Использование ИИ-агентов для ML-экспериментов
Использование ИИ-агентов для ML-экспериментов
На днях Andrej Karpathy выложил новый репозиторий - autoresearch. ИИ-агент пытается улучшить метрики обучения небольшой языковой модели. За два дня агент нашёл около 20 улучшений, которые позволили получить реальный прирост в скорости обучения - можно натренировать модель качества GPT-2 за 1.80 часов на кластере 8xH100.
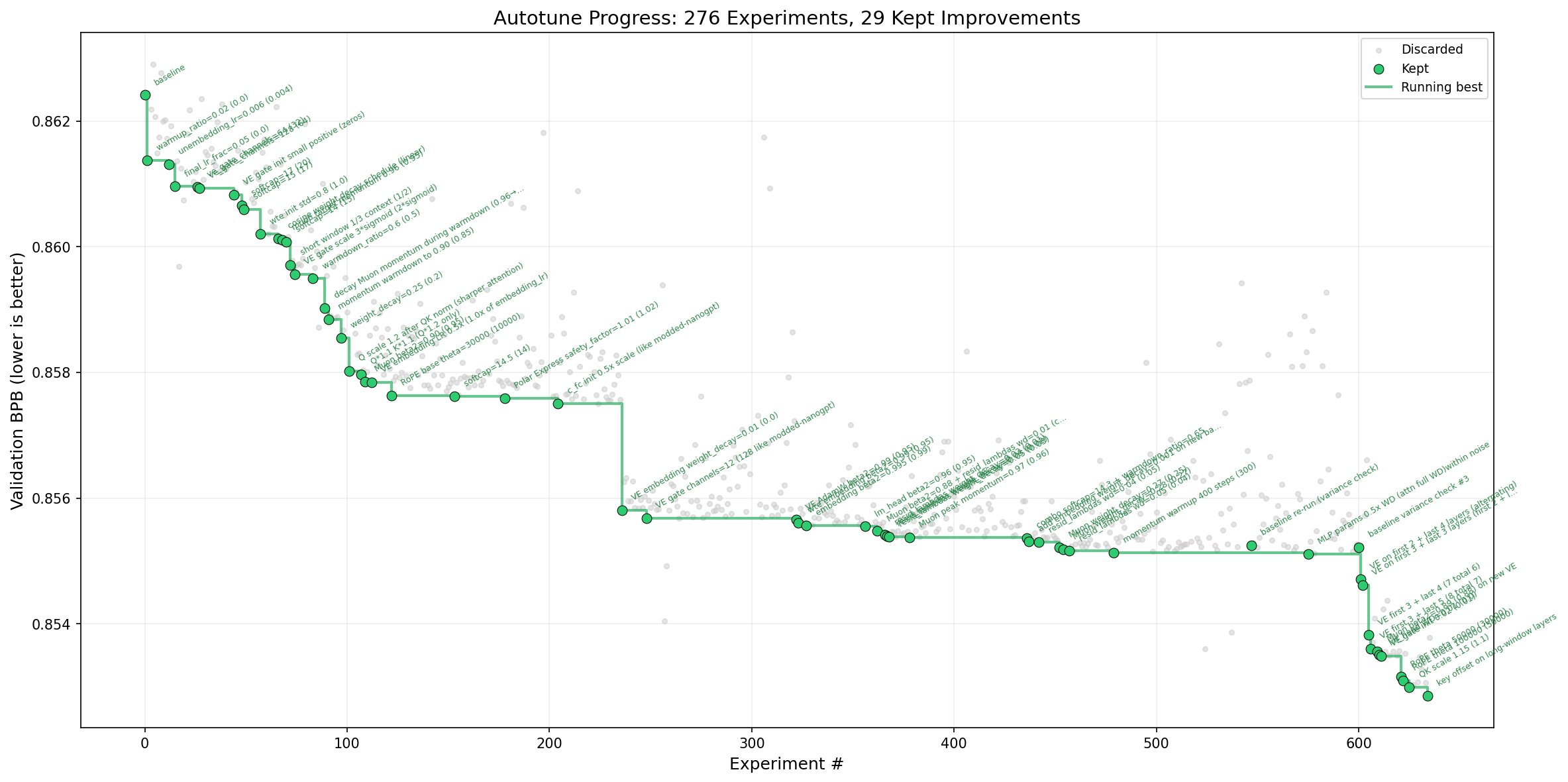
Многие сравнивают такой процесс просто с тюнингом гиперпараметров, AutoML или Neural Architecture Search, потому что никаких рисёч-прорывов агент не сделал - просто модифицировал понемножку существующий проект.
