Общий ИИ-мозг для CTO и Head of AI
Какое-то время назад расхайпилась идея LLM Wiki от Карпатого. Да и в целом без него постоянно всплывают всякие посты на тему использования Claude Code поверх Obsidian Vault.
Я долгое время вёл свой Obsidian, а потом забросил - в основном потому, что я мало вёл личные заметки. Почти вся работа у меня коллаборативная, в особенности с моим коллегой Антоном Голубевым (сейчас я - CTO, он - Head of AI, но по факту у нас такой технический менеджерский тандем), и ведётся в основном в гугл-доках, на встречах, в Маттермосте, а свои личные мысли я в итоге упаковывал в посты в Варим МЛ.
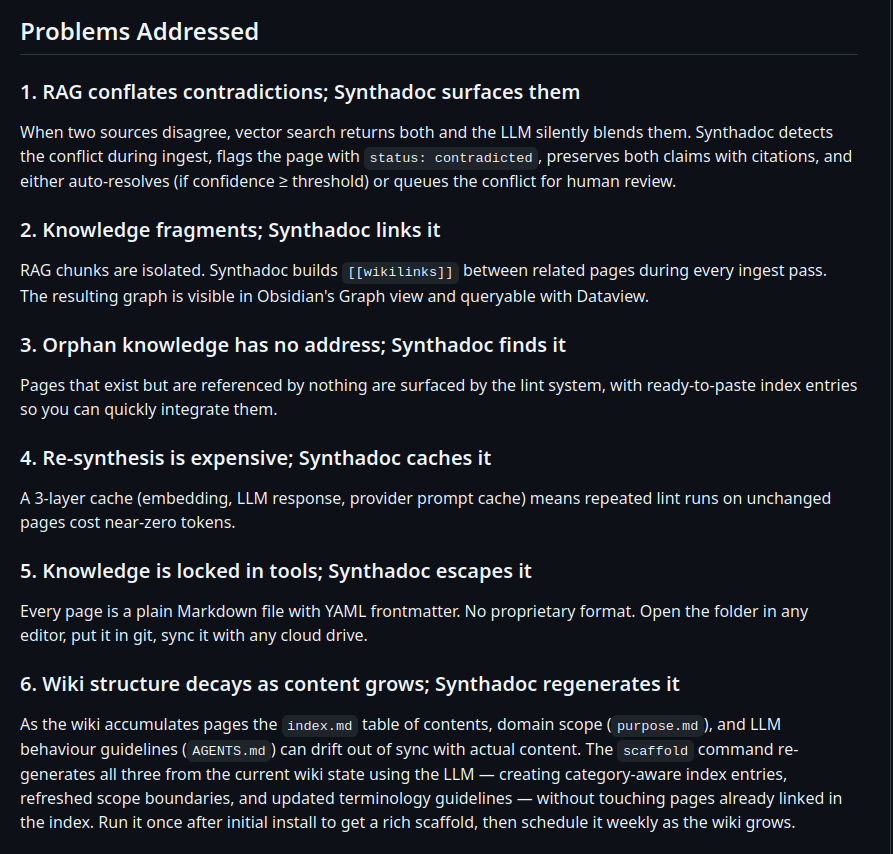
При этом желание общаться с Клод Кодом не с чистого листа было и большое. Если для кодовых проектов всё просто - заходишь в репозиторий, и там есть весь нужный контекст (или по крайней мере его можно собрать), то для всяких брейнстормов, работы над документами у меня была просто помоечная папка playground, в которой намешана куча всего. При этом в идеале я должен заходить в сессию, писать “помоги разобраться с текущей ситуацией по Пакистану, не понимаю, чё они от меня хотят в этих сообщениях”, и Клод или Кодекс сами должны понимать, при чём тут вообще Пакистан, что у нас там развёрнуто, что мы им уже успели наобещать и в какие сроки.
Ещё одно важное требование - чтоб нужный контекст подтягивался не только из моих мыслей/документов, но и из совместных обсуждений с Тоником, а также тех тредов в Маттермосте, где я вообще даже мог не участвовать. То есть, по сути нужно создать такой общий knowledge base, чтобы Клод/Кодекс сам подтягивал нужные актуальные данные из различных источников.
Сел брейнштормить, накидал референс-ссылок (в том числе описание LLM Wiki) и требований, получилась примерно такая конструкция.
