слак или MCP к инструменту, где у вас описаны задачи. В твиттере регулярно вижу истории, как люди чуть ли не из баг-трекера вызывают CC пофиксить проблему, но мы пока так не делаем, конечно.
Если нужно что-то показать агенту (например, как должен выглядеть будущий интерфейс), можно прям в терминал вставить картинку из буфера обмена. Ещё для взаимодействия с браузером можно подключить подобный плагин.
Одна из важнейших вещей - обязательно написать тесты на планируемую фичу и сразу рассказать Клоду, как эти тесты запускать. Либо должен быть какой-то иной способ провалидировать результаты работы - как самому агенту по ходу работы, так и вам. Можно работать в стиле TDD (сначала тесты, потом код), для этого даже есть специальные скиллы, либо можно писать тесты пост-фактум. Всё зависит от ситуации и предпочтений, главное, чтоб была возможность автоматически проверить результаты работы системы на корректность и на соответствие поставленной задаче (Definition-of-Done).
Для сложных задач ещё полезно сначала попросить CC изучить релевантные части кодовой базы, можно натравить его прям на нужные файлы через @. После этого уже приступаем к планированию и имплементации.
Не забывайте следить за ходом работы и останавливать агента, когда он творит фигню или ушёл в петлю сумасшествия. Можно представить, что это парное программирование. Хотя, если задача не очень важная, то можно и забить и просто проверить финальный результат. Но я предпочитаю всё равно послеживать за работой, чтоб токены не горели просто так. А ещё CC очень любит после нескольких неудачных попыток написать что-то типа “ну ладно, не выходит, тогда пока упростим архитектуру сетки, чтоб побыстрее приступить к первому прогону”. Даже строгие запреты в CLAUDE.md не всегда помогают.
В конце работы над фичей обязательно сделайте финальное ревью изменений, способы можно комбинировать:
- Традиционное ревью глазами через IDE или git diff
- Попросить его же перепроверить результаты своей работы, для этого есть даже специальные скиллы типа /code-review
- Открыть новую сессию и попросить сделать ревью. На вход можно кинуть описание задачи
Часто полезно сделать ревью несколько раз - за один прогон все проблемы не находятся. Ещё важный момент - иногда баги, которые он находит - это вообще не баги, поэтому лучше не доверять слепо, а въехать самому, что же и почему он предлагает исправить.
Ну и, конечно, не забываем соблюдать стандартные правила разработки, принятые в вашей команде.
Безопасность ключей и паролей
Обратите внимание, что CC может спокойно прочитать все ваши секретики из .env. Трагедия ли это, если он прочтёт? Наверное, в большинстве случаев нет, вряд ли сотрудники Антропика пойдут воровать ваши данные, но постоянно происходят всякие утечки, что-то в трейн-сет утечёт и так далее. Так что лучше обезопасить себя - например, защитить свой энв-файл от прочтения (статья раз, тред на реддите два, статья три) или вообще отказаться от плейн-текстовых энв-файлов. Выбирайте, какой путь вам больше нравится.
Как сделать, чтоб CC мог сам запускать реальные команды, которые требуют секретов?
Вариант 1 (небезопасный)
set -a && source .env && set +a && claude
И в CLAUDE.md пишем, чтобы агент ссылался на все секреты исключительно по имени переменной и не читал их значения. Стопроцентная ли это защита? Конечно, нет. CC может специально или случайно забить на наши инструкции и, например, сделать echo, или же значение попадёт в verbose-аутпут какой-нибудь bash-команды. Но как базовая защита - подойдёт.
Вариант 2
Использовать одноразовые ключи. Создали ключи, повайбкодили, удалили ключи и создали новые под прод.
Вариант 3
Либо сами запускаем любые команды, которые требуют секретов.
Скиллы
Скиллы - это что-то типа CLAUDE.md, но которые не забивают всегда контекст и подгружаются по необходимости. В скиллах описаны разные правила, как нужно решать ту или иную задачу.