Мне кажется, что это всё-таки некоторое преуменьшение, даже на текущем этапе ИИ-агенты предоставляют несколько другой уровень автономности процесса. Агент сам читает код, анализирует результаты экспериментов, предлагает новые гиперпараметры для тюнинга и архитектурные изменения. Так что, MLщики тоже останутся без работы? Давайте посмотрим на наш опыт использования Claude Code для ML-рисёча в Цельсе, покажу три уровня автономности - агент-аналитик, агент-исполнитель, агент-рисёчер.
Анализ результатов экспериментов
Мы активно используем Claude Code для анализа результатов экспериментов. Например, на выходных у меня всё никак не сходилась новая архитектура - в самом конце первой эпохе был взрыв градиентов.
Claude Code, имея доступ к репозиторию, ClearML и чекпойнтам, предложил несколько возможных решений и приоритизировал их. Получилось неидеально - сработало третье по счёту решение, но тем не менее результат был достигнут. Возможно, я бы и сам сообразил, что к чему, но на самом деле штука была не самая очевидная - только два архитектурных изменения вместе приводили к взрыву, а каждое по отдельности - нет.
Ещё агенты могут хорошо анализировать чекпойнты на предмет инсайтов. Скажем, добавили мы какой-то новый модуль в нашу архитектуру и хотим понять, а учится ли он вообще согласно нашим ожиданиям? Агент может в момент сгенерировать скрипт для проверки гипотез, визуализации весов и активаций и всё такое прочее. Правда, интерпретация результатов такого анализа не всегда верная, особенно если у агента нет нужного скрытого контекста о работе модели и предыдущих экспериментах.
Наконец, ещё одна полезная история - суммаризация серии экспериментов. Мы можем натравить Claude Code на целую пачку экспериментов и попросить сделать выжимку для команды - что сработало, что нет, какие есть гипотезы по дальнейшей работе. Например, в Sionic AI вообще выстроили этот процесс вокруг Claude Code:
- Команда /retrospective изучает сессию с обсуждением эксперимента, извлекает полезные выводы и складывает их в новый скилл-файл, который комитится в общий репозиторий
- Команда /advise изучает этот накопленный реестр и советует, что изменить в текущем эксперименте, исходя из накопленных знаний
Какие есть плюсы и недостатки у использования ИИ-агентов для такой аналитики?
Плюсы:
- ИИ-агент без проблем понимает разницу между большой группой экспериментов - может быстро прочитать гиперпараметры, диффы на целой группе экспериментов, понять, чем они отличаются, что могло стать скрытой причиной провала эксперимента
- Может сгенерить большее количество гипотез “из головы” или погуглить статьи, изучить и учесть накопленный опыт команды
Недостатки и потенциальные решения:
- Агента очень легко сбить с толку. Скажем, он доказывает тебе правильность предложенного решения, ты начинаешь сомневаться или спорить, и он сразу же сдаётся. Что можно сделать?