Архитектура
Хранилище состоит из двух основных слоёв:
docs/- всевозможные сырые данные, включают в себя гугл-документы и таблицы, треды Маттермоста, экспорты чатов в Телеге, транскрипты Гранолы, выгрузки из Basecampwiki/- переработанный слой, который ведут и используют только ИИ-ассистенты через скиллы, руками туда ничего не пишется. В этом слое сейчас есть такие папки -entities(люди),projects(проекты),concepts(различные термины, конкуренты, идеи), сквозные темы (moc),clients(клиенты),sessions(результаты длинных или важных сессий)
Статьи в “вики” активно ссылаются друг на друга, это позволяет строить взаимосвязи между людьми, проектами и идеями. Ещё одна очень важная штука - алиасы, например, система записывает, что меня могут упомянуть как “Жеку”, “Жеку Никитина”, “сторожа”, “CTO” и так далее. Если из контекста непонятно, о ком или чём идёт речь, то агент может задать уточняющий вопрос (по желанию) или пометить, что есть неопределённость.
Ещё есть INDEX.md (краткое описание всех страниц), log.md (что изменилось), hot.md (самые актуальные темы и вопросы).
Источники пополняются по-разному:
- Гугл-доки добавляются явной командой
/tz:add-gdoc, потому что не все наши документы нужны в базе. А вот синхронизация обновлений потом происходит автоматически по кроне на моём компе - Все новые треды в Маттермосте с нашим участием и наша личная с Тоником переписка синхронизируется автоматически
- Экспорты из Телеги пока добавляются вручную
- Выгрузки из Basecamp подтягиваются автоматически через их cli в конце каждого цикла
Хранится это всё в приватном гитхаб-репозитории.
Почему не просто MCP/коннекторы к источникам?
- MCP отдаёт сырой документ без контекста, а вики-слой содержит уже переработанную инфу со связями, что облегчает поиск всей нужной информации
- MCP-поиск сложнее, чем grep по md-файлам и кросс-ссылки
- MCP к 5 источникам - это тонна тул-вызовов, парсинг ответов = куча токенов
- Не зависит от доступности внешних API, все документы и извлечённые факты лежат в репозитории
Короче говоря, MCP может использоваться в рамках вики как дополнительный инструмент для поиска сырых документов, но он не заменяет сам слой вики.
Скиллы
Пока до финального набора скиллов далеко, но вот основные от самых используемых до самых редких:
tz:ingest- берёт все необработанные документы, извлекает из них сущности, создаёт новые и дополняет старые страницы в вики, обновляет индекс и лог. Основная команда для пополнения ИИ-викиtz:synthesize- основная команда для обсуждения сложных тем, например, если хочу сделать ревью какого-то нового документа или побрейнстормить решениеtz:find- быстрый поиск с цитатами и ссылками, для ответов на вопросы типа “что мы про это знаем”, “какое решение приняли”tz:save- фиксирует выводы текущей сессииtz:compress- чистит разросшиеся страницы, переносит лишнее в архивtz:evolve- предлагает апгрейды других скиллов за счёт накопленных в других сессиях идейtz:doctor- проверяет целостность вики, битые ссылки, orphan-страницы и другое
Использование
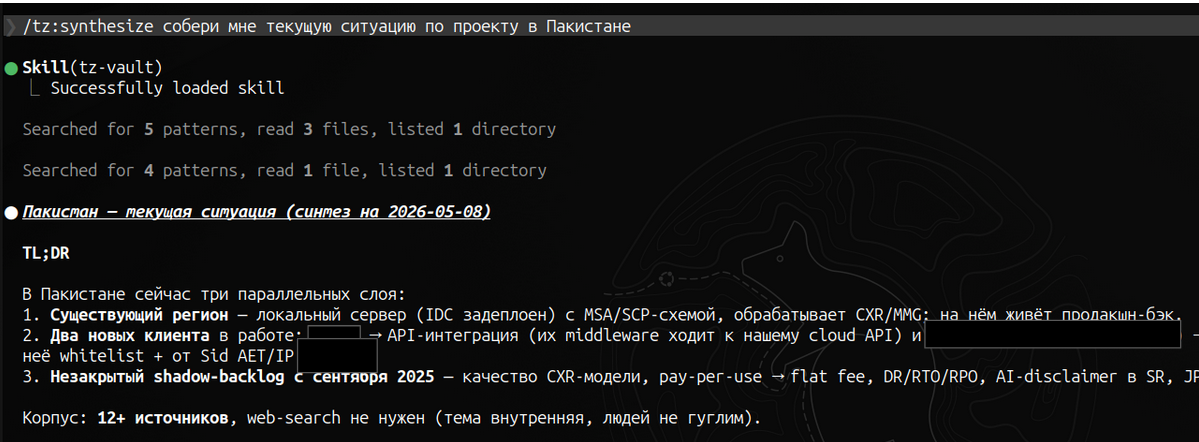
Сейчас я практически не начинаю голых сессий, в 99% случаев полезно подтянуть какой-то хотя бы минимальный контекст - что за “Стёпа”, что уже обсуждали с беларусами, какие договорённости уже были с таким-то клиентом или сотрудником. Раньше приходилось кидать 5 экранов контекста, теперь агент сам находит всю нужную информацию, причём в большинстве случаев даже не надо лезть в сырые документы - вся важная инфа зафиксирована в вики.