Агент может сам выбрать использовать скилл (по названию и описанию) или можно ему прямо сказать “используй скилл дебаггинга” или вообще запустить скилл как команду “/debug”. Один из популярных скиллов - разные вариации на “/refactor-clean”, “/clean-slop” для рефакторинга и удаления лишнего кода и файлов после длинной сессии вайб-кодинга.
Всякие полезные скиллы в основном содержатся в плагинах, но можно создавать и свои скиллы - руками, через CC или с помощью скиллов из плагинов (например, continuous-learning из Everything Claude Code анализирует беседу и предлагает новые скиллы).
Субагенты
Иногда CC решает запустить субагента или несколько субагентов в параллель через инструмент Task. По дефолту доступно несколько видов агентов - General-Purpose, Explore, Plan и другие. Это нужно, чтоб не загрязнять контекст: субагент получает свежий нужный контекст от основного агента, а затем возвращает результаты работы основному агенту. Можно прямо просить CC запустить субагентов для следующей задачи.
Специализированные виды субагентов можно создавать вручную командой /agents. В том числе можно описать, что должен делать субагент просто словами. Например, я создал субагента для чтения ML-статей и опционально кода. На выходе генерируется маркдаун с описанием всех деталей, нужных для имплементации статьи или серии статей.
Каждому субагенту можно дать доступ к конкретному подмножеству скиллов, MCP, разрешений.
Хуки
Можно не полагаться на LLM, а настроить автоматические действия по триггеру. Например, каждый раз, когда CC коммитит файл, происходит автоматический пуш в ремоут. Или после каждого редактирования файла прогоняется линтер. Типы хуков:
- PreToolUse - перед запуском инструмента
- PostToolUse - после использования инструмента
- UserPromptSubmit - после отправки пользователем сообщения
- Stop - после окончания написания ответа пользователю
- PreCompact - перед автоматическим или ручным сжатием контекста
- Notification - перед запросом разрешения на действия
Есть плагин Hookify, который позволяет автоматически на основе анализа беседы или вручную создавать хуки, которые помогают предотвратить всякое нежелательное поведение агента.

MCP
MCP позволяют дать доступ CC ко всяким внешним тулзам. Очень важно - обязательно убедитесь, что даёте рид-доступ. К сожалению, отключение конкретных инструментов почему-то пока не реализовано. Иначе можете случайно остаться без БД или прод-кластера.
Полезные MCP, которые я часто использую:
- Postgres к различным БД с read-доступом
- Kubernetes - для чтения продовых логов
- ClearML - для чтения логов и конфигов экспов
Альтернативно можно настроить cli до нужных инструментов и в CLAUDE.md описать, как ими пользоваться. Но тоже стоит быть осторожными с разрешениями.
Плагины
Плагины - это такие курируемые сборки скиллов, хуков, субагентов и MCP. Умные люди (или не очень) собрали их за вас, чтоб СС и вы могли их использовать.
Некоторые полезные плагины:
- Context7 - чтоб не настраивать самому MCP, доступ к документации библиотек
- https://github.com/obra/superpowers - сборник полезных скиллов для воркфлоу разработки (брейнсторм, планирование, имплементация, TDD, код-ревью и многое другое)
- https://github.com/affaan-m/everything-claude-code - большой сборник разных полезностей, требует настройки под себя и отключения лишнего
- Playground - свежий плагин от Anthropic, который позволяет CC генерировать интерактивные HTML под разные задачи
Работа над несколькими фичами в параллель
Вообще я пока с опасением пускаюсь в такие авантюры, особенно на сложных прод-проектах: уж лучше несколько несвязанных задач из разных проектов решать. Но многие параллельщики используют воркфлоу с git worktree. Есть даже всякие специальные инструменты для облегчения жизни:
- GUI для управления несколькими агентами - Conductor (только мак), opcode, Crystal, air.dev (только мак)
- Тулзы для удобной работы с worktree
Я попробовал Crystal - мне больше в терминале нравится работать, колхозно как-то.