- Давать решение на ревью субагенту (желательно в настройках Claude Code выставить CLAUDE_CODE_SUBAGENT_MODEL, чтобы он использовал Opus). У субагента нет лишнего контекста и истории вашей дискуссии, он пытается оценить решение условно “объективно”
- Вместе с агентом придумать, как можно быстро верифицировать правильность решения (или хотя бы отсутствие явных ошибок). Например, если мы решаем проблему плохого или нулевого обучения модуля сетки, то можно быстро накидать одноразовый тестовый скриптик на сабсете реальных данных
- ИИ-агенты очень любят сами себе засрать контекст за 1-2 команды. Например, прочитать разом из ClearML огромный JSON с метриками, в котором в том числе каждые 10 батчей логируется лосс, потребление GPU и так далее. Потенциальные решения:
- Чтоб спасти текущую сессию - сделать /rewind на предыдущую команду и попросить прочитать только нужные метрики
- Сделать скилл по работе с ClearML, который объясняет, как правильно работать с экспериментами через SDK
- Иногда предлагает очевидно нерабочие, либо уже испробованные им самим ранее или людьми решения. Возможные решения:
- Перероверять идеи руками и субагентами, просить описать их как можно подробнее текстом и схемами
- Подключить агента к “банку памяти” - например, реестру экспериментов в Notion или упомянутой выше библиотеке командных скиллов
- По моему опыту Claude Code довольно паршиво интерпретирует дебаг-картинки (например, с предиктами), а для нашей области это очень важно. Например, он уверял меня, что модель верно детектировала сосок, хотя по факту коробка была нарисована посреди молочной железы. Тут я пока нашёл такие способы - (а) смотреть самому и (б) просить его придумать альтернативные методы анализа, которые не требуют визуального понимания
Статья -> код
Ещё один традиционный “хлеб” ML-инженеров - имплементация статей. Даже если к статье приложен репозиторий, возможные различные проблемы:
- Расхождения между статьёй и кодом
- Часть кода отсутствует
- Код не запускается
- В существующий проект невозможно напрямую утащить архитектуру из статьи
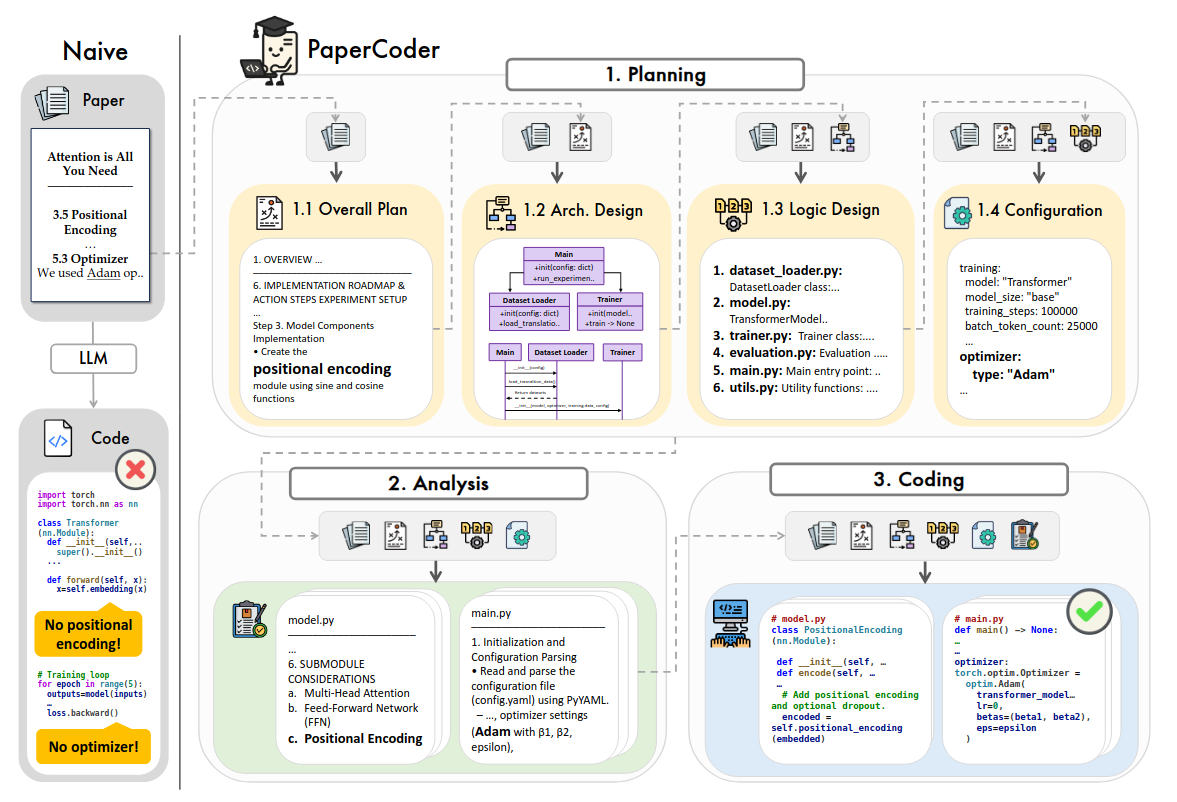
В худшем случае у вас на руках будет только статья и картинки из неё. Так или иначе, ИИ-агенты очень хорошо могут помочь имплементировать идеи из статей и адаптировать их к существующим архитектурам. Из рекомендаций - кроме ссылки на файл статьи полезно прикладывать отдельно важные схемы, ведь иногда в тексте нет деталей имплементации, а в схеме - есть. Ещё лучше - сначала попросить описать архитектуру по картинке текстом (я часто делаю через ChatGPT в браузере), исправить неточности вручную, и затем это описание скормить ИИ-агенту вместе со статьёй.