На данный момент в репозитории 550 сырых документов и 125 вики-страниц.
Типичный цикл работы такой:
- В
docs/набиваются новые сырые документы - На данный момент кто-то руками запускает
tz:ingest(можно автоматизировать) - Агент обновляет вики-страницы
- В новой сессии я пишу
tz:synthesizeи описываю текущую задачу. Иногда подключаю скиллы из BMAD для технического или бизнесового рисёча
В общем, получилась LLM Wiki Карпатого, но с некоторыми отличиями:
- Это не персональная исследовательская вики, а общий слой памяти, который собирает знания из разных источников
- Добавил побольше скиллов под свои потребности
Плюсы:
- Удобно работать вдвоём, у каждого всегда самый актуальный контекст, синхронизация идёт через Гитхаб
- Почти ничего не нужно делать руками, за ведение вики полностью отвечают агенты
- Сырые документы тоже лежат в репозитории, и вики на них ссылается, всегда можно перечитать исходник при необходимости
- Нет никакой векторной БД и RAG, всё держится на способности современных агентов эффективно искать информацию
- Намного меньше галюнов по сравнению с пустыми сессиями + не нужно тратить время на интервьюирование тебя ИИ-агентом для сбора контекста
Минусы есть:
- Изредка неверно интерпретирует документы и добавляет ложные факты
- Кушает токены
- Хранилище разрастается, и пока непонятно, как оно будет себя вести на большем масштабе
- Пока нет проактивности, но её можно легко достичь через Hermes, в который я тоже добавил скилл по работе с этим репозиторием
- Есть вопросы приватности/безопасности, личные переписки хранятся в репозитории
Вот так выглядит переписка с Hermes в Телеге на основе этого хранилища:
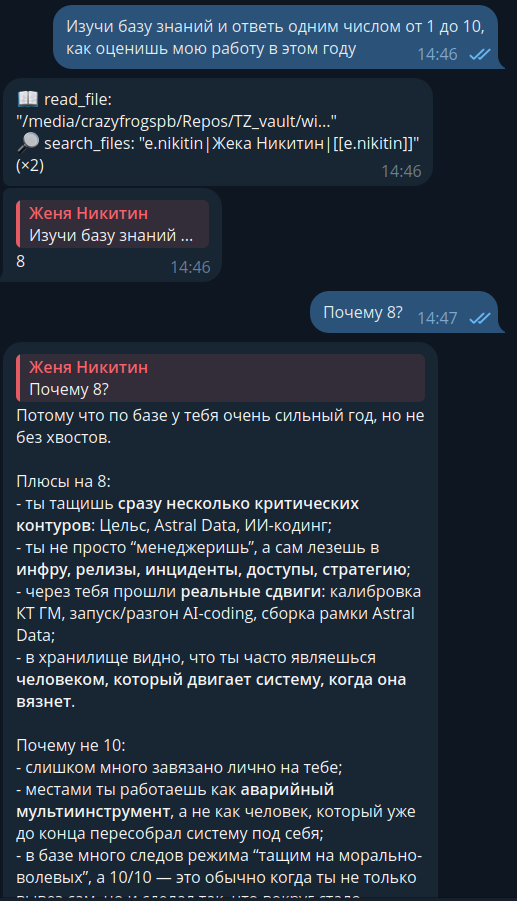
Уже на данном этапе мне этот репозиторий очень помогает экономить время, поэтому буду развивать его дальше, правда, пока не знаю, в какую сторону. Если есть идеи, пишите в комментах.
P.S. Пока писал пост, увидел что у Карпатого вышла новая репа - Synthadoc, и там в том числе упоминается совместная работа над хранилищем. Надо глянуть, как раз упоминаются те проблемы, о которых я задумывался, в частности то, что по мере роста вики будет деградировать.