Но есть у меня и частый параллельный кейс - работаешь над фичей в ветке, и внезапно нужно срочно пофиксить баг в релизной ветке. Вместо stash/checkout можно использовать worktree:
# 1. Создать worktree для багфикса (из основного проекта)
cd /path/to/project
git worktree add ../out-of-memory releases/v0.22.1b
# 2. Перейти и запустить Claude
cd ../out-of-memory
claude
После завершения фикса:
# Вернуться в основной проект
cd /path/to/project
# Удалить worktree
git worktree remove ../out-of-memory
Работа с CC в IDE
Есть плагины для популярных IDE(VSCode, PyCharm). Они позволяют удобно изучать изменения которые сделал агент прямо в IDE. Взаимодействие с CC идет стандартно через встроенный в плагин терминал.
Ещё один вариант (я его сейчас иногда использую) - скачать Zed, симпатичный IDE с нативной интеграцией с CC через ACP.
Что ещё почитать
- Детальный свежий гайд
- Безумный пайплайн создателя Claude Code
- Как CC пользуются в Anthropic
- Официальная документация
- The Longform Guide to Everything Claude Code
Примеры из жизни
Это всё, конечно, очень хорошо, но всегда сильные и слабые стороны инструмента лучше раскрываются через реальные примеры.
Пример 1. Фича для Маттермоста
Задача - сделать так, чтоб командой из Маттермоста можно было запускать и стопать демо-стенд (5 машин в Яндекс-облаке). Сначала я сам сел и подумал, какие есть варианты, исходя из нашей текущей инфраструктуры. Решил остановиться на n8n, но стало лень самому разбираться в том, какие запросы надо отправлять в API Яндекс-облака и как парсить хуки из Маттермоста.
Фаза 1 - Брейнсторминг
Я описал задачу просто текстом и попросил вместе со мной побрейнстормить и задать уточняющие вопросы. Он заюзал скилл Brainstorming из Superpowers и стал задавать мне вопросы по одному:
- какие машины надо стопать - фиксированный список или динамический
- предпочитаемый формат команд
- настроена ли уже аутентификация в Яндексе (нет)
- что это за машины, сколько их, включаем и выключаем все сразу или нет
- нужна ли команда статуса
- как и куда будем писать ответ в ММ - я знал, что слэш-команды не умеют отвечать в тред + хотел ограничить их место действия одним каналом, поэтому выбрал отдельным сообщением в этот специальный канал
Вывод: можно описать CC задачу и, если нет подробной спецификации, попросить его позадавать уточняющие вопросы.
Фаза 2 - Изучение инфры
Я попросил CC прочитать .env, куда я засунул ключ от n8n (нестрашно, так как он за VPN + могу потом перегенерить). Дальше он сделал curl к API n8n, получил список существующих пайплайнов, изучил их содержимое и как выстроена работа с Маттермостом. По ходу пришлось его немного корректировать, пытался стучаться не совсем туда.
Фаза 3 - Дизайн архитектуры
CC по частям начал выдавать дизайн архитектуры, подтверждая у меня, что всё верно. Также запросил дополнительную информацию (JSON-ключ для запроса токена в Яндекс-облаке, айдишники машин).
Фаза 4 - Имплементация
CC написал JSON с описанием n8n-воркфлоу и через curl POST-запросы попытался создать его. Были какие-то ошибки импорта, и CC явно упёрся в стенку, повторяя примерно одно и то же разными способами. Я его стопнул и предложил самому импортнуть JSON через браузер. Так получилось намного быстрее и сразу заработало.
Вывод: желательно послеживать за агентом во время фазы имплементации.