Есть даже специальные фрейморвки типа Paper2Code, которые раскладывают генерацию статьи на логичные этапы, которым следовал бы человек. Таким образом, пропускается значительное меньшее количество важных для воспроизводимости деталей.
Автоматические эксперименты
Наконец, есть самое футуристичный способ использования в стиле autoresearch - запускаем ИИ-агента либо в полностью автономный луп а-ля Ральф, либо в интерактивный луп с обсуждением промежуточных результатов.
Недавно мой коллега Коля Филатов (спасибо ему огромное за подробный отчёт по его эксперименту) попробовал такой автономный луп на подходящей задаче. Чем именно она подходила?
- Возможность написать метрик-тест, который измерит качество результата за 10-15 минут
- Доступ до ClearML, чтоб отслеживать прогресс и результаты метрик-тестов
- Мы улучшаем маленькую часть большого ИИ-сервиса, которая не требует длительного обучения. В нашем случае - алгоритм выбора нужного среза на основе уже сегментированных масок
- Опционально - имеется изначальный список гипотез на проверку, от которых можно отталкиваться, и список уже проверенных и отвергнутых гипотез
При этом даже в такой ограниченной задаче были затупы - например, агент начал тестить гипотезы, метрики получались точно такие же, но он не стал проверять код алгоритма или метрик-теста. Пришлось вручную его стопнуть, попросить всё перепроверить, и только после этого агент проверил данные и код, нашёл и исправил ошибку и полетел дальше тестить гипотезы. Дополнительно пришлось в какой-то момент напомнить агенту, что нужно ещё следить за быстродействие и потреблением памяти. В идеале нужно было бы ему эти ограничения поставить при формулировании задачи, но не всегда всё можно учесть. Человек бы быстро понял, что алгоритм существенно замедлился и пошёл бы уточнять, ок ли это, тут такого не произошло. Итоговый результат - буст метрик случился, результат нормальный, но выдающийся.
Коля по итогу сделал казалось бы простой, но очень важный вывод - для автономного агента ещё важнее становятся вещи, которые бы навредили и “автономному человеку”:
- Качество документации - ошибки и пробелы в документации могут замедлить или вообще остановить прогресс агента
- Проблемы в данных и разметке - например, в нашем экспе неконсистентный матчинг данных и разметки поставил агента в тупик
- Точная постановка задачи и все критерии её выполнения - без этого агент может предлагать решения, не соответствующие реальным потребностям
- Отсутствие скрытых багов в существующем коде - классика жанра, люди и агенты склонны предполагать, что существующий код работает корректно. Это не всегда так…
- Безопасность - нужно найти правильный баланс между безопасностью и пространством для экспериментов
По мотивам autoresearch уже стали появляться продвинутые проекты типа Helios, заточенные под ML-задачи.