Фаза 5 - Отладка
Естественно, с первого раза ничего не заработало: воркфлоу падал на этапе генерации JWT с ошибкой “Module crypto is disallowed”. CC предположил, что нужно поменять настройки n8n. Опять же, я сам погуглил документацию - так часто быстрее, хотя можно было попросить и агента. Попросил девопса прокинуть энв-переменную в контейнер n8n, и всё завелось!
Вывод: отладку часто лучше делать совместно, особенно если у CC нет полностью самостоятельного способа проверить результаты своей работы и исправить их.
Пример 2. Реализация DL-статьи
Задача - изучить новую архитектуру из DL-статьи, а затем реализовать в коде.
Фаза 1 - Планирование
Изначально я попросил CC изучил статью и составить план её имплементации. Но после изучения нашей кодовой базы было предложено вместо этого адаптировать основные идеи из статьи под текущую архитектуру. Он объяснил это тем, что в статье решается задача сегментации, а у нас детекции, и придётся сильно менять архитектуру. Я согласился - меньше изменений, более компактная по памяти архитектура. Я отдельно попросил задизайнить изменения так, чтоб можно было по максимуму инициализировать сеть текущим лучшим чекпойнтом.
После этого был создан план реализации статьи (точнее уже даже некой идеи по мотивам статьи) по шагам. Я его попросил выгрузить в md-файл, прочитал и мне показалось, что некоторые штуки из статьи адаптированы некорректно. Поэтому я отдельно закинул отдельно три скриншота архитектуры из статьи - по ним лучше понятные технические детали, чем по тексту (кода к статье не приложено). По картинкам план был адаптирован.
Фаза 2 - Итеративная реализация по шагам
Реализация шла файл за файлам: после каждого шага я задавал уточняющие вопросы и просил проверить корректность реализации лишний раз. Для проверки CC использовал в том числе баш-команды, проверял, что код корректно импортируется и выполняется.
В процессе приходилось останавливать его пару раз - зачем-то стал писать TODO вместо реальной реализации и поставил no_grad на новый архитектурный компонент, чтоб сэкономить память, хотя это противоречило изначальному плану.
Фаза 3 - Ревью
Далее я попросил CC сделать ревью написанного кода - он заюзал субагента /code_reviewer из плагина Superpowers. Нашёл пару багов, я ещё раз попросил - нашёл ещё пару багов. На третий раз всё оказалось чисто (ага, конечно).
Фаза 4 - Отладка
Я попросил его использовать MCP ClearML, чтоб прочитать параметры успешного эксперимента и локально поставить эксп для проверки с похожими параметрами и маленьким размером входной картинки.
Работающий код в ML ничего не значит, поэтому я решил отдельно визуализировать работу каждого компонента - начал с алгоритма регистрации медицинских изображений. Естественно, оказалось, что ничего не работает, поэтому за этим последовала долгая сессия совместной отладки. Вывод тут один - как и в работе без ИИ всегда смотрите на данные, на входы и выходы нейронки. CC ещё и ускоряет процесс, так как быстро создаёт любые нужные визуализации. Можно просить CC тоже смотреть на сгенерённые картинки, но у него это пока получается довольно посредственно. Лучше смотреть самому и писать свои выводы, либо по крайней мере скидывать в чате именно ту часть картинки, на которую нужно обратить внимание, иначе он начинает много выдумывать.
Заключение
Если честно, я впечатлён. Понятно, у меня очень субъективное мнение, задачи сильно отличаются от ML-инженеров и разработчиков в командах, но мне CC помогает сейчас по очень многим вопросам, не только кодерским (вчера с ним новый мак выбирал). В ChatGPT я сейчас захожу в основном модифицировать под себя какие-то рецепты на ужин (healthy-буррито с баффалой-курочкой получился изумительным). Из минусов - подписки за 20 долларов не хватает, надо брать сразу за 100. Или не гонять всё подряд через Opus, как я, а переключаться на него по необходимости.