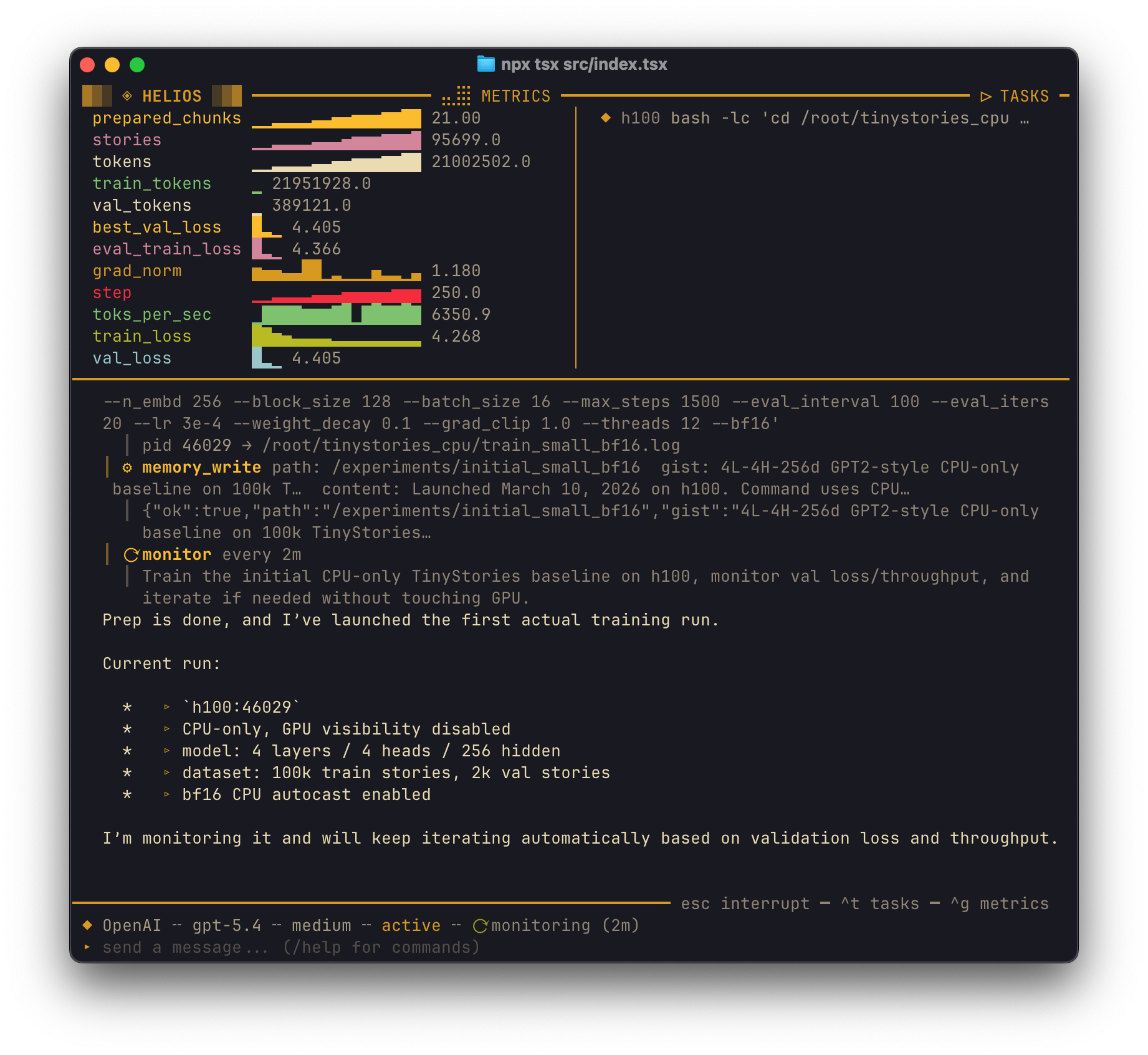
Заключение
Всё-таки мне кажется, что ML-задачи ИИ-агенты пока решают похуже, чаще тупят, иногда “интуитивно” не чувствуют нужное направление движения. Скажем, GPT-5.4-thinking по данным OpenAI может взять бронзу только в 23% из 30 отобранных Kaggle-соревнований. Причём это небольшие по объёму и длительности соревы. Но процесс ML-разработки - от брейнсторминга до оптимизации инференса - без них себе представить уже невозможно. Если же хотите попробовать автонмных агентов, то подберите задачу, где можно быстро и автоматически верифицировать результат работы.